什么是类
C++是什么?C++设计之初就是class with c,所以简单点说,C++就是带类的C,那么什么是类?
类,简单点说就是类型,在C++中我们一开始所接触的类型有如下几种:
//+-------------------
char,
short,
int,
long,
long long,
float,
double
……
//+------------------
这些类型属于语言本身的一部分,我们称之为基本类型,基本类型不可被更改,也不可被创造,更不可
被消灭,任何一个程序都是有基本类型搭建起来的,比如,我们想要用一个类型来表示一个学生,那么
我们可以char*,来表示他的名字,用unsigned int来表示他的学号,用double来表示他的成绩等等,而
这个表示学生信息的类型是由我们自定义而来,所以我们称之为自定义类型,在C语言里面,如果我们
想要自定义一个类型出来,那么我们只能用关键字struct或者union,常使用的是struct,而union仅仅用
于某些特殊的场合,所以我们可以按如下的放下来定义一个自定义类型:
//+-----------------
typedef struct UserType{
int a;
double b;
long long c;
}* __LPUSERTYPE;
//+----------------
这个自定义类型由三个数据段组成,当然如果你要问我干嘛这么定义,我想应该必要的时候会这么定义吧。
那么,既然说C++是带类的C,那么在C++里面扩展一个自定义类型又该如何呢?当然,如果我说class在很
多时候等同于struct的话那么这个问题是不是就不再是问题了呢?ok,如果刚才的那个UserType到底表示什
么都不清楚的话,那么下面我们尝试用一种能够说清楚的类型来阐述自定义类型的定义:
//+---------------
class Point{
public:
double x;
double y;
};
//+---------------
class : C++ 关键字,表示接下来要定义一个类型啦。
Point : 类型名,总是跟在class的后面,指明类型名是什么,class 和 类型名的中间还可以有其他的东
西,比如我们在写com的时候使用的uuid,比如我们要导出一个类时候使用的__declspec(dllexport)等。
{} : class 的代码段。
在 C++ 里面,class 是一句完整的C++语句,C++语句都是以";"结束,所以在"}"后面需要要用表示结束
的";"号,否则你会遇到各种你预想不到的错误,当然,该语法对于C语言的struct也同样实用那么class和struct
又有什么区别呢?在C语言里面,struct里面所定义的数据类型都是可以直接访问的,简单点说C语言的struct的
数据是共有的,同时C语言里的struct里面不可以有成员函数,当然这个限制在C++中已经被摒弃,在C++中,
struct和class的唯一区别就是默认权限的区别,在C语言中没有权限的概念,但C++作为面向对象的编程语言,
所以自然提供了权限的概念,以便于数据的封装,只是struct的默认权限是public,而class的默认权限是
private,public顾名思义是公共的,private是私有的,当然除了public和private外还存在一个权限:protected,
private和protected所限制的数据都是外部不能够访问的,那么他们的区别是什么呢?private是纯粹的对数据
进行封装,protected不但对数据进行封装,还对继承留下一个后门。如你们所见,这里我们使用的plubic权限,
public后面必须跟有":"号,所以在public下面的接口或者数据都是外部能够直接访问得到的。 那么在C++中,
我们什么时候使用struct什么时候使用class呢?这里没有什么标准规范来限制,所以简单点说就是凡是使用struct
的地方都可以使用class来替换,反之亦然,但是,通常于C++来说有个不成文的规矩,那就是如果仅仅只是简单
的定义一个组合类型的话我们使用struct,否则我们都应该使用class。


构造函数
什么是构造函数,从名字上面来理解,我们可以简单的认为就是构造对象的函数,一个类型想要被实例化,
那么它首先调用的便是这个构造函数,而从代码的角度来理解的话构造函数就是名字和类型名一样的函数,
该函数可以有参数,但没有返回值,如果该函数没有参数,那么该函数被称为默认构造函数。




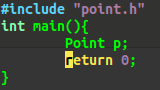
例如只定义了Point类的构造函数如图:
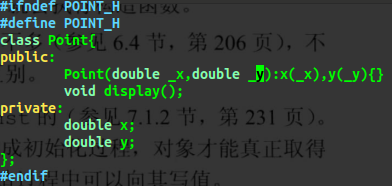
Point类没有默认构造函数。
编译时出错:可见编译器在面对刚创建并未显示初始化的对象时,对它进行默认初始化,若该类没有
默认构造函数,则报错。可见编译器的责任是保证每个类被创建后,必须调用一个构造函数,令其是被初始化的。
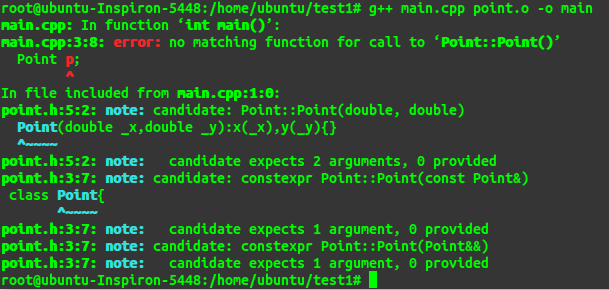
构造函数的形式我们已经了解:那么问题是我们自己编写了自己的构造函数,那么构造函数的样子
是不是就是这样呢?答案是不会的。编译器会给你添油加醋的。。。哈哈
编译器会对其检查。规则就是:
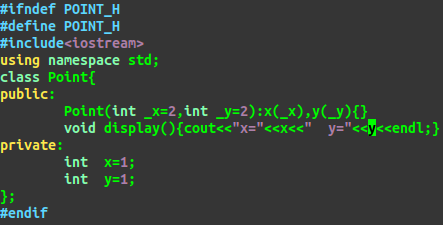
1.按照变量在类内出现的顺序进行初始化,不管你定义构造函数时给出的初始值列表顺序如何。
2.该类型既有类内初始值又在初始值列表中被初始化,那么采用初始值列表中的初始化,如果只
出现其一,那么就用出现的。如果两者都没有,如果该变量是内置类型,则不初始化,如果是
类对象,则执行默认初始化,如果没有默认构造函数则报错。
验证:1.合成的默认构造函数按顺序初始化
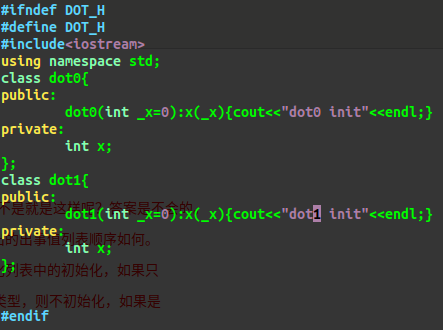

验证2:若类内初始值与初始值列表都有则按初始值列表初始化
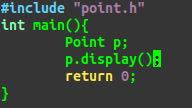

仅将初始值列表去掉
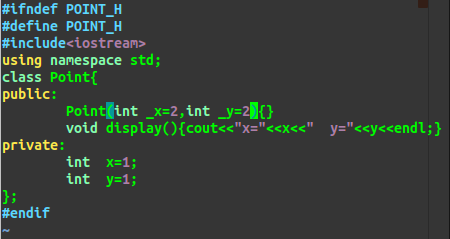

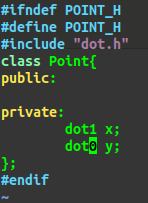
验证三:若某个累的成员变量在构造函数中,既没有类内初始值,也没有在初始值列表内被初始化,
则编译器会在初始值列表内自动调用这个变量的默认构造函数,若没有则报错。
dot类没有默认构造函数:
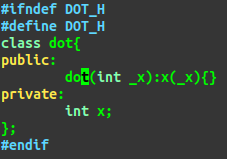
编译器会在初始值列表中试图调用dot的默认构造函数,而dot没有,报错。
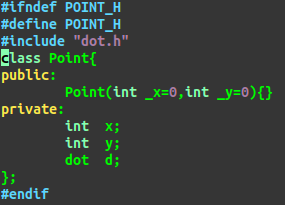
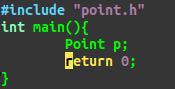
果然如此#^_^:
















explicit 的作用就是阻止了构造函数的调用。不能进行默认转化(即让编译器自动调用相应的构造函数)。所以用explict修饰过得构造函数
只能用于直接初始化。explicit只能用于类内接受一个参数的构造函数的声明。隐式转换,理论上因该是编译器调用某一个构造函数,然后
构造一个临时对象,再利用这个临时对象进行拷贝构造。但事实并非如此,编译器往往不生成临时对象,直接调用构造函数初始化目标对象。
如果目标对象非引用的话。如果目标对象是引用,那么就会生成一个临时对象。而一个临时对象是右值类型,只能绑定const&。
Point p;
这句代码直观上理解我们可能谁都清楚,但是现在我们想要知道,当我们定义一个Point的对象p的时候我们实际都经历了些什么?
第一,在栈上获取了一块内存。
第二,调用了Point的构造函数。
什么?调用了Point的构造函数?Point的构造函数是什么鬼?说好的和Point同样名字的函数怎么没看到呢?嗯,这就是我们要说的
默认构造函数,也就是说,当我们不给我们的类指定构造函数的时候编译器会为我们生成默认的构造函数,而这个函数什么,所以
虽然我们已经构造出一个Point的对象p出来,但是p里面的x和y是未初始化的,所以接下来我们需要针对xy进行各自的初始化,所以
无论出于什么样的理由,我们应该给Point添加相应的构造函数。
//+-----------------
class Point{
public:
Point(double __x = 0.0,double __y = 0.0):x(__x),y(__y){}
private:
double x;
double y;
};
//+-----------------
这次我们不但添加了构造函数,同时还将数据段放在private里面,我们将通过构造函数对数据进行初始化。该构造函数我们使用两个double类型作为参数,
并且两个参数都有默认值,所以我们下面的代码:
Point p;
将等同于:
Point p(0.0,0.0);
此时的x y的值分别都是0.0
:x(__x),y(__y)
在构造函数的括号后面有个冒号,冒号后面跟了一段代码,这段代码叫初始化列表,我们的xy便是在这里进行初始化的,我们使用第一个参数对x进行初始化,
使用第二个参数对y进行初始化。当然我们也可以不适用初始化列表:
//+------------------
class Point{
public:
Point(double __x = 0.0,double __y = 0.0){
x = __x;
y = __y;
}
private:
double x;
double y;
};
//+-------------------
这样的构造函数也是随处可见的,只是这样的写法和上面的写法有些不同(这不是废话吗?只要不瞎一看就是不同),哦!我这里说的不同是指效率上面的不同,
好吧,我们来剖析一下为什么不会不同,我们先来看看要实例化一个类我们所要经历的步骤:
第一,构造数据成员
第二,执行构造函数
所以,在执行构造函数之前xy已经被实例化出来了,所以当我们执行 x = __x 时又经历了一个复杂的过程,这个过程后面细说(但是由于我们此处使用的是基本类
型,所以这个过程也就被忽略啦,如果是自定义类型的话这期间又会有各种问题的产生),所以不管怎么说,我们应该优先选择使用初始化列表的方法来对数据进行初始化。
我们自定义一个类型目的就是为了使用他所封装的数据,但是像我们的Point类就是一个铁公鸡,就是说我们可以将数据放进去,但取不出来,嗯,这是一个问题,解决这个
问题的方法可以将数据段的private提升为public,这可以,但……
//+-----------------
void dealPoint(const Point& p) {
const_cast<Point&>(p).x = 1000;
}
int main()
{
Point p{ 100,200 };
dealPoint(p);
std::cout << p.x << std::endl;
std::cin.get();
return 0;
}
//+----------------
p的x的值直接被修改,当然有些时候我们可能想要这么干,但是这往往会带来意向不到的灾难性后果,因为你不知道什么时候哪根神经搭错了忽然间很想修改这个值。
所以合理的做法应该是我们提供有方法直接访问内部需要访问的东西。
//+----------------
class Point{
public:
Point(double __x = 0.0,double __y = 0.0):x(__x),y(__y){}
double get_x() const{return x;}
double get_y() const{return y;}
void set_x(double __x){x = __x;}
void set_y(double __y){y = __y;}
void set(double __x,double __y){
x = __x;
y = __y;
}
private:
double x;
double y;
};
int main()
{
Point p(200, 300);
std::cout << p.get_x()<<" "<<p.get_y() << std::endl;
std::cin.get();
return 0;
}
//+----------------










复制构造函数
如果我们有一个Point,我们想要当前的Point去构造出一个相同的Point的时候我们应该怎么说呢?
Point p(200, 300);
Point p2(p);
就目前来说,如果我们写出这样的代码,编译通过是完全没问题的,同时运行也不会有任何问题。因为上面的第二句代码执行的并不是默认的构造函数,而是默认的复制构造函数,
什么是复制构造函数呢?
复制构造函数就是函数名和类型一样,没有返回类型,而参数是该类型,如果我们不指定复制构造函数的话那么编译器会为我们的类升成默认的复制构造函数,所以上面的第二行代
码执行的便是复制构造函数,最终是p == p2.
那么怎么编写复制构造函数呢?如下:
//+---------------
class Point{
public:
Point(double __x = 0.0,double __y = 0.0):x(__x),y(__y){}
Point(const Point& p):x(p.x),y(p.y){}
double get_x() const{return x;}
double get_y() const{return y;}
void set_x(double __x){x = __x;}
void set_y(double __y){y = __y;}
void set(double __x,double __y){
x = __x;
y = __y;
}
private:
double x;
double y;
};
//+------------------



赋值操作符
编译器会为class生成的不只有默认的构造函数和默认的复制构造函数,同时还会生成默认的赋值操作,正因为有这个默认的赋值操作符,所以我们下面的代码才会通过编译:
Point p(200,300); // 调用构造函数
Point p2 = p; // 调用复制构造函数
Point p3; // 调用默认的构造函数
p3 = p2 // 调用默认的赋值操作符
如果我们不使用编译器为我们准备的默认操作符的话,我们可以自己编写我们的赋值操作符,赋值操作符是这样的一个函数:
T& operator=(const T& other);
T 是我们的自定义类型。
所以如果我们自己编写赋值操作符,应该这样来:
//+-----------------
class Point{
public:
Point(double __x = 0.0,double __y = 0.0):x(__x),y(__y){}
Point(const Point& p):x(p.x),y(p.y){}
Point& operator=(const Point& other){
if(this == &other)
return *this;
x = other.x;
y = other.y;
return *this;
}
double get_x() const{return x;}
double get_y() const{return y;}
void set_x(double __x){x = __x;}
void set_y(double __y){y = __y;}
void set(double __x,double __y){
x = __x;
y = __y;
}
private:
double x;
double y;
};
//+---------------------
一个空类
//+-----------------
class Empty{};
//+----------------





















当我们写下上面的类的时候,意味着我们写了些什么?
1,默认构造函数。
2,默认的复制构造函数
3,默认的赋值操作符
4,默认取地址操作符(该操作符的重载此处不做解释,熟悉之后自然也就明白了,所以该函数在一般的教科书中是不当作默认实现的函数,因为它本该存在)
5,析构函数
实际等同于:
//+-----------------
class Empty{
public:
Empty(){}
~Empty(){}
Empty(const Empty& other){}
Empty& operator=(const & Empty& other){return *this;}
};
//+-----------------
第一次我们引入析构函数,析构函数和构造函数相对应,构造函数初始化资源,所以析构函数的功能就是清理资源,那么什么时候需要我们自己实现构造函数呢?
那就是当我们有资源需要我们手动释放的时候,比如堆上的指针,比如com对象的Release等等,如果说上面我们所举的Point例子其实是不需要复制操作符和
复制构造函数的话(因为默认的就很好),那么我们现在来说一个我们必须要手赋值制操作符和复制构造函数的例子——字符串处理类,String。
在C++里面字符串有char*表示,但是纯粹的时候char*太过原始,一点都不对象,所以通常都会对char*进行封装,当然想要做一个完备的字符串类出来可不是一件简单的事,
所以这里只是作为一个例子,我们仅仅实现一些简单的操作即可:
//+------------------
//
// 简单的字符串处理类
//
class String{
public:
//
// 构造函数
//
String(const char* str = "") :mData(nullptr){
int len = strlen(str) + 1;
mData = new char[len];
memset(mData, 0, len );
memcpy(mData, str, len - 1);
}
//
// 析构函数
// 该函数绝不能使用缺省的,我们必须手动释放资源
//
~String(){
if (mData){
delete[] mData;
mData = nullptr;
}
}
//
// 复制构造函数
// 该函数不能使用缺省的,我们必须手动拷贝资源
//
String(const String& str):mData(nullptr){
int len = str.size();
len += 1;
mData = new char[len];
memset(mData, 0, len);
memcpy(mData, str.mData, len - 1);
}
//
// 赋值操作符
// 该函数不能使用缺省的,我们必须手动拷贝资源
//
String& operator=(const String& str){
if (this == &str){
return *this;
}
if (mData != nullptr){
delete[] mData;
mData = nullptr;
}
int len = str.size();
len += 1;
mData = new char[len];
memset(mData, 0, len);
memcpy(mData, str.mData, len - 1);
return *this;
}
//
// 获取字符串长度
//
unsigned size() const{
if (mData == nullptr){
return 0;
}
return strlen(mData);
}
//
// 下标操作符
//
char& operator[](unsigned index){
if (mData == nullptr || index >= size()){
throw std::out_of_range("operator[](unsigned index)");
}
return mData[index];
}
const char& operator[](unsigned index) const{
return const_cast<String*>(this)->operator[](index);
}
//
// 检查字符串是否为空
//
bool empty() const{
return this->size() == 0;
}
//
// 支持流的输出
//
friend std::ostream& operator<<(std::ostream& os, const String& str){
if (str.empty()){
return os;
}
os << str.mData;
return os;
}
private:
char* mData{ nullptr };
};
//
// 测试代码
//
int main(){
String str("Hello World");
std::cout <<"str = "<< str << std::endl;
String str2 = str;
std::cout << "str2 = " << str2 << std::endl;
String str3;
std::cout << str3.empty() << std::endl;
std::cout << str2.size() << std::endl;
str3 = str2;
str3[2] = 'H';
std::cout << str3.empty() << std::endl;
std::cout << str3 << std::endl;
system("pause");
return 0;
}
//+------------------
字符串的操作属于最基本的操作,但同时也是最有讲究的操作,几乎每一个相对完善的C++类库都提供有字符串处理类,比如标准库中的string,MFC和ATL的CString,
Qt的QString,CEGUI的String,DuiLib的DuiString等等,所以字符串的处理虽然是基本的操作,却也是最为重要的操作,网上流传的C++面试题中更是将字符串的实现
作为一大考点,当然这不足为奇,因为要是现在一个完备的字符串类,需要考虑到方方面面的东西,后续我们会提供一个功能强大的字符串类,那么余下的就由各位去思考。
右值引用与移动语义
1.介绍
Rvalue引用至少结决了两个问题
1.实现移动语义
2.完美转发
rvalue lvalue没有明确的定义,大致定义如下:
lvalue:可以取地址
rvalue:不可取地址
// lvalues:
// int i = 42; i = 43; // ok, i is an lvalue int* p = &i; // ok, i is an lvalue int& foo(); foo() = 42; // ok, foo() is an lvalue int* p1 = &foo(); // ok, foo() is an lvalue // rvalues: // int foobar(); int j = 0; j = foobar(); // ok, foobar() is an rvalue int* p2 = &foobar(); // error, cannot take the address of an rvalue j = 42; // ok, 42 is an rvalue
2.移动语义
假设X是一个类,它持有一个指向指向某种资源的指针或句柄,m_pResource.我的意思是说需要大量努力去构建,
拷贝或销毁的类。一个不错的例子是std::vector,它保存了一个对象的集合,存在于一个分配的内存数组中。从逻辑上
讲,x的拷贝赋值运算符是这样的:
X& X::operator=(X const & rhs)
{
//[..]
//Destruct the resource that m_pResource refers to
//Make a clon of what rhs.m_pResource refers to
//Attach the clone to m_pResource
//[...]
}
拷贝构造函数也是一样的原理。我们以以下的方式使用X:
X foo();
X x;
//perhaps use x in various ways
x=foo();
最后一行包含以下步骤:
·destructs the resource held by x
·clones the resource from the temporary returned by foo
·destructs the temporary and thereby releases its resource
很明显,交换资源指针(句柄)在x和临时对象之间是可以的,而且更有效率,然后让临时对象析构函数破坏x的原始资源。
换句话说,在特殊情况下,赋值的右端是一个rvalue,我们希望复制赋值运算符像这样运行:
// [...]
// swap m_pResource and rhs.m_pResource
// [...]
这就叫做移动语义。在c++11里,这种理想的行为能够被实现通过重载。
X& X::operator=(<mystery type> ths)
{
//[...]
//swap this->m_pResource and ths.m_pResource
//[...]
}
我们定义了一个拷贝赋值运算符的重载,我们的"mystery type"本质上必须是一个引用:我们希望mystery type
3.右值引用
如果X是任意类型,那么X&&被称为X的右值引用。为了更好的区分,普通的引用X&现在被称为左值引用。
右值引用在许多行为上与普通的引用X&是类似的,当然有部分是不同的。其中最最大的一个不同就是涉及到重载时,
左值更喜欢普通的左值引用,然而右值更喜欢新的右值引用
void foo(X& x); // lvalue reference overload void foo(X&& x); // rvalue reference overload X x; X foobar(); foo(x); // argument is lvalue: calls foo(X&) foo(foobar()); // argument is rvalue: calls foo(X&&)
所以,它的要点是:
右值引用允许一个函数(我是被左值调用还是右值调用)用重载解析来进行绑定。
你当然可以再任何情况下以这种方式重载函数,比如上面的例子,但是在绝大多数情况下这种重载应该发生在拷贝构造和
拷贝赋值运算符上,以实现移动语义。
X& X::operator=(X const & rhs); // classical implementation X& X::operator=(X&& rhs) { // Move semantics: exchange content between this and rhs return *this; }
为拷贝构造函数实现一个右值引用的重载时类似的。
注意:正像c++中大多数的情况一样,乍一看上去是完美的。但在某些情况下,在拷贝赋值操作符的实现中,这样简单的交换this
和rhs并不完美。我们将在第四部分回到这个话题:强制移动语义。
Note: If you implement
void foo(X&);but not void foo(X&&);then of course the behavior is unchanged: foo can be called on l-values, but not on r-values. If you implement
void foo(X const &);but not void foo(X&&);then again, the behavior is unchanged: foo can be called on l-values and r-values, but it is not possible to make it distinguish between l-values and r-values. That is possible only by implementing
void foo(X&&);as well. Finally, if you implement void foo(X&&);but neither one of void foo(X&);and void foo(X const &);then, according to the final version of C++11, foo can be called on r-values, but trying to call it on an l-value will trigger a compile error. |
4.强制移动语义
众所周知,正如C++标准的第一修正案所陈述:“委员会不会建立任何试图绊住C++程序员的脚的规则。(The committee shall make no rule that prevents C++ programmers from shooting themselves in the foot.)”,正经来说,就是当面临给予程序员更多控制还是减少他们粗心大意机会的选择时,C++更倾向于及时可能导致犯错,但是依然给予更多控制。正是基于这种精神,C++11允许你使用Move语义而不仅仅局限于是右值,而是还有左值,这都给与你充分的决定权。一个好的例子就是标准库里面的swap方法。同以前一样,给出一个类X,基于它我们可以重载拷贝构造函数和拷贝赋值操作符来在右值上面实现Move语义。

template<class T>
void swap(T& a, T& b)
{
T tmp(a);
a = b;
b = tmp;
}
X a, b;
swap(a, b);
这里并没有右值。所以,在swap函数中的三行没有使用move语义。但是我们知道使用move语义是可行的:任何时候当一个变量作为源头出现在一个拷贝构造函数或者赋值语句的时候,那个变量将不会再被使用,或者仅仅被作为赋值的目标。
在C++11中,标准库中有一个叫做std::move的方法用来处理这种情况。这个函数只是将他的参数变成右值。因此,在C++11中,标准库函数swap将会像如下所示:
template<class T>
void swap(T& a, T& b)
{
T tmp(std::move(a));
a = std::move(b);
b = std::move(tmp);
}
X a, b;
swap(a, b);
现在所有在swap函数中的三行都使用了move语义。记住对于没有实现move语义的类型(也就是说,并没有为右值单独重载一个拷贝构造函数和赋值表达式的类型),新的swap行为表现同旧的版本是一致的(注:其实严谨的来讲,只有在参数前加上const才一致。单纯的左值引用不能绑定在一个右值上)。
std::move是一个非常简单的函数。不幸的是,尽管如此,我还不能将它的实现展现给你。我们将会在后面讨论它。
在任何能使用std::move的地方使用它。如上面的swap函数所示,它给我们带来如下好处:
- 对于实现了move语义的类型而言,需要标准库算法和操作将会使用move语义,然后因此得到潜在的性能提升。一个重要的例子就是原地排序(inplace sorting):原地排序算法就是单纯的交换元素,其他什么都不做,然后现在交换的过程将会在提供了move语义的类型中,充分利用到move语义提供的优势。
- 标准模板库(STL)经常需要有些类型提供拷贝能力(copyability)。例如可以被用做容器元素的类型。通过严格的观察,事实证明,在很多情况下,移动能力(moveability)就足够了。因此,我们现在可以在某些以前并不被允许的地方使用可移动的而不是可复制的类型了(譬如
unique_pointer)。举例来说,这些类型现在可以被使用做标准模板库的容器类型了。
既然我们知道了std::move,我就就需要知道为什么实现一个基于右值引用的拷贝赋值表达式的重载,如同前面我所展示的,依然是有些问题的。考虑一个简单的变量间的赋值,像这样:
a = b;
你期待在这里发生什么?你期待被a持有的对象被一份b的拷贝所替代,当然在整个交换过程中,你期待原来被a持有的对象会被析构。现在考虑这行代码:
a = std::move(b);
如果move语义被实现为一个简单的交换,那么这里的表现就将会是被a和b持有的对象将在a和b间交换。没有任何东西被析构。当然原来被a持有的对象将会最终被析构,也就是说,当b离开了该代码的范围时。当然,除非b成为move的对象,在这种情况下,原来被a持有的对象又再次得到了一次。因此,只有拷贝赋值表达式的实现被精心考虑过后,我们并不知道原来被a持有的对象何时将被析构。
所以在某种意义上,我们在这里将会陷入到不确定性的泥沼中:一个变量被分配后,但是原来被该变量持有的对象却还在其他位置。只有那个对象的析构函数并不会对外面有任何副作用的时候才是可行的。但是某些时候,析构函数确实会有这种副作用。一个例子就是在析构函数中释放一个锁。因此,析构函数中任何可能含有副作用的部分应该在拷贝赋值操作符的右值引用重载中清晰地表现出来:
X& X::operator=(X&& rhs)
{
// 执行一次清理,要注意到那些在析构函数中可能产生副作用的地方。
// 确保对象处于可析构的和可赋值的状态
// Move语义,交换this和rhs的内容
return *this;
}
5.右值引用就是右值吗?
同之前一样,给出一个X类,让我们可以重载它的拷贝构造函数和拷贝赋值操作符来实现move语义。现在做如下考虑:
void foo(X&& x)
{
X anotherX = x;
// ...
}
一个有趣的问题就是,在foo函数内,哪一个x的拷贝构造函数重载将会被调用。这里,x是一个被声明为右值引用的变量,也就是说,一个在一般情况下或者在更好的情况下(即使并不是必须的)指代一个右值。因此,也许可以期待x本身应该像是一个右值绑定,也就是说:
X(X&& rhs);
应该被调用。换另一种说法,一个人可能会期待任何被声明为右值引用的,其本身也是一个右值。然后右值引用的设计者们采取了更为微妙的一种解决方案:
被声明为右值引用的可能既是左值也可能是右值。这里判断的标准在于:如果它有名字,那么它就是左值。否则就是右值。
就上面的例子,被声明为右值引用的有了一个名字,那么因此它是一个左值:
void foo(X&& x)
{
X anotherX = x; // 调用 X(X const & rhs)
}
这里就是一个被声明为右值引用并且并没有名字,因此它是一个右值:
X&& goo();
X x = goo(); // 调用 X(X&& rhs) 因为在表达式的右手边
// 并没有名字
这里有关于这种设计的原理阐述:假设默许move语义发生在一个有名字的东西上面,如下:
X anotherX = x; // x依然在作用域内!
将是十分危险且混乱的,并且是很容易出错的。因为我们刚刚移动的东西,依然在随后的代码中可以被访问到。但是move语义的整个要点在于它就是应用在那些并不用在意移动后的情况的对象上,严格意义上而言,那些我们从它那里移动后会销毁并且放任不管是没有问题的。因此才有了这个规则:“如果它有个名字,那么它是一个左值。”
这里有一个例子显示了「如果它有一个名字规则」的重要性。假设你已经写了一个叫做Base的类,然后你通过重载Base的拷贝构造函数和赋值操作符来实现move语义。
Base(Base const & rhs); // 非move语义 Base(Base&& rhs); // move语义
现在你写了一个Derived的类,他继承于Base。为了保证move语义被实施在Derived对象的Base部分,你必须也同时重载Derived的拷贝构造函数和赋值操作符。让我们来看一下拷贝构造函数,拷贝赋值操作符的处理是类似的。对应于左值的版本比较简单直接:
Derived(Derived const & rhs)
: Base(rhs)
{
// 针对Derived特定的操作
}
对应于右值的版本有一个很大的微妙的不同。下面就是有人没有意识到「如果它有一个名字规则」可能写出来的:
Derived(Derived&& rhs)
: Base(rhs) // 错误:rhs是一个左值
{
// 针对Derived特定的操作 f
}
如果我们像那样写代码,那么non-moving的Base拷贝构造函数的版本将会被调用,因为rhs有一个名字,是一个左值。我们想要调用的是Base的moving构造函数,我们需要这样写:
Derived(Derived&& rhs)
: Base(std::move(rhs)) // 好,调用Base(Base&& rhs)
{
// 针对Derived特定的操作
6.Move语义和编译器优化
考虑下面这样的函数定义:
X foo()
{
X x;
// perhaps do something to x
return x;
}
现在同以前一样进行假设,给出一个X类,我们可以通过重载它的拷贝构造函数和拷贝赋值操作符来实现move语义。如果你看了一眼上面的函数定义的话,你可能会禁不住说:「等一下,这里有一份从x到foo函数返回值位置的值拷贝。让我来确定我们使用了move语义」:
X foo()
{
X x;
// perhaps do something to x
return std::move(x); // making it worse!
}
不幸的是,这不仅不会让事情变好,可能会变得更糟。任何现代的编译器均可对原始的函数定义实现返回值优化(return value optimization)。另一种说法,并不是在本地构造x然后将它拷贝出,而是编译器会在foo的返回值的位置直接构造x对象。很明显,这会比使用move语义更好。
所以你看,为了确切地有效地利用好右值引用和move语义,你需要充分理解并且对现在的编译器的各种「优化」有充分的考量,类似于返回值优化和复制省略(copy elision)。Dave Abrahams在这方面写了一系列文章,可以参见这里:http://cpp-next.com/archive/2009/08/want-speed-pass-by-value/。这些细节可能都很微妙,但是,我们选择C++作为我们的编程语言是有原因的,对吧?我们选择了它,那么我们就应该认真对待它

左值 右值
可取地址 不可取地址
有名字 无名子
持久 短暂
左值引用只可绑定左值
右值引用只可绑定右值
const类型的左值引用既可绑定左值,又可绑定右值





























