行走江湖必备一份面试题,这里给大家整理了一套.0面试官最喜欢问的问题或者出场率较高的面试题,助校招或者社招路上的你一臂之力!
首先我们需要明白一个事实,招聘的一个很关键的因素是在给自己找未来的同事,同级别下要找比自己优秀的人,面试是一个双向选择的过程,也是一个将心比心去沟通的过程。
和以前一样,罗列一些问题和简单的解答(不保证完全正确),有问题可以留言,保证尽快修正!
开场白
简单的介绍一下自己的工作经历与职责,在校或者工作中主要的工作内容,主要负责的内容;(你的信息一清二白的写在简历上,这个主要为了缓解面试者的压力)
介绍下自己最满意的,有技术亮点的项目或平台,重点介绍下自己负责那部分的技术细节;(主要考察应聘者对自己做过的事情是否有清晰的描述,判断做的事情的复杂度)
一般面试官会根据你提到的项目,或者技术栈进行提问,所以需要去引导面试官,你懂了么?
Java多线程相关
-
线程池的原理,为什么要创建线程池?创建线程池的方式;
详情
- 通过重复利用已创建的线程,减少在创建和销毁线程上所花的时间以及系统资源的开销。
- 提高响应速度,当任务到达时,任务可以不需要等到线程创建就可以立即执行。
- 提高线程的可管理性,使用线程池可以对线程进行统一的分配和监控。
- 如果不使用线程池,有可能造成系统创建大量线程而导致消耗完系统内存。
- 线程池大小,不是越大越好,最好=cpu数量+1
- 还需要注意并发引起的问题,要从逻辑上保证程序的正确性,注意避免死锁现象的发生。 -
线程的生命周期,什么时候会出现僵死进程;

-
说说线程安全问题,什么实现线程安全,如何实现线程安全;
参考
- 多线程编程中的三个核心概念:原子性、可见性、有序性
- 保证安全:互斥同步,synchronized加锁
- 非阻塞同步,乐观锁+seq控制
- ThreadLocal无同步方案,线程本地存储:将共享数据的可见范围限制在一个线程中。
- 这样无需同步也能保证线程之间不出现数据争用问题。 -
创建线程池有哪几个核心参数? 如何合理配置线程池的大小?
简介
corePoolSize(核心线程数) 最好要==max 不用创建销毁
maxPoolSize(最大线程数)
queueCapacity(任务队列容量)
keepAliveTime(线程空闲时间)60s
allowCoreThreadTimeout(允许核心线程超时)false
rejectedExecutionHandler(任务拒绝处理器) AbortPolicy -
volatile、ThreadLocal的使用场景和原理;
简介
原子性 :java中,对于引用变量,和大部分的原始数据类型的读写(除long 和 double外)操作 都是原子的。这些操作不可被中断,要么执行,要么不执行。对于所有被声明为volatile的变量的读写,都是原子的(除long和double外)
可见性:java提供了volatile关键字来保证可见性。[volatile无法保证对变量的任何操作都是原子性的]
当一个共享变量被volatile修饰时,它会保证修改的值立即被更新到主内存。其他线程读取时会从内存中读到新值。普通的共享变量不能保证可见性,其被写入内存的时机不确定。当其他线程去读,可能读到的是旧的值
另外通过synchronized和lock也可以保证可见性。它们能保证同一时刻只有一个线程获取锁然后执行同步代码。并在释放锁之前对变量的修改刷新到住内存中。以此来保证可见性
有序性 :java内存模型中,允许编译器和处理器 对指令进行重排序。其会影响多线程并发执行的正确性。在java里可以通过volatile关键字,还有synchronized和lock来保证有序性。
threadLocal
ThreadLocal里面使用了一个存在弱引用的map,当释放掉threadlocal的强引用以后,map里面的value却没有被回收.而这块value永远不会被访问到了. 所以存在着内存泄露. 最好的做法是将调用threadlocal的remove方法.
具体参下 -
ThreadLocal什么时候会出现OOM的情况?为什么?
-
synchronized、volatile区别、synchronized锁粒度、模拟死锁场景、原子性与可见性;
JVM相关
-
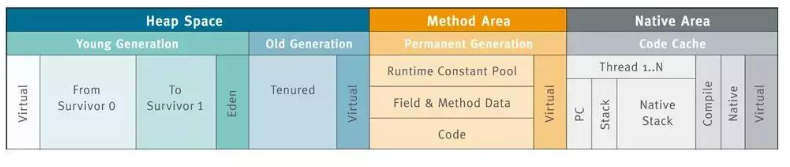
JVM内存模型,GC机制和原理;
-
GC分哪两种,Minor GC 和Full GC有什么区别?什么时候会触发Full GC?分别采用什么算法?
-
Minor GC
从年轻代空间(包括Eden和Survivor区域)回收内存被称为Minor GC :
当Eden区域满了,jvm无法为新对象分配内存,会触发Minor GC;
新生代好进行标记和复制操作,就不会存在内存碎片。
年轻代中指向永久代中的引用,在标记阶段就会忽略。
stop-the-world。原因是Eden区中对象认为是垃圾,不会复制到Survivor区或者老年代。
如果相反,Eden区大部分对象不符合GC 条件,那么 Minor GC指定的时间就比较长。
每次Minor GC会清理年轻代的内存。 -
Major GC 和Full GC
Major GC: 清理老年代
Full GC: 清理整个堆内存,包括年轻代和老年代 -
新生代管理内存采用的算法为 GC复制算法( CopyingGC),
也叫标记-复制法, -
老年代管理内存最早采用的算法为标记-清除算法
-
触发MinorGC(Young GC)
虚拟机在进行minorGC之前会判断老年代最大的可用连续空间是否大于新生代的所有对象总空间
1、如果大于的话,直接执行minorGC
2、如果小于,判断是否开启HandlerPromotionFailure,没有开启直接FullGC
3、如果开启了HanlerPromotionFailure, JVM会判断老年代的最大连续内存空间是否大于历次晋升的大小,如果小于直接执行FullGC
4、如果大于的话,执行minorGC -
触发FullGC
- 老年代空间不足
如果创建一个大对象,Eden区域当中放不下这个大对象,会直接保存在老年代当中,如果老年代空间也不足,就会触发Full GC。为了避免这种情况,最好就是不要创建太大的对象。 - 永久代空间不足
如果有持久代空间的话,系统当中需要加载的类,调用的方法很多,同时持久代当中没有足够的空间,就出触发一次Full GC - YGC出现promotion failure
promotion failure发生在Young GC, 如果Survivor区当中存活对象的年龄达到了设定值,会就将Survivor区当中的对象拷贝到老年代,如果老年代的空间不足,就会发生promotion failure, 接下去就会发生Full GC. - 统计YGC发生时晋升到老年代的平均总大小大于老年代的空闲空间
在发生YGC是会判断,是否安全,这里的安全指的是,当前老年代空间可以容纳YGC晋升的对象的平均大小,如果不安全,就不会执行YGC,转而执行Full GC。 - 显式调用System.gc
- 老年代空间不足
-
-
JVM里的有几种classloader,为什么会有多种?


ClassLoader作用
(1)加载class文件进入JVM
(2)审查每个类应该由谁加载,采用双亲委托机制
(3)将class字节码重新解析成JVM要求的对象格式

- 什么是双亲委派机制?介绍一些运作过程,双亲委派模型的好处;
定义 : 某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父类加载器,依次递归,如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成此加载任务时,才自己去加载。
好处 :采用双亲委派的一个好处是比如加载位于rt.jar包中的类java.lang.Object,不管是哪个加载器加载这个类,最终都是委托给顶层的启动类加载器进行加载,这样就保证了使用不同的类加载器最终得到的都是同样一个Object对象。
-
什么情况下我们需要破坏双亲委派模型;
-
常见的JVM调优方法有哪些?可以具体到调整哪个参数,调成什么值?
java -Xmx3550m -Xms3550m -Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4
-XX:MaxPermSize=16m -XX:MaxTenuringThreshold=0
-Xmx3550m:设置JVM最大可用内存为3550M。
-Xms3550m:设置JVM促使内存为3550m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个堆大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
-XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
-XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
-XX:MaxPermSize=16m:设置持久代大小为16m。
-XX:MaxTenuringThreshold=0:设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概论
- JVM虚拟机内存划分、类加载器、垃圾收集算法、垃圾收集器、class文件结构是如何解析的;
Java高级部分
-
红黑树 /B树 /B+/B- 原理&区别 以及应用场景
在数据较小,可以完全放到内存中时,红黑树的时间复杂度比B树低。
反之,数据量较大,外存中占主要部分时,B树因其读磁盘次数少,而具有更快的速度
红黑树:(RB Tree)是平衡二叉树,其优点就是树到叶子节点深度一致,查找的效率也就一样,为logN.
B树:即二叉搜索树,所有非叶子结点至多拥有两个儿子,非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树
B-树:是一种多路搜索树(并不是二叉的
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
B+树:B+树是B-树的变体,也是一种多路搜索树:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统; -
NIO是什么?适用于何种场景?
NIO是为了弥补IO操作的不足而诞生的,NIO的一些新特性有:非阻塞I/O,选择器,缓冲以及管道。管道(Channel),缓冲(Buffer) ,选择器( Selector)是其主要特征。
那么NIO和IO各适用的场景是什么呢?
- 如果需要管理同时打开的成千上万个连接,这些连接每次只是发送少量的数据,例如聊天服务器,这时候用NIO处理数据可能是个很好的选择。
- 如果只有少量的连接,而这些连接每次要发送大量的数据,这时候传统的IO更合适。使用哪种处理数据,需要在数据的响应等待时间和检查缓冲区数据的时间上作比较来权衡选择。
NIO理解
导游在车站等待游客,有多个线路到达,传统IO就是在那一直等,NIO有selector来监听/轮询 查看是否有游客到达,有人来了就会通知导游来接客,不用浪费大家等待的时间,比较高效; -
Java9比Java8改进了什么
- java8:
- 引入Lambda表达式
- 接口引入默认方法与静态方法
- JVM的新特性 (Metaspace(元空间) 取代PermGen空间(永久保存区))
- Nashorn JavaScript引擎
- java9
- Java平台级模块系统
- 支持HTTP/2.0
- 接口私有方法
- 多版本兼容 JAR
- java8:
-
HashMap内部的数据结构是什么?底层是怎么实现的?(还可能会延伸考察ConcurrentHashMap与HashMap、HashTable等,考察对技术细节的深入了解程度);
底层采用分段的数组+链表实现,线程安全
- 通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。)
-Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术
-有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁
-扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容
- 通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。)
-
说说反射的用途及实现,反射是不是很慢,我们在项目中是否要避免使用反射;
-
说说自定义注解的场景及实现;
-
List 和 Map 区别,Arraylist 与 LinkedList 区别,ArrayList 与 Vector 区别;
Spring相关
-
Spring4 Spring5的一些区别
-
Spring AOP的实现原理和场景?
-
Spring bean的作用域和生命周期;
-
Spring Boot比Spring做了哪些改进? Spring 5比Spring4做了哪些改进;
-
如何自定义一个Spring Boot Starter?
-
Spring IOC是什么?优点是什么?
-
SpringMVC、动态代理、反射、AOP原理、事务隔离级别;
-
SpringBoot Component和@Configuration
@Configuration 注解本质上还是 @Component,因此 context:component-scan/ 或者 @ComponentScan 都能处理@Configuration 注解的类。
@Configuration 注解的 bean 都已经变成了增强的类。
Component 注解并没有通过 cglib 来代理@Bean 方法的调用
中间件篇
-
Dubbo完整的一次调用链路介绍;
-
Dubbo支持几种负载均衡策略?
-
Dubbo Provider服务提供者要控制执行并发请求上限,具体怎么做?
-
Dubbo启动的时候支持几种配置方式?
-
了解几种消息中间件产品?各产品的优缺点介绍;
-
消息中间件如何保证消息的一致性和如何进行消息的重试机制?
-
Spring Cloud熔断机制介绍;
-
Spring Cloud对比下Dubbo,什么场景下该使用Spring Cloud?
数据库篇
-
锁机制介绍:行锁、表锁、排他锁、共享锁;
-
乐观锁的业务场景及实现方式;
-
事务介绍,分布式事物的理解,常见的解决方案有哪些,什么事两阶段提交、三阶段提交;
-
MySQL记录binlog的方式主要包括三种模式?每种模式的优缺点是什么?
-
MySQL锁,悲观锁、乐观锁、排它锁、共享锁、表级锁、行级锁;
-
分布式事务的原理2阶段提交,同步异步阻塞非阻塞;
-
数据库事务隔离级别,MySQL默认的隔离级别、Spring如何实现事务、JDBC如何实现事务、嵌套事务实现、分布式事务实现;
-
SQL的整个解析、执行过程原理、SQL行转列;
Redis
-
Redis为什么这么快?redis采用多线程会有哪些问题?
-
Redis支持哪几种数据结构;
-
Redis跳跃表的问题;
-
Redis单进程单线程的Redis如何能够高并发?
-
Redis如何使用Redis实现分布式锁?
-
Redis分布式锁操作的原子性,Redis内部是如何实现的?
其他
-
cpu打满的情况如何排查
-
GC频繁的情况下如何排查 思路
-
看过哪些源代码?然后会根据你说的源码问一些细节的问题?(这里主要考察面试者是否对技术有钻研的精神,还是只停留在表面,还是背了几道面经,这个对于很多有强迫症的面试官,如果你连源码都没看过,基本上是会pass掉的,比如我也是这样的!)
-
项目中遇到了哪些比较有挑战性的问题,是如何解决的;(这个很有争议,一方面是你连一个复杂的问题都解决不了,要你过来干什么,还有就是,我的能力牛逼啊,但是公司没有业务场景让我展示啊!这个就看你遇到的面试官了,祝你好运!)
-
到此为止,大致把一些面试官高频的面试题整理了一下,希望对大家有所帮助!