摘要:之前虽然对集合框架一些知识点作了总结,但是想想面试可能会问源码,于是又大致研究了一下集合框架的一些实现类的源码,在此整理一下。
一.集合框架
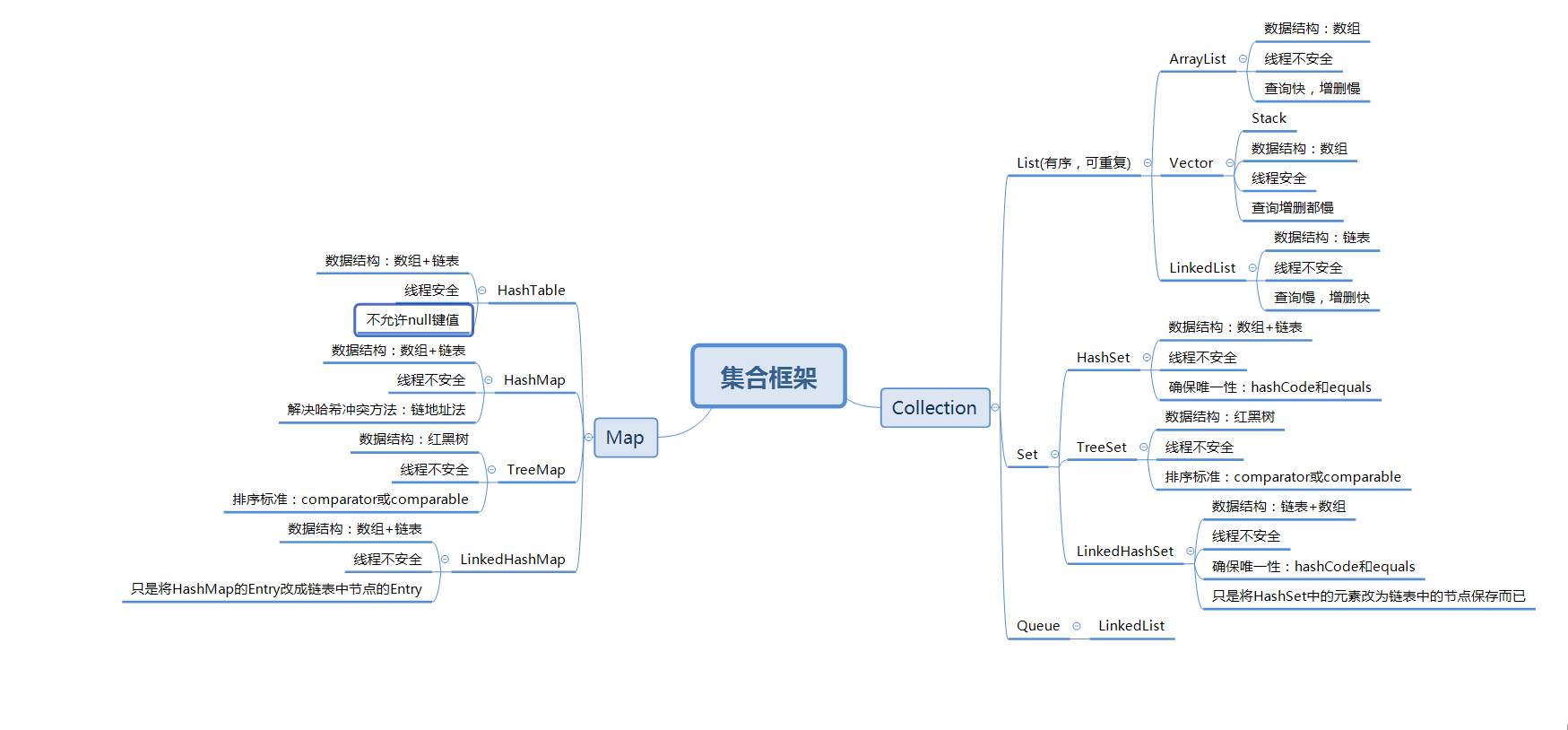
二.深究实现类
1.ArrayList源码实现
ArrayList内部维护了一个动态数组,如果没有显式的初始化的话,动态数组的默认容量是10,当数组容量已满时,每次将容量扩大至1.5倍加1。
ArrayList的remove、add、clear等方法的实现原理都是对内部的Object数组进行操作,需要注意的是,在add方法执行前,都会提前对数组的容量进行确认,如果已满,则先进行扩容,此处很简单,就不对源码进行解析了。
需要注意的是有一个方法trimToSize,这个方法的作用是去掉预留位置,在内存紧张时会用到。


/** * Returns the element at the specified position in this list. * * @param index index of the element to return * @return the element at the specified position in this list * @throws IndexOutOfBoundsException {@inheritDoc} */ public E get(int index) { rangeCheck(index); return elementData(index); } /** * Replaces the element at the specified position in this list with * the specified element. * * @param index index of the element to replace * @param element element to be stored at the specified position * @return the element previously at the specified position * @throws IndexOutOfBoundsException {@inheritDoc} */ public E set(int index, E element) { rangeCheck(index); E oldValue = elementData(index); elementData[index] = element; return oldValue; } /** * Appends the specified element to the end of this list. * * @param e element to be appended to this list * @return <tt>true</tt> (as specified by {@link Collection#add}) */ public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; } /** * Inserts the specified element at the specified position in this * list. Shifts the element currently at that position (if any) and * any subsequent elements to the right (adds one to their indices). * * @param index index at which the specified element is to be inserted * @param element element to be inserted * @throws IndexOutOfBoundsException {@inheritDoc} */ public void add(int index, E element) { rangeCheckForAdd(index); ensureCapacityInternal(size + 1); // Increments modCount!! System.arraycopy(elementData, index, elementData, index + 1, size - index); elementData[index] = element; size++; } /** * Removes the element at the specified position in this list. * Shifts any subsequent elements to the left (subtracts one from their * indices). * * @param index the index of the element to be removed * @return the element that was removed from the list * @throws IndexOutOfBoundsException {@inheritDoc} */ public E remove(int index) { rangeCheck(index); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // clear to let GC do its work return oldValue; } /** * Removes the first occurrence of the specified element from this list, * if it is present. If the list does not contain the element, it is * unchanged. More formally, removes the element with the lowest index * <tt>i</tt> such that * <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt> * (if such an element exists). Returns <tt>true</tt> if this list * contained the specified element (or equivalently, if this list * changed as a result of the call). * * @param o element to be removed from this list, if present * @return <tt>true</tt> if this list contained the specified element */ public boolean remove(Object o) { if (o == null) { for (int index = 0; index < size; index++) if (elementData[index] == null) { fastRemove(index); return true; } } else { for (int index = 0; index < size; index++) if (o.equals(elementData[index])) { fastRemove(index); return true; } } return false; }
2.Vector源码实现
Vector同ArrayList相同,也是内部维护了一个动态数组,数组默认长度是10,但是扩容方案与ArrayList有所不同,Vector扩容后的容量取决于扩容因子capacityIncremen和旧数组容量oldCapacity,法则如下:int newCapacity = (capacityIncrement > 0) ?(oldCapacity + capacityIncrement) : (oldCapacity * 2),注意:在计算出新数组尺寸后,还要与Vector类内部定义的最小值和最大值进行比较,如果超过上下限,那么新数组容量就等于上下限。另外,如果初始化时未传入扩容因子,那么扩容因子默认为0。
Vector的基本增删等操作的实现原理与ArrayList相同,都是简单的对数组进行操作。
Vector是线程安全的,实现的方式就是在基本操作的方法添加了synchronized关键字进行修饰,这样就确保了这个方法只能在同一时刻只能被一个线程访问,从而保证了多线程访问的安全性。
Vector内部也实现了迭代器,不过是用Enumeration来实现的。
public Enumeration<E> elements() { return new Enumeration<E>() { int count = 0; public boolean hasMoreElements() { return count < elementCount; } public E nextElement() { synchronized (Vector.this) { if (count < elementCount) { return elementData(count++); } } throw new NoSuchElementException("Vector Enumeration"); } }; }
3.LinkedList
LinkedList内部通过一个双向链表实现,每一个传入的对象都会转化为一个Node节点(Entry和Node都是通过一个内部类实现的),LinkedList的增删基本操作的实现就是通过对链表的节点地址赋值或置null来实现的,具体是link和unlink类似的方法。
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } } public boolean add(E e) { linkLast(e); return true; } public boolean remove(Object o) { if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); return true; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); return true; } } } return false; }
4.HashSet
HashSet内部是通过HashMap底层来实现的,只不过是将HashMap的value全部赋值为一个常量Object对象,内部的增删等方法都是直接调用hashMap的方法,故在此不做赘述,等HashMap再深入分析。
private transient HashMap<E,Object> map; private static final Object PRESENT = new Object(); public boolean add(E e) { return map.put(e, PRESENT)==null; } public boolean remove(Object o) { return map.remove(o)==PRESENT; }
5.TreeSet
TreeSet内部是通过TreeMap底层来实现的,与HashSet相同,都是将value设定成一个常量。
6.HashMap
HashMap底层是通过数组加链表的数据结构实现的,为什么使用数据加链表的形式呢?这就引出了一个很重要的问题,就是哈希冲突的问题,我们都知道,对于hashXXX这种实现类,确保key唯一性的方法就是hashCode和equals方法,当往HashMap中存入元素时,会先依据元素的哈希值找到这个元素在数组中的位置(哈希值与数组中的索引一一对应),如果当前位置已经存在然后对key进行比较,如果相同的话,那么把更新key的value,如果不同的话,就会造成哈希冲突的问题,那么HashMap是如何解决哈希冲突的问题呢?答案是链地址法。

如上图所示即为HashMap的存储结构,HashMap内部会将每一个存储的元素转化为一个Node,这个Node有三个属性,分别是hash、key、value、next,以put方法为例,当插入元素时,首先对key求解对应得哈希值,找到bucket的位置,然后查看该位置上有无元素,如果没有,直接插入;如果有,运用equels方法在此对key进行判断,如果有相同Key则更新,否则插入,注意插入顺序依次往后延。这样就解决了哈希冲突的问题。
7.TreeMap
TreeMap内部维系了红黑树,TreeMap会将每一个元素转化为Entry,Entry有五个重要的属性:key、value、left、right、parent。大体流程如下:以put操作为例,每当插入元素时,都会对元素的key进行排序,如果大于当前节点值就放到左子树,否则右子树,不断循环,直到变成叶子节点,往往排序完成后,整个树的结构就不满足红黑树的标准l了,所以每次方法调用结束都会执行fixAfterInsertion方法对树进行调整,以达到红黑树的要求。
排序的准则有两种,一种是元素自身具备比较性,另一种是提供一个比较器。
1.如何让元素自身具备比较性?实现comparable接口,重写conpareto方法
2.比较器的建立:实现comparator接口,重写conpare方法,并且在实例化一个TreeMap时,将此比较器作为形参传入。
如要注意的是,TreeMap内部在排序时,会先判断是否有比较器,如果有,那么就不会去检查元素自身是否具有比较性了。
public V put(K key, V value) { Entry<K,V> t = root; if (t == null) { compare(key, key); // type (and possibly null) check root = new Entry<>(key, value, null); size = 1; modCount++; return null; } int cmp; Entry<K,V> parent; // split comparator and comparable paths Comparator<? super K> cpr = comparator; if (cpr != null) { do { parent = t; cmp = cpr.compare(key, t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } else { if (key == null) throw new NullPointerException(); @SuppressWarnings("unchecked") Comparable<? super K> k = (Comparable<? super K>) key; do { parent = t; cmp = k.compareTo(t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } Entry<K,V> e = new Entry<>(key, value, parent); if (cmp < 0) parent.left = e; else parent.right = e; fixAfterInsertion(e); size++; modCount++; return null; }
8.LinkedHashMap
LinkedHashMap与HashMap有着同样的存储结构,但它加入了一个双向链表的头结点,将所有put到LinkedHashmap的节点一一串成了一个双向循环链表,因此它保留了节点插入的顺序,可以使节点的输出顺序与输入顺序相同。
******************************分割线*******************************
转一篇很好的有关HashMap的小文章
HashMap的工作原理是近年来常见的Java面试题。几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道Hashtable和HashMap之间的区别,那么为何这道面试题如此特殊呢?是因为这道题考察的深度很深。这题经常出现在高级或中高级面试中。投资银行更喜欢问这个问题,甚至会要求你实现HashMap来考察你的编程能力。ConcurrentHashMap和其它同步集合的引入让这道题变得更加复杂。让我们开始探索的旅程吧!
先来些简单的问题
“你用过HashMap吗?” “什么是HashMap?你为什么用到它?”
几乎每个人都会回答“是的”,然后回答HashMap的一些特性,譬如HashMap可以接受null键值和值,而Hashtable则不能;HashMap是非synchronized;HashMap很快;以及HashMap储存的是键值对等等。这显示出你已经用过HashMap,而且对它相当的熟悉。但是面试官来个急转直下,从此刻开始问出一些刁钻的问题,关于HashMap的更多基础的细节。面试官可能会问出下面的问题:
“你知道HashMap的工作原理吗?” “你知道HashMap的get()方法的工作原理吗?”
你也许会回答“我没有详查标准的Java API,你可以看看Java源代码或者Open JDK。”“我可以用Google找到答案。”
但一些面试者可能可以给出答案,“HashMap是基于hashing的原理,我们使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,返回的hashCode用于找到bucket位置来储存Entry对象。”这里关键点在于指出,HashMap是在bucket中储存键对象和值对象,作为Map.Entry。这一点有助于理解获取对象的逻辑。如果你没有意识到这一点,或者错误的认为仅仅只在bucket中存储值的话,你将不会回答如何从HashMap中获取对象的逻辑。这个答案相当的正确,也显示出面试者确实知道hashing以及HashMap的工作原理。但是这仅仅是故事的开始,当面试官加入一些Java程序员每天要碰到的实际场景的时候,错误的答案频现。下个问题可能是关于HashMap中的碰撞探测(collision detection)以及碰撞的解决方法:
“当两个对象的hashcode相同会发生什么?” 从这里开始,真正的困惑开始了,一些面试者会回答因为hashcode相同,所以两个对象是相等的,HashMap将会抛出异常,或者不会存储它们。然后面试官可能会提醒他们有equals()和hashCode()两个方法,并告诉他们两个对象就算hashcode相同,但是它们可能并不相等。一些面试者可能就此放弃,而另外一些还能继续挺进,他们回答“因为hashcode相同,所以它们的bucket位置相同,‘碰撞’会发生。因为HashMap使用链表存储对象,这个Entry(包含有键值对的Map.Entry对象)会存储在链表中。”这个答案非常的合理,虽然有很多种处理碰撞的方法,这种方法是最简单的,也正是HashMap的处理方法。但故事还没有完结,面试官会继续问:
“如果两个键的hashcode相同,你如何获取值对象?” 面试者会回答:当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,然后获取值对象。面试官提醒他如果有两个值对象储存在同一个bucket,他给出答案:将会遍历链表直到找到值对象。面试官会问因为你并没有值对象去比较,你是如何确定确定找到值对象的?除非面试者直到HashMap在链表中存储的是键值对,否则他们不可能回答出这一题。
其中一些记得这个重要知识点的面试者会说,找到bucket位置之后,会调用keys.equals()方法去找到链表中正确的节点,最终找到要找的值对象。完美的答案!
许多情况下,面试者会在这个环节中出错,因为他们混淆了hashCode()和equals()方法。因为在此之前hashCode()屡屡出现,而equals()方法仅仅在获取值对象的时候才出现。一些优秀的开发者会指出使用不可变的、声明作final的对象,并且采用合适的equals()和hashCode()方法的话,将会减少碰撞的发生,提高效率。不可变性使得能够缓存不同键的hashcode,这将提高整个获取对象的速度,使用String,Interger这样的wrapper类作为键是非常好的选择。
如果你认为到这里已经完结了,那么听到下面这个问题的时候,你会大吃一惊。“如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?”除非你真正知道HashMap的工作原理,否则你将回答不出这道题。默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
如果你能够回答这道问题,下面的问题来了:“你了解重新调整HashMap大小存在什么问题吗?”你可能回答不上来,这时面试官会提醒你当多线程的情况下,可能产生条件竞争(race condition)。
当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。这个时候,你可以质问面试官,为什么这么奇怪,要在多线程的环境下使用HashMap呢?:)
热心的读者贡献了更多的关于HashMap的问题:
- 为什么String, Interger这样的wrapper类适合作为键? String, Interger这样的wrapper类作为HashMap的键是再适合不过了,而且String最为常用。因为String是不可变的,也是final的,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不可变性还有其他的优点如线程安全。如果你可以仅仅通过将某个field声明成final就能保证hashCode是不变的,那么请这么做吧。因为获取对象的时候要用到equals()和hashCode()方法,那么键对象正确的重写这两个方法是非常重要的。如果两个不相等的对象返回不同的hashcode的话,那么碰撞的几率就会小些,这样就能提高HashMap的性能。
- 我们可以使用自定义的对象作为键吗? 这是前一个问题的延伸。当然你可能使用任何对象作为键,只要它遵守了equals()和hashCode()方法的定义规则,并且当对象插入到Map中之后将不会再改变了。如果这个自定义对象时不可变的,那么它已经满足了作为键的条件,因为当它创建之后就已经不能改变了。
- 我们可以使用CocurrentHashMap来代替Hashtable吗?这是另外一个很热门的面试题,因为ConcurrentHashMap越来越多人用了。我们知道Hashtable是synchronized的,但是ConcurrentHashMap同步性能更好,因为它仅仅根据同步级别对map的一部分进行上锁。ConcurrentHashMap当然可以代替HashTable,但是HashTable提供更强的线程安全性。看看这篇博客查看Hashtable和ConcurrentHashMap的区别。
我个人很喜欢这个问题,因为这个问题的深度和广度,也不直接的涉及到不同的概念。让我们再来看看这些问题设计哪些知识点:
- hashing的概念
- HashMap中解决碰撞的方法
- equals()和hashCode()的应用,以及它们在HashMap中的重要性
- 不可变对象的好处
- HashMap多线程的条件竞争
- 重新调整HashMap的大小
总结
HashMap的工作原理
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。
当两个不同的键对象的hashcode相同时会发生什么? 它们会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对。
因为HashMap的好处非常多,我曾经在电子商务的应用中使用HashMap作为缓存。因为金融领域非常多的运用Java,也出于性能的考虑,我们会经常用到HashMap和ConcurrentHashMap。你可以查看更多的关于HashMap的文章:
原文链接: Javarevisited 翻译: ImportNew.com - 唐小娟
译文链接: http://www.importnew.com/7099.html