1.业务场景
利用python代码将中间excel生成RobotFramework支持的关键字
2.完整代码和数据
https://github.com/O-Aiden/AutomatedTesting/tree/master/apitest/Common
3.思维导图
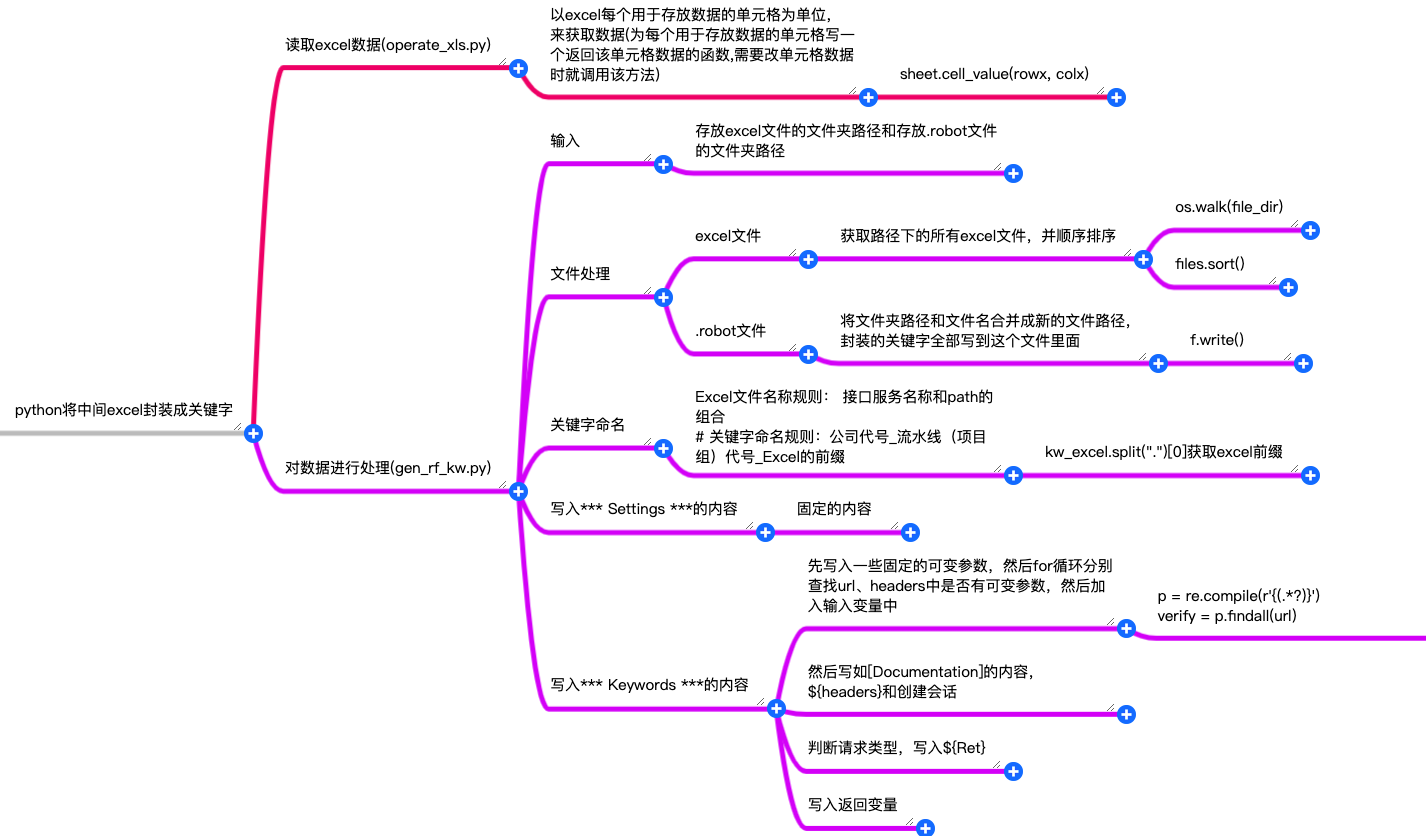
4.核心代码


#! /usr/bin/python # coding:utf-8 """ @From:https://www.cnblogs.com/Detector/p/10211679.html @author:Bingo.he @Add:Yuki @file: operate_xls.py @time: 2019/01/01 """ import xlrd # from 接口测试.InterfaceTestFrameWork.common.common import logger class OperateXls: def __init__(self, xls_ile, index): self.book = xlrd.open_workbook(xls_ile, encoding_override='utf-8') self.sheet = self.book.sheet_by_index(index) # 通过sheet索引获得sheet对象 def switch_sheet_index(self, count): """ 通过index切换sheet对象 :param count: :return: """ self.sheet = self.book.sheet_by_index(count) def switch_sheet_by_name(self, sheet_name): """ 通过sheet name 切换 sheet对象 :param sheet_name: :return: """ self.sheet = self.book.sheet_by_name(sheet_name) def sheet_name_by_index(self, count): return self.book.sheet_names()[count] # 获得指定索引的sheet表名字 def get_value(self, rowx, colx): return self.sheet.cell_value(rowx, colx) def sheet_params_by_name(self, sheet_name): """ 返回sheet页所有数据 :param sheet_name: :return: sheet data format: {row_num:[data of column1,data of column2....]} """ all_data = {} row_data = [] sheet = self.book.sheet_by_name(sheet_name) # 通过sheet名字来获取 row_num = sheet.nrows # 获取行总数 cols_num = sheet.ncols # 获取行总数 # logger.info("有效数据行数: " + str(row_num)) # logger.info("有效数据列数: :" + str(cols_num)) for i in range(0, row_num): for c in range(cols_num): row_data.append(sheet.cell_value(i, c)) # 获取指定EXCEL文件中,第一个SHEET中的接口字段名 all_data[i] = row_data row_data = [] # logger.info(str(json.dumps(all_data, indent=4))) # logger.info(str(all_data)) return all_data def sheet_params_by_index(self, index): """ 返回sheet页所有数据 :param index: :return: sheet data format: {row_num:[data of column1,data of column2....]} """ all_data = {} row_data = [] sheet = self.book.sheet_by_index(index) # 通过sheet名字来获取 row_num = sheet.nrows # 获取行总数 cols_num = sheet.ncols # 获取行总数 # logger.info("有效数据行数: " + str(row_num)) # logger.info("有效数据列数: :" + str(cols_num)) for i in range(0, row_num): for c in range(cols_num): row_data.append(sheet.cell_value(i, c)) # 获取指定EXCEL文件中,第一个SHEET中的接口字段名 all_data[i] = row_data row_data = [] # logger.info(str(json.dumps(all_data, indent=4))) # logger.info(str(all_data)) return all_data class ReadRFExcel(OperateXls): def rf_xls_param_type(self): return self.get_value(1, 0) # 获取'B2'字段内容 def rf_xls_param_value(self): return self.get_value(1, 1) # 获取'B2'字段内容 def rf_xls_msg_type(self): return self.get_value(1, 3) # 获取'D2'字段内容 def rf_xls_method(self): return self.get_value(1, 6) # 获取'G2'字段内容 def rf_xls_url(self): return self.get_value(1, 7) # 获取'H2'字段内容 def rf_xls_group(self): return self.get_value(1, 8) # 获取'I2'字段内容 def rf_xls_document(self): return self.get_value(1, 9) # 获取'J2'字段内容 def rf_xls_headers(self): return self.get_value(1, 10) # 获取'K2'字段内容 if __name__ == '__main__': op = ReadRFExcel("/Users/Shared/Relocated Items/Security/长期文件/自动化测试/APITest/Common/Testscript/data/detector_post.xls", 0) print(op.rf_xls_headers()) op.switch_sheet_index(0) op.rf_xls_headers() op.sheet_params_by_index(0) op.sheet_name_by_index(0)
#! /usr/bin/python # coding:utf-8 """ @creator:Bingo.he @modifier:Yuki @file: operate_xls.py @time: 2020/09/09 """ import xlrd # from 接口测试.InterfaceTestFrameWork.common.common import logger class OperateXls: def __init__(self, xls_ile, index): self.book = xlrd.open_workbook(xls_ile, encoding_override='utf-8') self.sheet = self.book.sheet_by_index(index) # 通过sheet索引获得sheet对象 def switch_sheet_index(self, count): """ 通过index切换sheet对象 :param count: :return: """ self.sheet = self.book.sheet_by_index(count) def switch_sheet_by_name(self, sheet_name): """ 通过sheet name 切换 sheet对象 :param sheet_name: :return: """ self.sheet = self.book.sheet_by_name(sheet_name) def sheet_name_by_index(self, count): return self.book.sheet_names()[count] # 获得指定索引的sheet表名字 def get_value(self, rowx, colx): return self.sheet.cell_value(rowx, colx) def sheet_params_by_name(self, sheet_name): """ 返回sheet页所有数据 :param sheet_name: :return: sheet data format: {row_num:[data of column1,data of column2....]} """ all_data = {} row_data = [] sheet = self.book.sheet_by_name(sheet_name) # 通过sheet名字来获取 row_num = sheet.nrows # 获取行总数 cols_num = sheet.ncols # 获取行总数 # logger.info("有效数据行数: " + str(row_num)) # logger.info("有效数据列数: :" + str(cols_num)) for i in range(0, row_num): for c in range(cols_num): row_data.append(sheet.cell_value(i, c)) # 获取指定EXCEL文件中,第一个SHEET中的接口字段名 all_data[i] = row_data row_data = [] # logger.info(str(json.dumps(all_data, indent=4))) # logger.info(str(all_data)) return all_data def sheet_params_by_index(self, index): """ 返回sheet页所有数据 :param index: :return: sheet data format: {row_num:[data of column1,data of column2....]} """ all_data = {} row_data = [] sheet = self.book.sheet_by_index(index) # 通过sheet名字来获取 row_num = sheet.nrows # 获取行总数 cols_num = sheet.ncols # 获取行总数 # logger.info("有效数据行数: " + str(row_num)) # logger.info("有效数据列数: :" + str(cols_num)) for i in range(0, row_num): for c in range(cols_num): row_data.append(sheet.cell_value(i, c)) # 获取指定EXCEL文件中,第一个SHEET中的接口字段名 all_data[i] = row_data row_data = [] # logger.info(str(json.dumps(all_data, indent=4))) # logger.info(str(all_data)) return all_data class ReadRFExcel(OperateXls): def rf_xls_param_type(self): return self.get_value(1, 0) # 获取'B2'字段内容 def rf_xls_param_value(self): return self.get_value(1, 1) # 获取'B2'字段内容 def rf_xls_msg_type(self): return self.get_value(1, 3) # 获取'D2'字段内容 def rf_xls_method(self): return self.get_value(1, 6) # 获取'G2'字段内容 def rf_xls_url(self): return self.get_value(1, 7) # 获取'H2'字段内容 def rf_xls_group(self): return self.get_value(1, 8) # 获取'I2'字段内容 def rf_xls_document(self): return self.get_value(1, 9) # 获取'J2'字段内容 def rf_xls_headers(self): return self.get_value(1, 10) # 获取'K2'字段内容
5.参考链接