1. 请描述spark RDD原理与特征
RDD为Resilient Distributed Datasets缩写,译文弹性分布式数据集。
他是spark系统中的核心数据模型之一,另外一个是DAG模型。
它是“只读”,“分区”的数据集合。其类内部有5个部分组成:
1. 一组partition partitions_ : Array[Partition]
2.每个partition的计算函数 通过诗选compute函数达到这个目的。
3.RDD依赖关系,新的RDD可以从已有的RDD转换而来,当RDD中的分区丢失那么可以通过这个关系将这些数据从父RDD中重新计算。
4.一个分片函数partitioner,模式实现了了hashpartitioner和RangePartitioner。这个函数据定了当前RDD的分片数量,以及父RDD的shuffle输出时候的分片数量。
5.一个列表,保存了各个分区的优先位置,比如HDFS文件来说就保存了每一个分区的所在块的位置。
弹性分布式数据集的字面弹性和分布式的理解:
分布式很好理解,我们的数据是一般存储在hdfs分布式文件系统的,所以RDD也是分布式的。
弹性可以理解为两层意思:1,数据是可存储在磁盘或者内存,也可以部分分区在内存部分分区存储在磁盘。
2,RDD的数据是可以通过父RDD进行恢复,且可以做到部分分区数据通过依赖关系进行恢复,这称之为“血统”。
RDD的产生:三种1,已有的scala的数据集合 2,外部存储系统如s3 hdfs等 3,通过父RDD的转换而来。
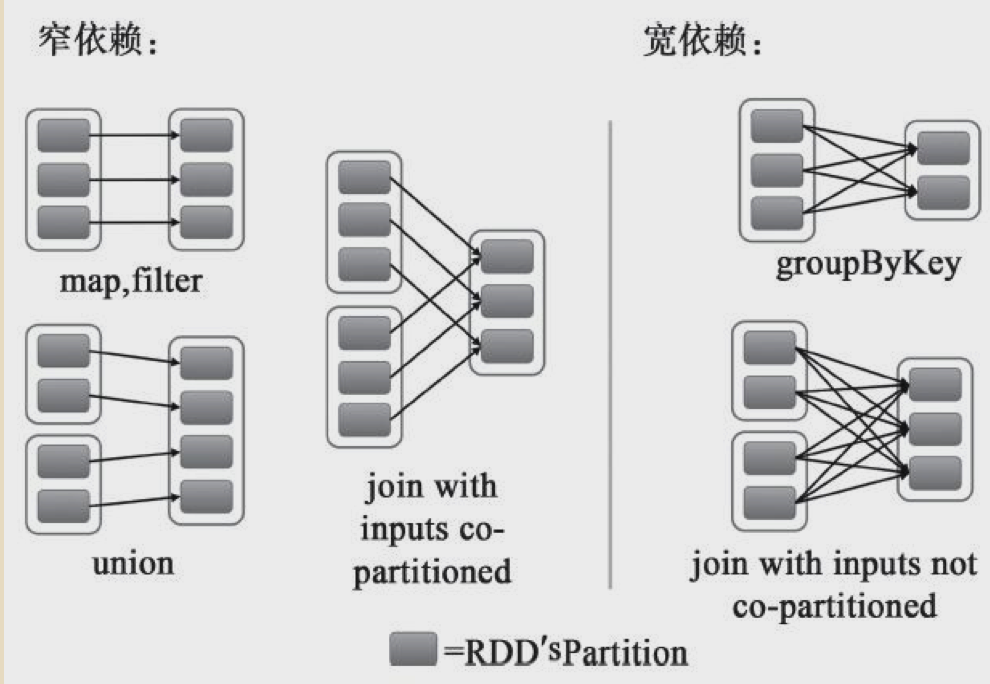
2.如何理解spark RDD宽依赖和窄依赖,并结合示例描述
spark从RDD依赖上来说分为窄依赖和宽依赖。
其中可以这样区分是哪种依赖:当父RDD的一个partition被子RDD的多个partitions引用到的时候则说明是宽依赖,否则为窄依赖。
宽依赖会触发shuffe,宽依赖也是一个job钟不同stage的分界线。
本篇文章主要讨论一下窄依赖的场景。
3.基于spark-1.6.1版本,请描述spark统一内存管理机制,和各部分内存区域用途。
1.6版本之前使用的叫做StaticMemoryManager 1.6以及之后使用的内存管理机制叫做:UnifiedMemoryManager
相比于之前的内存管理机制,现在统一内存管理机制可以让storage、execution可以互相从对方借用内存,总体来说解决了如何资源充分利用的问题。
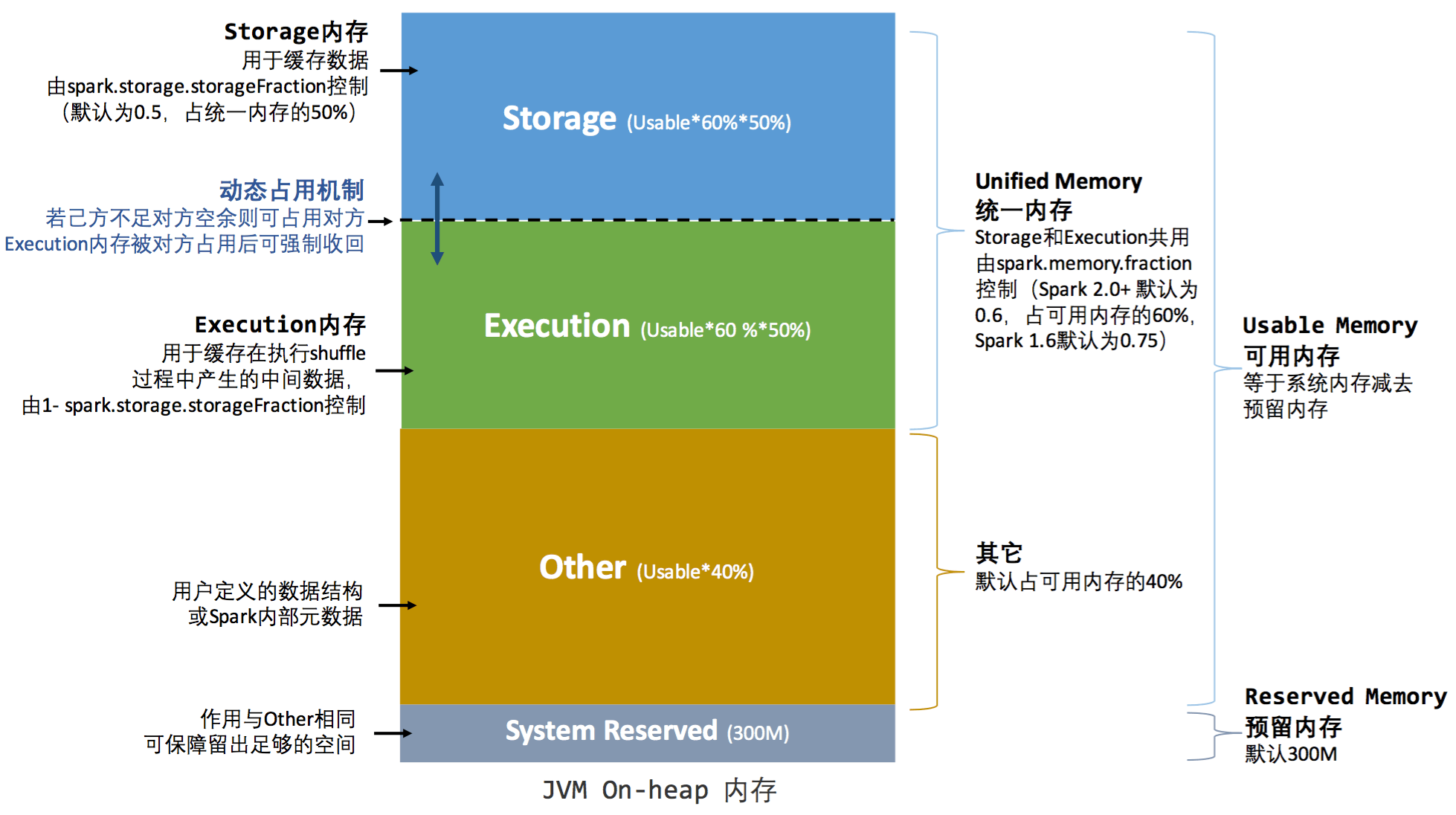
上述为统一内存模型,对相比最主要的区别在于Storage区域与Execution可以动态分配。
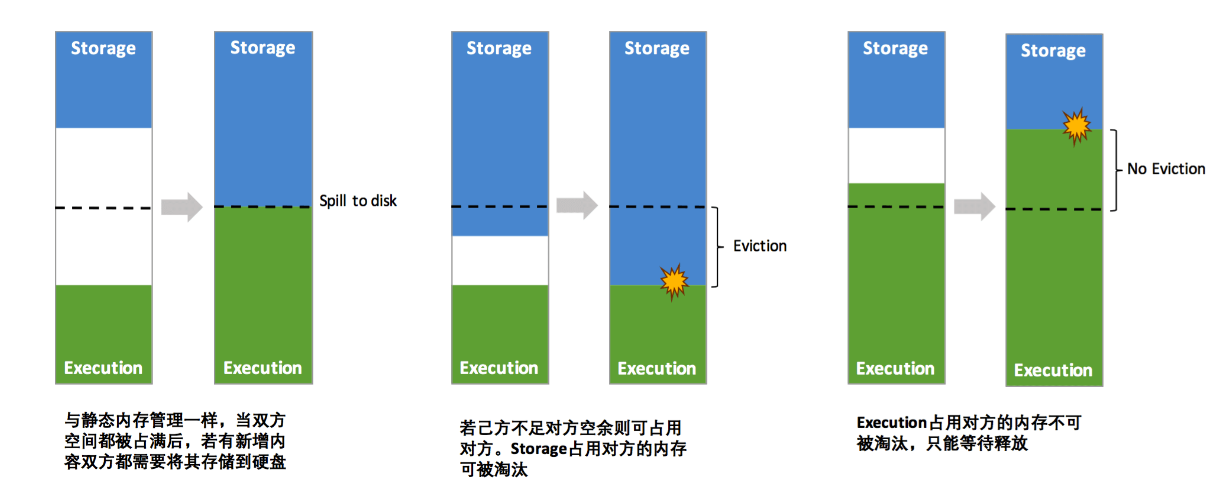
- 设定基本的存储内存和执行内存区域(spark.storage.storageFraction 参数),该设定确定了双方各自拥有的空间的范围
- 双方的空间都不足时,则存储到硬盘;若己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的 Block)
- 执行内存的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后"归还"借用的空间
- 存储内存的空间被对方占用后,无法让对方"归还",因为需要考虑 Shuffle 过程中的很多因素,实现起来较为复杂[4]
4.spark中的RDD,dataframe和dataset有什么区别。
RDD,dataframe和dataset都是spark提供给开发者的三个主要API。
RDD是最底层的数据模型。属于spark-core包=模块中。
无论是dataframe还是dataset其最终都是转换为RDD来运行的。
而dataframe和dataset则数据spark-sql模块中。
dataframe则是特殊的dataset
type DataFrame = Dataset[Row] |
其中dataset是强类型的,而dataframe则是无类型的。其中row即是一行带有列名及列值的数据。
dataframe与dataset 同 RDD比较,主要是解决了元数据问题。RDD不包含元数据。处理数据不够直观,代码阅读性不好。
而dataframe与dataset则不同,带有元数据,提供特定领域的转换方法。其内部通过Catalyst模块来进行执行优化,转化为RDD进行计算。
以上三种可以相互转换。
5.请描述spark运行时job,stage,task的划分原则,以及其相互间的关系。
个人理解:一个action操作形成一个job,job包含一个或者多个stage,stage包含task组成的taskset。
stage的划分点实在款依赖的RDD之间。同一个stage中都是窄依赖关系,各个分区可以并行执行。
task则是相互独立的分别作用在各个RDD分区之上的一个具体任务。
一个job下只分为shuffleMapTask和ResultTask。
其中一个job的最后stage为每一个结果的partition执行task为ResultTask
6.请描述spark hash shuffle与sort shuffle之间的区别和优劣点。
主要区别就是在于对于小文件的控制上。sort shuffle相比于 hash shuffle在map端产生的小文件更少。
有效降低IO,提高性能。目前sort shuffle是默认shuffle机制了。
hash shuffle在没有consolidation情况下将产生M*R个文件。M为Mapper个数,R为reducer个数。
如下图,其每一个map最坏的情况下都将为每一个reducer产生一个独立文件。
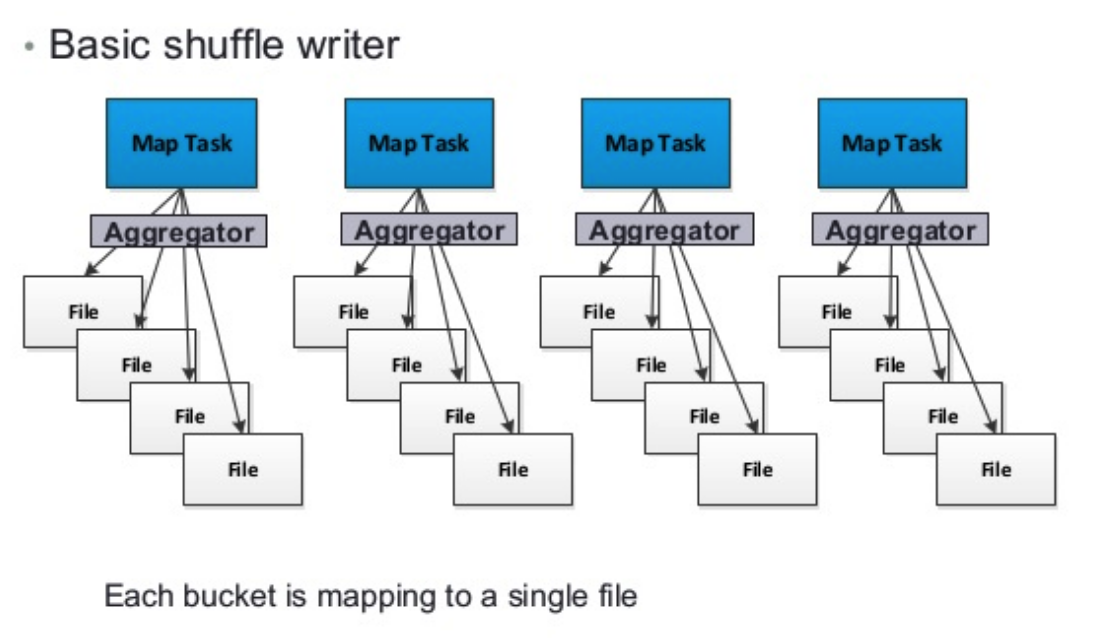
极端情况下,当数据量比较大,M和R都很大的情况下会产生大量的小文件。无论在你写还是在读的时候都会有大量的IO消耗。
而sort shuffle则将上述hash shuffle基础上,将一个mapper下产生的不同的reducer输入文件写到一个文件中,并额外通过一个索引文件去解析她。
这样M端IO将减少,R端的读取也将减少,从而降IO提高效率。
sort shuffle的写如下图:
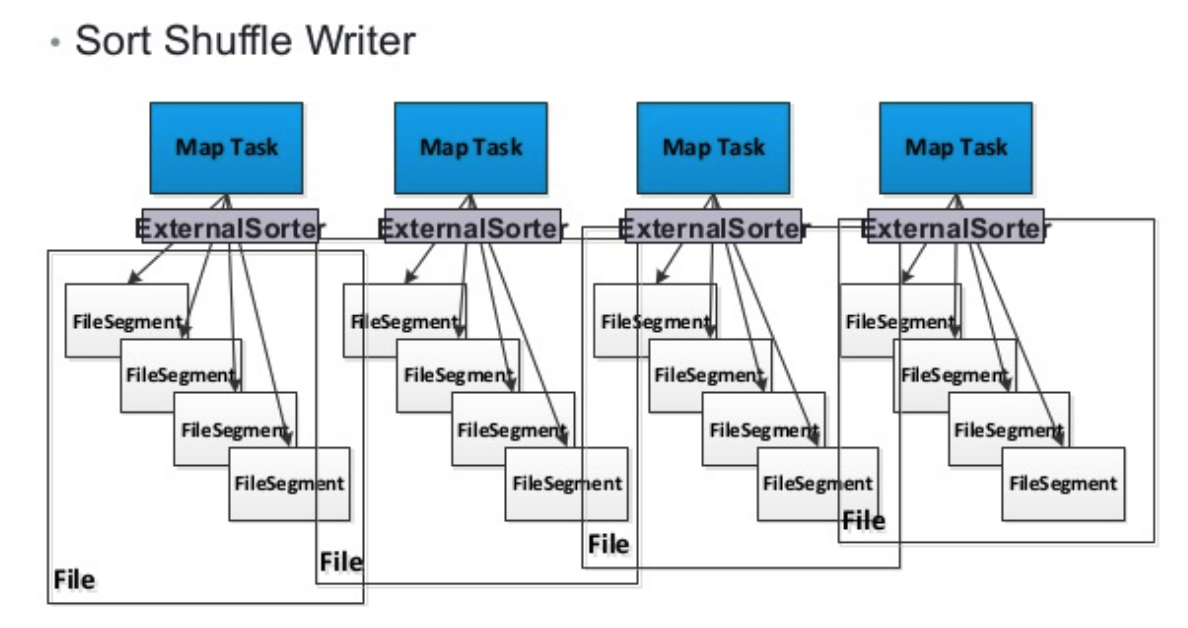
7.spark计算容错性如何保证。
有Lineage机制和Checkpoint机制来保证。这个两个机制是建立在RDD是只读和分区的概念之上的。
Lineage机制:RDD中分区存在父RDD的分区的依赖关系,当前RDD中的某部分分区数据丢失则可以通过这个依赖关系进行数据重新计算重构。
窄依赖的依赖关系代价较小,宽依赖则代缴较大,存在冗余计算。
Checkpoint机制:对于Lineage机制如果Lineage过长或者是存在宽依赖那么使用重算则需要的代价过大,
Checkpoint机制本质就是讲Lineage中的某个RDD写入磁盘作为检查点,后续的子RDD数据丢失则可以直接在检查点开始计算,一般把宽依赖上做Checkpoint最为合适。
8.请描述spark广播变量原理与特点。
1. 广播变量满足三个特点:
1.不变,广播变量是不可变的。
2. 够小,因为是放到executor的内存中的,所以不能太大。
3. 放在executor内存中,在之上的task都可访问。
2. 原理:
首先在driver中生产广播变量,然后在应用的所有的executor都会复制这个广播变量,在这个executor之上的所有task就会公用这个变量。
如果不用广播变量那么所有的task就会和RDD(没有用广播变量前)进行交互,产生较大的网络和磁盘IO。
9.请描述spark yarn-client与yarn-cluster模式原理,并分析其特点。
yarn-client与yarn-cluster的的说法只会当spark on yarn的模式下。
主要区别在于driver(SparkContext)运行在nodemanager的AM上还是运行在本地(如提交任务的机器上)。
另外谁启动driver则谁负责调度。换句话说yarn-client的RM在申请资源启动Executor后并不负责后续的task的调度。
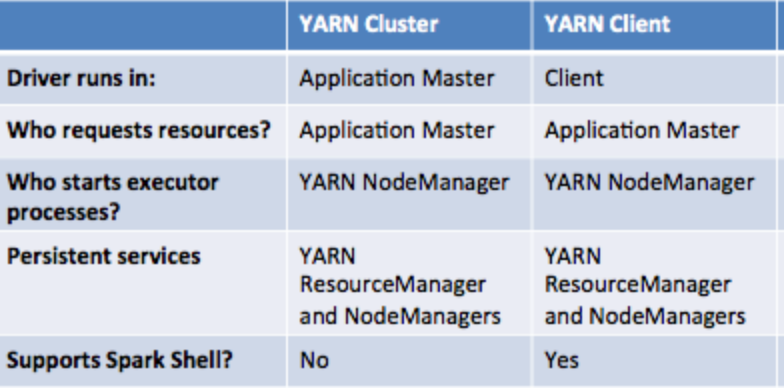
当本地并不需要进行交互计算或者查询的时候建议使用yarn-cluster模式。


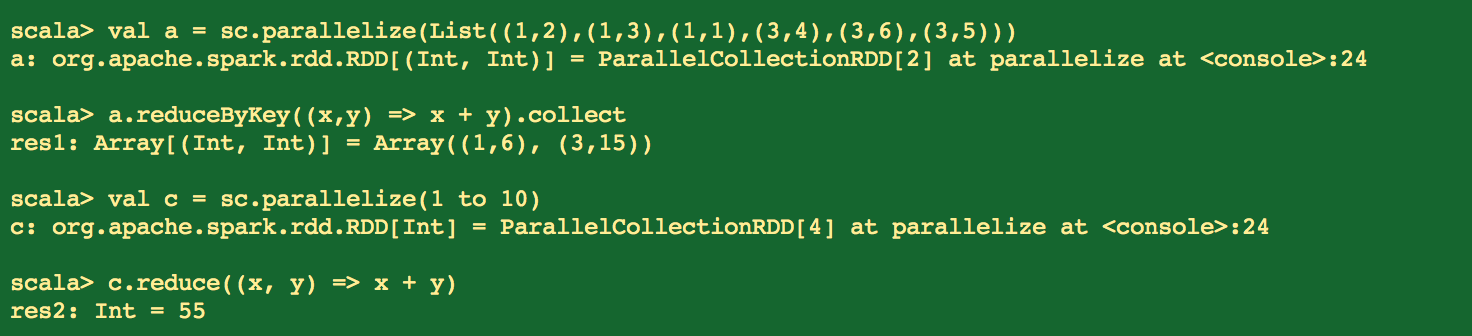
10.请描述spark算子reduce与reduceByKey的区别。
reduce(function):数组中前两个元素做function操作后的值在和第三个元素值做function操作,以此类推。
如
val c = sc.parallelize(1 to 10)
c.reduce((x, y) => x + y)//结果55
解释为:
1+2 = 3
3+3=6
6+4=10
10+5=15
15+6=21
21+7=28
28+8=36
36+9=45
45+10=55
reduceByKey(function):是对元素为KV对的RDD中Key相同的元素的Value进行binary_function的reduce操作,
因此,Key相同的多个元素的值被reduce为一个值,然后与原RDD中的Key组成一个新的KV对。
如:
val a = sc.parallelize(List((1,2),(1,3),(1,1),(3,4),(3,6),(3,5)))
a.reduceByKey((x,y) => x + y).collect
解释为:
key 为 1 的value相加:2+3+1 = 6 形成 (1,6)
key为 3的value相加:4+6+5 = 15 形成(3,15)
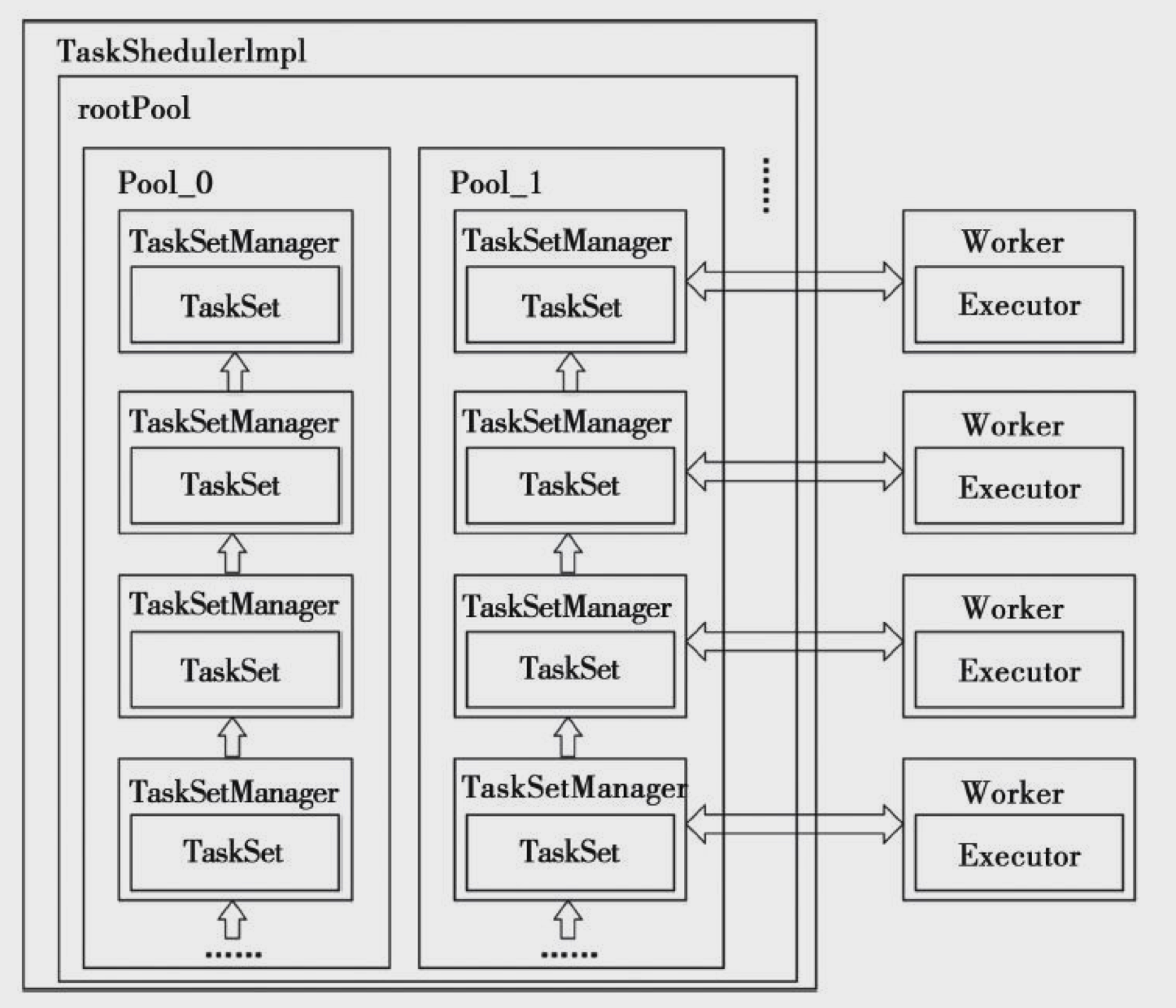
11.spark中任务调度的调度模式有几种,分别描述实现原理
Spark中总体的任务调度如下图:
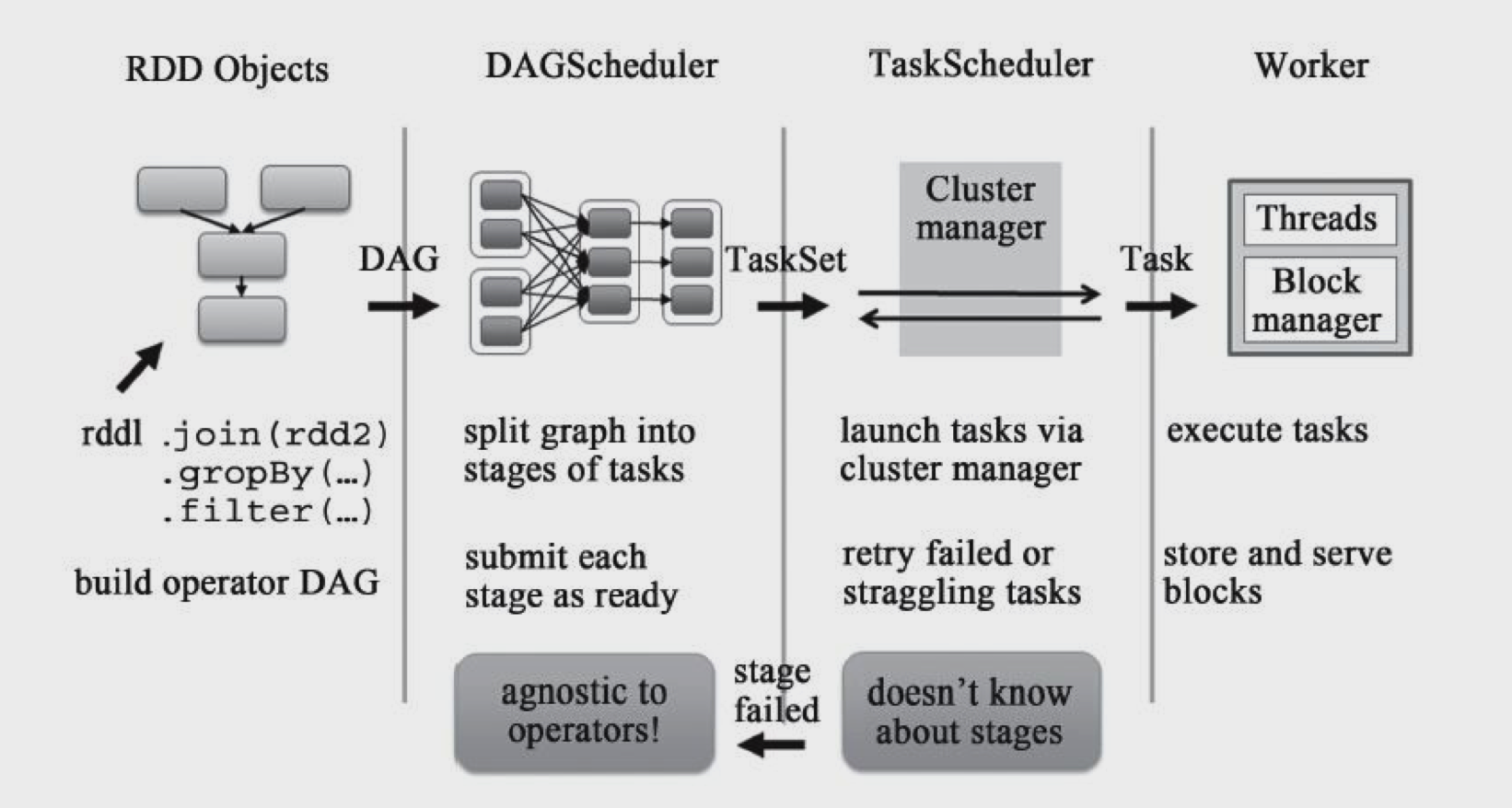
spark目前支持两种调度策略:
SchedulingMode.FIFO 先入先出调度策略和 SchedulingMode.FAIR 公平调度策略 ,他们都是application级别的策略。
1. SchedulingMode.FIFO :保证jobid较小的先调度,如果是同一个job,那么stage的id小的先调度。

private[spark] class FIFOSchedulingAlgorithm extends SchedulingAlgorithm {
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val priority1 = s1.priority
val priority2 = s2.priority
var res = math.signum(priority1 - priority2)
if (res == 0) {
val stageId1 = s1.stageId
val stageId2 = s2.stageId
res = math.signum(stageId1 - stageId2)
}
res < 0
}
}
2. SchedulingMode.FAIR 公平调度策略 :rootpool下挂在的是一组pool,叶子节点是tasksetmanager,首先是确定rootpool的子pool的调度顺序,然后在子pool内部使用相同的
算法确定调度顺序。
private[spark] class FairSchedulingAlgorithm extends SchedulingAlgorithm {
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val minShare1 = s1.minShare
val minShare2 = s2.minShare
val runningTasks1 = s1.runningTasks
val runningTasks2 = s2.runningTasks
val s1Needy = runningTasks1 < minShare1
val s2Needy = runningTasks2 < minShare2
val minShareRatio1 = runningTasks1.toDouble / math.max(minShare1, 1.0)
val minShareRatio2 = runningTasks2.toDouble / math.max(minShare2, 1.0)
val taskToWeightRatio1 = runningTasks1.toDouble / s1.weight.toDouble
val taskToWeightRatio2 = runningTasks2.toDouble / s2.weight.toDouble
var compare = 0
if (s1Needy && !s2Needy) {
return true
} else if (!s1Needy && s2Needy) {
return false
} else if (s1Needy && s2Needy) {
compare = minShareRatio1.compareTo(minShareRatio2)
} else {
compare = taskToWeightRatio1.compareTo(taskToWeightRatio2)
}
if (compare < 0) {
true
} else if (compare > 0) {
false
} else {
s1.name < s2.name
}
}
}
12.spark on yarn模式下,spark executor oom时候,请列举哪些可以解决或者调优,请具体描述。
1. 减少数据膨胀:
a. 使用数组和基本类型来减少数据膨胀。
b. 避免过多的小对象的嵌套
c. 如果RAM 小于32 GB则可以在spark-env.sh中设置-XX:+UseCompressedOops参数,来将指针地址长度从8位变为4位。
2. 保持executor上的task的数据本地性。
当数据非本地的时候将会远程从其他executor上加载数据到内存,当数据过大可能引起oom,我们可以调大spark.locality.wait
3.防止过大的partation。
可以使用repartition对RDD重新分区。
4.GC调优
使用G1 回收策略等
5. 使用spark.rdd.compress 指定为KryoSerializer
可以进一步压缩在内存中的数据,并且比java自带的要更加高效。
6.适当的调整spark.memory.storageFraction
避免过多的借还。
13.请分析以下异常发生原因,并概述spark监听器机制。
Dropping SparkListenerEvent because no remaining room in event queue. This likely means one of the SparkListeners is too slow and cannot keep up with the rate at which tasks are being started by the scheduler.
原因:
val eventAdded = eventQueue.offer(event)
if (eventAdded) {
eventLock.release()
} else {
onDropEvent(event)
droppedEventsCounter.incrementAndGet()
}
上述当发生队列容量不足的时候将会发生drop事件从而出现此日志信息。
14.举例分析spark数据倾斜现象,原因和解决方法。
15.spark streaming中Dstream是如何产生,请描述过程。
16.spark streaming与kafka集成应用时,从kafka读取数据的几种获取方式,并各有什么不同。
17.请描述spark thriftServer增量(配置参数spark.sql.thriftServer.incrementalCollect)取数机制。
18.以“select count(*) from table”语句为例子,描述spark task产生过程。
19.请说明spark-sql产生小文件的原因,请描述其调优解决方法。
20.请举例spark常用优化参数,请阐述其意义和应用场景。