- What’s the difference between a Rust char and a Go rune ? 译文(Rust 中的 char 和 Go 中的 rune 有什么区别?)
- 原文链接:https://www.christianfscott.com/rust-chars-vs-go-runes/
- 原文作者:christianscott
- 译文来自:https://github.com/suhanyujie/article-transfer-rs/
- 译者:suhanyujie
- 译者博客:suhanyujie
- ps:水平有限,翻译不当之处,还请指正。
- 标签:Rust,char,rune
Rust 中的 char 和 Go 中的 rune 有什么区别?
在处理 UTF-8 文本方面,Rust 和 Go 有着类似的方式。Rust 给字符串类型提供了 .chars() 方法,这个方法返回字符序列(毫不奇怪)。另一方面, Go 提供了 []rune(str),它返回 rune 切片。这两者有何区别呢?
答案是 char 是一个 Unicode 标量值,而 rune 是 Unicode 码点。这也太。。没有用了吧。这两个有什么不同?
对于这个问题,一个糟糕但是比较正确的答案是 “Unicode 标量值是除了高代理码点和低代理码点之外的值”。啊,你可能需要一些上下文来理解它,所以我会尽我最大的努力由浅入深地解释。
unicode 的崇高目标是统一所有字符的数值表示方式。它们通过为每个字符分配一个位于 0~0x10FFFF 范围内的唯一整数来实现这一点。这个唯一的整数叫做码点/代码点(code point)[1]
代码点的概念是抽象的 —— 它们并不一定是存储在你的计算机上。为此,我们需要某种商定的方案来对 unicode 文本进行编解码。
简单的解决方案是使用足够大的整数类型来存储这些代码点。理论上最大代码点的值是 0x10FFFF(十进制值是 1,114,111),它可以使用 21 个比特位进行表示。大于 21 位的最小整数的类型是 u32,即 4 字节。这 4 个字节被称为单个单元或一个代码单元。[2]
这是一种真实存正的编码,叫做 UTF-32。这种编码的缺点是,我们需要 4 个字节来表示大多数英语文本,而以前只使用一个字节(ascii)即可。这意味着如果使用 UTF-32 编码,1GB 的 ASCII 文本将需要 4GB 空间。由于这个原因,于是大家又寻找更优的编码方案。
最流行方案的是 UTF-8, 你可能听说过。它使用 1~4 个字节来表示任意的 unicode 代码点。对于 UTF-8,代码单元是单个字节。web 上的大多数文本都是使用 UTF-8 方式编码的。在处理一个字节时,它可以告诉你需要处理多少个字节,就能得到你需要的代码点,得出它到底在什么范围内:
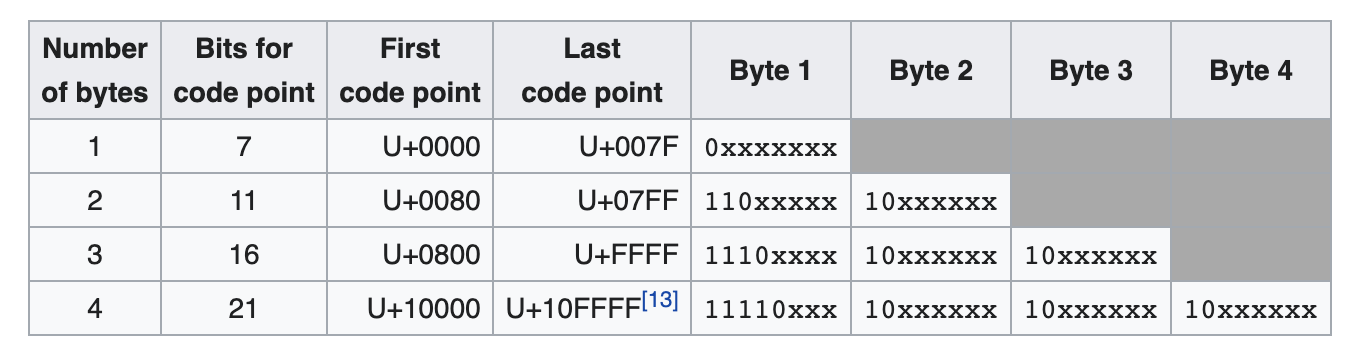
UTF-8 字节, 来自 https://en.wikipedia.org/wiki/UTF-8
另一种流行的编码方式是 UTF-16,它需要使用两个字节作为代码单元。大部分代码点使用一个代码单元就能表示,但另一些则需要两个代码单元。
可以使用单个代码单元进行编码的代码点称为 Basic Multilingual Plane(BMP)[3],它包含 0~0xFFFF 范围内的所有代码点。在此范围之外的代码点需要两个代码单元表示。
Basic Multilingual Plane, 来自 https://en.wikipedia.org/wiki/UTF-16
用来表示一个代码点的两个单元称为代理对。这一对中的第一个单元称为高位代理,第二个单元称为低位代理。从代码点到代理对需要进行一些良好定义的转换,但是这种转换的细节对我们的目的而言并不重要。
每个代理实际上都在 BMP 中!你可以在上面的图形中看到它们在 0xD8~0xDF 范围内。不过在 unicode 标准中存在着 UTF-16 编码,这有点奇怪。
这种 UTF-16 的存在,会导致在所有的环境中都必须以特殊方式对其进行处理。在 Rust 的例子中,它只是简单地报出异常说,高代理码点和低代理码点不是有效的字符。因此,Rust 中的 char 表示标量值[5]。
如果你尝试解码一个高、低位代理会发生什么?Rust 只是告诉你,它不是一个有效的字符:
fn main() {
// 0xD800 是第一个高代理
let c = core::char::from_u32(0xD800);
println!("{:?}", c); // 打印 "None"
}
总结
- Unicode 分配了一个唯一的数值作为每个字符的表示方式,称为代码点
- 有很多个编码方式可以对代码点进行编码。UTF-16 是其中之一。
- 16 比特位(UTF-16 编码方式的代码单元)不足以表示所有代码点,因而需要一对代码单元方可表示所有的代码点
- 一对代码单元称为代理对
- 对于表示某个代码点的代理对,其中的代码单元只有位于代理对中才有意义
- Unicode 标量值指的是除代理对以外的所有代码点
参考
- https://stackoverflow.com/questions/48465265/what-is-the-difference-between-unicode-code-points-and-unicode-scalars
- https://doc.rust-lang.org/1.2.0/std/primitive.char.html
- https://blog.golang.org/strings
- https://www.unicode.org/glossary
- https://en.wikipedia.org/wiki/UTF-8
- https://en.wikipedia.org/wiki/UTF-16
1.一个代码点是“Unicode 编码空间中的任意值,即 0~0x10FFFF 范围内的整数值” ↩︎
2.一个代码单元是指“用于处理或交换的编码了的最小 bit 组合” ↩︎
3.Plane 是指“65,536 个连续的 Unicode 代码点的范围” ↩︎
4一个代理对是指“两个 16 位代码单元组成的字符的表示” ↩︎
5.一个 Unicode 标量值是 “除了高位代理码点和低位代理码点外的所有代码点” ↩︎