变量定义
package main
import "fmt"
func main(){
// 变量定义:var
// 常量定义:const
// 变量定义的方式,1.先定义变量,再赋值
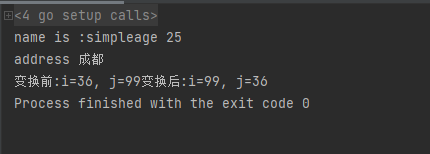
var name string
name = "simple"
fmt.Printf("name is :%s",name)
// 变量定义的方式,2.定义时,直接复制
var age int = 25
fmt.Println("age",age)
// 变量定义的方式,3. 定义直接赋值,使用自动推导(最常用)
address := "成都"
fmt.Println("address",address)
// 平行赋值,相当于同时定义两个变量
i, j := 36, 99
fmt.Printf("变换前:i=%d, j=%d",i,j)
i, j = j, i
fmt.Printf("变换后:i=%d, j=%d",i,j)
}
基础数据类型
整型(int)
var i = 123
var i8 = int8 123
var i16 = int16 123
var i32 = int32 123
var i64 = int64 123
浮点型(float)
var f = 123.0
var f32 = 123
var f64 = 123
布尔类型(bool)
var b = false
b = true
字符串(string)
package main
import "fmt"
func main() {
// 定义
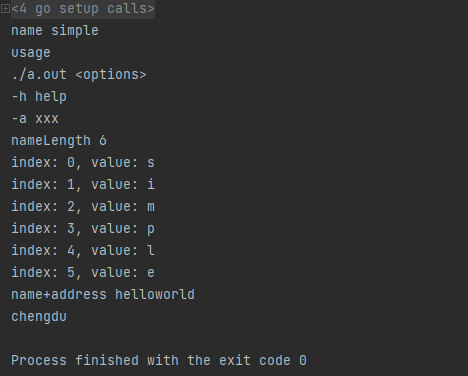
name := "simple"
// 需要换行,原生输出字符串时,使用反引号``
usage := `
./a.out <options>
-h help
-a xxx`
fmt.Println("name",name)
fmt.Println("usage",usage)
// 长度,访问
// C++ :name.length,可以通过这种方式来查看字符串的长度
// Go:string没有.length扩展函数,可以使用自由函数len()来处理
nameLength := len(name)
fmt.Println("nameLength",nameLength)
// 通过循环访问字符串下标,注意for循环不需要加()
for i:=0; i<len(name);i++{
fmt.Printf("index: %d, value: %c
",i, name[i])
}
// 字符串拼接
name, address := "hello","world"
fmt.Println("name+address",name+address)
// 使用const修饰为常量,不能修改,且赋值必须使用=不能使用:=
const city = "chengdu"
fmt.Println(city)
}
数组
定长数组
和C家族语言一样,指定一个数组长度,然后依次写入
package main
import "fmt"
func main() {
// 定义一个具有10个数字的数组
// C语言:int nums[10] = {1, 2, 3}
// Go语言方式1:nums := [10]int{1,2,3,4}(推荐使用这种方式)
// Go语言方式2:var nums = [10]int{1, 2, 3}
// Go语言方式3:var nums [10]int = [10]int{1, 2, 3}
// 传统方式遍历数组
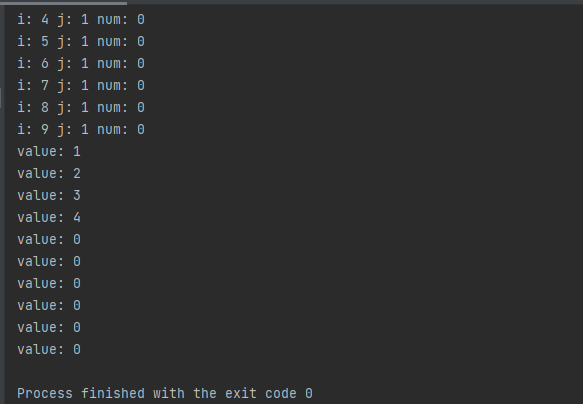
nums := [10]int{1, 2, 3, 4}
for i := 0; i < len(nums); i++{
fmt.Println("i:", i, "j:", nums[i])
}
// 通过for range方式遍历数组
// key是数组下表,value是数组的值
for key, value := range nums{
// key = 0, value = 1 => nums[0]
// value 全程只是一个临时变量,不断地被重新赋值,修改它不会修改原始数组
value += 1
fmt.Println("i:", key, "j:",value, "num:",nums[key])
}
// 在Go语言中,如果想忽略一个值,可以使用_
// 如果都忽略,那么就不能使用:=,而应该直接使用=,因为Golang无法做到自动推导
for _, value := range nums{
fmt.Println("value:",value)
}
}
不定长数组
切片
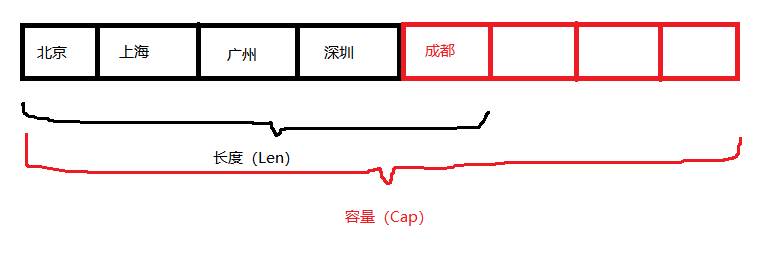
- 切片:slice,它的底层也是数组,可以动态改变长度
- 可以使用append进行追加数据
- len获取长度,cap获取容量
- 如果容量不足,再次追加数据,会动态分配2倍空间
package main
import "fmt"
func main() {
// 切片:slice,它的底层也是数组,可以动态改变长度
// 定义一个切片,包含多个地名
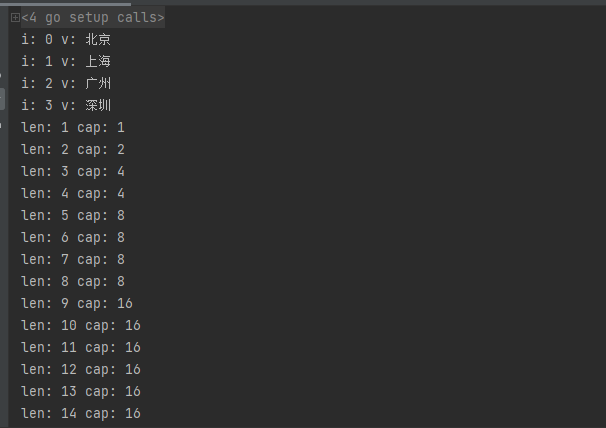
names := []string{"北京","上海","广州","深圳"}
for i, v := range names{
fmt.Println("i:",i,"v:",v)
}
// 追加数据到一个新的变量
// names2 := append(names,"成都")
// fmt.Println("names:",names)
// fmt.Println("name2:",names2)
// 追加元素后赋值给自己
// fmt.Println("names:",names)
// names = append(names,"成都")
// fmt.Println("names:",names)
// 对于一个切片,不仅有长度的概念len(),还有容量的概念cap()
// fmt.Println("追加元素前,name的长度:",len(names),",容量:",cap(names))
// names = append(names,"成都")
// fmt.Println("追加元素后,name的长度:",len(names),",容量:",cap(names))
nums := []int{}
for i := 0; i < 50; i++{
nums = append(nums, i)
fmt.Println("len:",len(nums),"cap:",cap(nums))
}
}
make、copy、数组浅拷贝和深拷贝
package main
import (
"fmt"
)
func main() {
names := [7]string{"北京","上海","广州","深圳","成都","重庆","天津"}
// 基于names变量创建一个新的数组,数组仅包含"北京"、"上海"、"广州"
// 传统做法
name1 := [3]string{}
name1[0] = names[0]
name1[1] = names[1]
name1[2] = names[2]
fmt.Println("name1",name1)
// 通过切片可以基于一个数组,灵活的创建新的数组
// 如果从0坐标开始截取,那么冒号左边的数组可以省略
// name2 := names[:5]
// 如果截取到数组最后一个元素,那么冒号右边的数字可以省略
// name2 := names[3:]
// 如果想从左至右全部使用,那么冒号左右的数字都可以省略
// name2 := names[:]
name2 := names[0:3] // 左闭右开
fmt.Println("name2:",name2)
// 由于name2和names指向的内存地址相同,当修改完name2之后,names的值也会改变
// 如果想修改name2的值之后不修改names的值,可以使用深拷贝copy之后再修改
name2[2] = "合肥"
fmt.Println("修改name2[2]之后,name2:",name2)
fmt.Println("修改name2[2]之后,names:",names)
// 也可以基于字符串进进行切片
sub1 := "hello world"[6:8]
fmt.Println("sub1:",sub1)
// 可以在创建空切片的时候,明确指定切片的容量,这样可以提高运行效率
// 创建一个容量是20,当前长度10的string类型切片,第三个参数容量不是必须的,如果没填写,则默认与长度相同
str2 := make([]string,10,20)
fmt.Println("len:",len(str2),"cap:",cap(str2))
// 如果相让切片完全独立于原始数组,可以使用copy()函数完成
namesCopy := make([]string,len(names))
// names是一个数组,copy函数接收的类型是切片,所以需要使用[:]将数组变成切片
copy(namesCopy,names[:])
namesCopy[0] = "香港"
fmt.Println("namesCopy:",namesCopy)
fmt.Println("names:",names)
}

字典(map)
哈希表,key => value,存储的key是经过哈希运算的
使用map的时候一定要分配空间
package main
import "fmt"
func main() {
// 定义一个学生字典idNames
// 定义一个map,此时这个map是不能直接赋值的,它是空的
var idNames map[int]string
idNames[0] = "simple"
idNames[1] = "mike"
for key, value := range idNames{
fmt.Println("key:",key, "value:",value)
}
}
package main
import "fmt"
func main() {
// 定义一个学生字典idNames
// 定义一个map,此时这个map是不能直接赋值的,它是空的
// var idNames map[int]string
// 分配空间,使用make,可以不指定长度,但是建议直接指定长度,性能更好
// idNames := make(map[int]string)
idNames := make(map[int]string, 10)
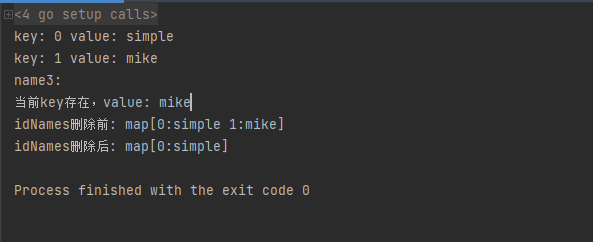
idNames[0] = "simple"
idNames[1] = "mike"
// 遍历map
for key, value := range idNames{
fmt.Println("key:",key, "value:",value)
}
// 如何确定一个key是否存在map中
// 在map中不存在访问越界的问题,它认为所有的key都是有效的,所以访问一个不存在的key不会崩溃,返回这个类型的默认值(零值)
// 零值: bool => false, 数字 => 0, 字符串 => 空
// 无法通过获取value来判断一个key是否存在,因此我们需要一个能够校验key是否存在的方式
name3 := idNames[3]
fmt.Println("name3:",name3)
// 如果id=1存在,那么value就是key=1的值,ok返回的就是true,反之就是默认值,false
value, ok := idNames[1]
if ok{
fmt.Println("当前key存在,value:",value)
}else{
fmt.Println("当前key不存在,value:",value)
}
// 删除map中的元素,可以使用自由函数delete来删除指定的key
fmt.Println("idNames删除前:",idNames)
delete(idNames,1)
// 注意:删除无效的key,不会报错
delete(idNames,100)
fmt.Println("idNames删除后:",idNames)
// 多个并发处理,需要对map进行上锁
}
指针
- Go语言也有指针
- 结构体成员调用时,C语言:ptr->name,Go语言:ptr.name
- Go语言在使用指针时,会使用内部的垃圾回收机制(GC:Garbage collector),开发人员不需要手动释放内存
- C语言不允许返回栈上的指针,Go语言可以返回栈上的指针,程序会在编译的时候就确定了变量的分配位置
- 编译的时候,如果发现有必要的话,就将变量分配到堆上
package main
import "fmt"
func main(){
name := "simple"
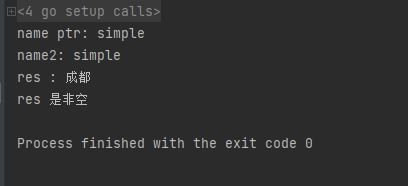
ptr := &name
fmt.Println("name ptr:",*ptr)
// 使用new关键字定义
name2Ptr := new(string)
*name2Ptr = "simple"
fmt.Println("name2:",*name2Ptr)
// 可以返回栈上的指针,编译器在编译程序时,会自动判断这段代码,将city变量分配在堆上
res := testPtr()
fmt.Println("res :",*res)
// 空指针,在C语言:null,C++:nullptr,go:nil
// if两端不加()
// 即使有一行代码,也必须使用{}
if res == nil{
fmt.Println("res 是空,nil")
}else{
fmt.Println("res 是非空")
}
}
// 定义一个返回,返回一个string类型的指针
func testPtr() *string {
city := "成都"
ptr := &city
return ptr
}
内存逃逸
golang中内存分配方式:
主要是堆(heap)和栈(stack)分配两种。
栈分配:对于栈的操作只有入栈和出栈两种指令,属于静态资源分配。
堆分配:堆中分配的空间,在结束使用之后需要垃圾回收器进行闲置空间回收,属于动态资源分配。
使用栈分配:函数的内部中不对外开放的局部变量,只作用于函数中。
使用堆分配:1.函数的内部中对外开放的局部变量。2.变量所需内存超出栈所提供最大容量。
package main
import (
"fmt"
"runtime"
"time"
)
func main(){
demo()
}
// 定义一个函数,用于返回string类型的指针
func demo() {
runtime.GOMAXPROCS(1)
for i := 0; i < 10; i++{
go func() {
fmt.Println("i:", i)
}()
}
runtime.Gosched()
time.Sleep(time.Second)
}
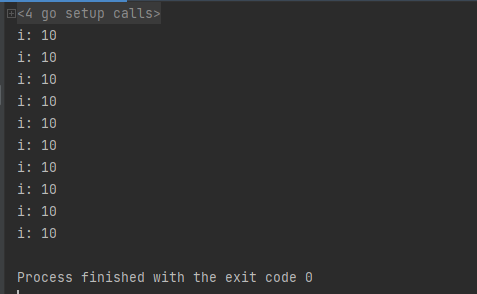
这里函数demo里面的i是局部变量,并且没有外部引用,不对外开放,所以是分配在栈中的。
运行命令
go build --gcflags "-m -m -l" 02_basicGrammar.go
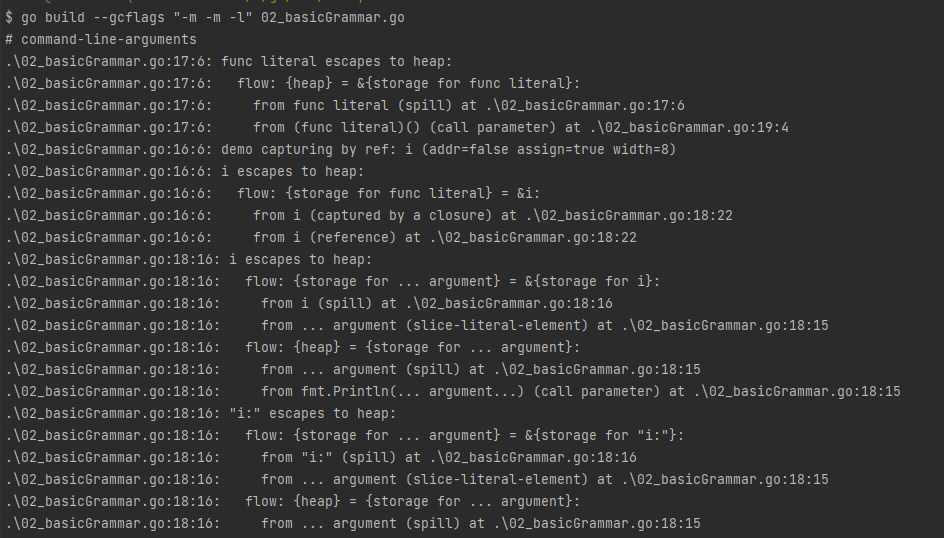
可以看到,i逃逸到堆中了。
那么由于i存在于堆中,并没有随着demo函数结束而释放,并且i的值为10,这就解释了为什么运行结果为10个10了:
下面是四种最常见引发内存逃逸的情况:
发送指针或带有指针的值到 channel 中。在编译时,是没有办法知道哪个 goroutine 会在 channel 上接收数据。所以编译器没法知道变量什么时候才会被释放。
在一个切片上存储指针或带指针的值。一个典型的例子就是 []*string。这会导致切片的内容逃逸。尽管其后面的数组可能是在栈上分配的,但其引用的值一定是在堆上。
slice 的背后数组被重新分配了,因为 append 时可能会超出其容量(cap)。slice 初始化的地方在编译时是可以知道的,它最开始会在栈上分配。如果切片背后的存储要基于运行时的数据进行扩充,就会在堆上分配。
在 interface 类型上调用方法。在 interface 类型上调用方法都是动态调度的 —— 方法的真正实现只能在运行时知道。想像一个 io.Reader 类型的变量 r, 调用 r.Read(b) 会使得 r 的值和切片 b 的背后存储都逃逸掉,所以会在堆上分配。
函数(func)
package main
import "fmt"
func main(){
num1, str, _ := demo(12, 55, "hello world")
fmt.Println("num1:",num1, "str:",str)
num2, str2, b2 := demo2(12, 12,"hello")
fmt.Println("num2:",num2, "str2:",str2,"b2:",b2)
num3 := demo3(12)
fmt.Println("num3:",num3)
}
// 函数返回值在参数列表之后
// 如果有多个返回值,需要使用(),多个参数之间使用逗号
func demo(num1 int, num2 int, str string) (int, string, bool) {
return num1 + num2, str, false
}
// 多个相同类型变量可以简写num1, num2 int
func demo2(num1, num2 int, str string) (resI int, resStr string, resB bool) {
// 直接使用返回值的变量名参与运算,赋值后return无需结果
resI = 12
resStr = "hello world"
resB = true
// 当返回值有名字的时候,可以直接写return
return
}
// 如果返回值只有一个参数,并且没有名称,那么不需要加()
func demo3(num int) int {
return num * 10
}

包导入(import)
package main
// 多个引入,可以使用括号括起来,避免写成import "fmt"、import "import/add"
import (
"fmt"
"import/add" // add 是文件名,同时也是包名
// SUB "import/sub // 如果引用的包名和文件名很长,可以在引号前面重命名这个包名
// . "import/sub" // 表示sub包里面的公共函数都可以使用,不需要在使用的时候包名.函数名的方式使用。但是需要注意,如果相同的公共函数名相同,包名不同这么用会存在争议
)
func main() {
res := add.Add(12, 55)
fmt.Println("res:", res)
}
add包中的add.go文件
package add
func Add(num1, num2 int) int {
return num1 + num2
}
sub包中的sub.go和utility.go
package sub
func demo(){
println("demo()")
}
package sub
// 类似于namespace,在golang中,同一级目录,不允许出现多个包名
// 当前这个函数无法被外部函数调用,因为函数首字母是小写的
// 如果一个包里面的函数想对外提供,那么一定要首字母大写
// 大写相当于:public
// 小写相当于:internal,只有相同包的文件才能使用
func sub(num1, num2 int) int {
// 由于demo()函数与当前函数在一个包名下, 所以可以直接使用,并且不需要首字母大写
demo()
return num1 - num2
}
switch
package main
import (
"fmt"
"os"
)
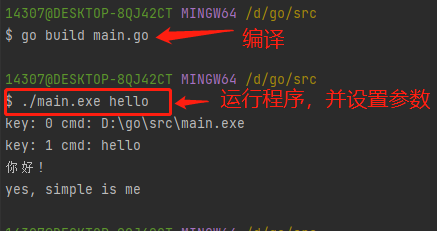
// 从命令行输入参数,在switch中进行处理
func main(){
// 直接可以获取命令输入,是一个字符串切片 []string
cmds := os.Args
// os.Args[0] 为 程序的名称
// os.Args[1] 为 第一个参数,依此类推
// 参数之间通过空格分割
for key, cmd := range cmds{
fmt.Println("key:",key,"cmd:",cmd)
}
if len(cmds) < 2{
fmt.Println("请输入正确参数!")
return
}
switch cmds[1] {
case "hello":
fmt.Println("你好!")
// golang的switch,默认加上了break,不需要手动处理
// 如果想向下穿透,那么需要加上关键字:fallthrough
fallthrough
case "simple":
fmt.Println("yes, simple is me")
default:
fmt.Println("hello")
}
}
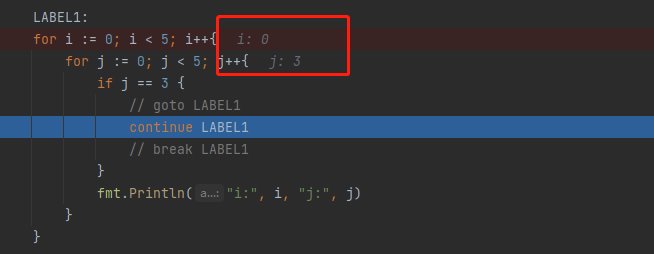
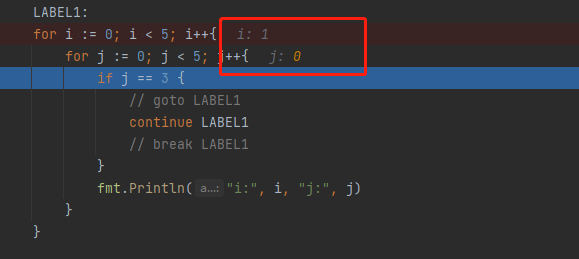
标签(goto、continue、break)
package main
import "fmt"
func main(){
// goto LABEL1
// 下次进入循环时,i不会保存之前的状态,重新从0开始计算,重新来过
// continue LABEL1
// 会跳到指定的位置,但是会记录之前的状态,i=1
// break LABEL1
// 直接跳出指定位置的循环,正常情况下break值跳出一层循环
// 标签名称是可以任意命名的,后面加上冒号
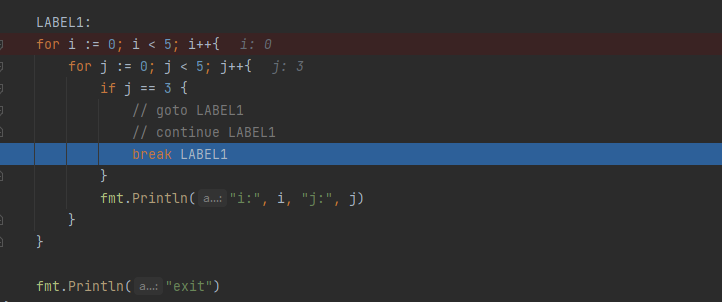
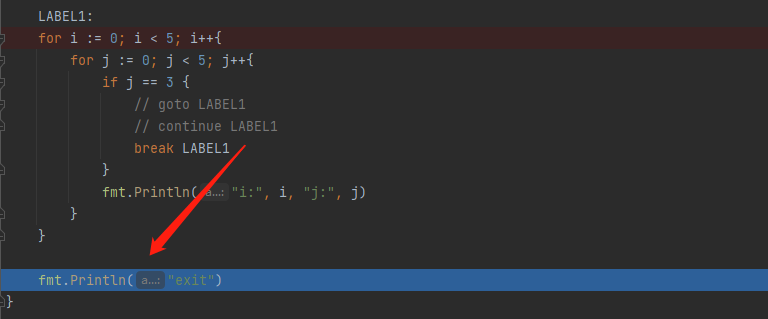
LABEL1:
for i := 0; i < 5; i++{
for j := 0; j < 5; j++{
if j == 3 {
// goto LABEL1
// continue LABEL1
break LABEL1
}
fmt.Println("i:", i, "j:", j)
}
}
fmt.Println("exit")
}
goto result
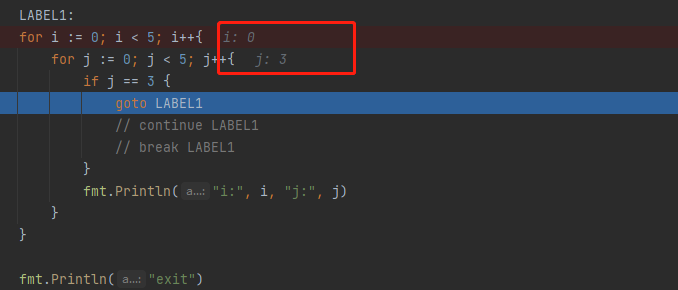
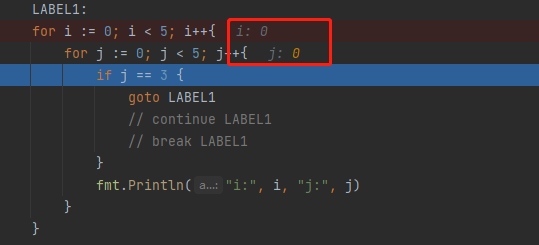
continue result
break result
枚举(const+iota)
在go语言中没有枚举类型,但是我们可以使用const+iota(常量叠加器)来进行模拟
package main
import "fmt"
// iota是常量组计数器
// iota从0开始,每换行递增1
// 常量组有个特点,如果默认不赋值,它默认与上一行表达式相同(所以SATURDAY也是=iota)
// 如果同一行出现两个iota,那么两个iota的值是相同的
// 每个常量组的iota是独立的,如果遇到const,iota会重新清零
// 常量组
const (
MONDA = iota // 0
TUESDAY = iota // 1
WEDNESDAY // 没有赋值,默认与上一行相同
THURSDAY
FRIDAY
SATURDAY
SUNDAY
M, N = iota,iota // 如果同一行出现两个iota,那么两个iota的值是相同的
)
const(
MALE = iota + 1
FEMALE
)
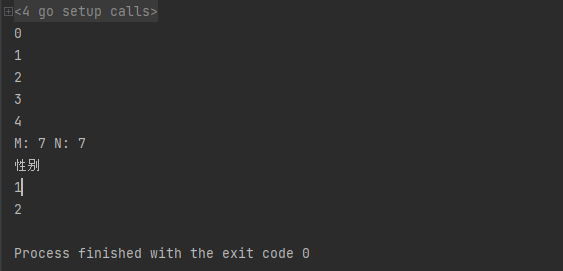
func main(){
fmt.Println(MONDA)
fmt.Println(TUESDAY)
fmt.Println(WEDNESDAY)
fmt.Println(THURSDAY)
fmt.Println(FRIDAY)
fmt.Println("M:",M,"N:",N)
fmt.Println("性别")
fmt.Println(MALE)
fmt.Println(FEMALE)
}
结构体(struct)
package main
import "fmt"
// c语言定义结构体方式
// struct Person{
//
// }
// c语言里面,我们可以使用typedef int MyInt
// 在Golang中,我们也可以使用type来定义
type MyInt int // 相当于c语言的typeof
// Golang 结构体使用type + struct来定义
type Student struct {
Name string
Age int
Gender bool
Score float32
}
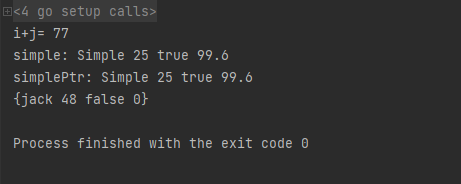
func main() {
var i, j MyInt
i, j = 12, 65
fmt.Println("i+j=", i+j)
simple := Student{
Name: "Simple",
Age: 25,
Gender: true,
Score: 99.6, // 在Golang中,如果花括号}不在当前行,那么这个逗号必须添加
}
fmt.Println("simple:", simple.Name, simple.Age, simple.Gender, simple.Score)
// C语言使用指针的方式调用 ->
// 而Golang使用指针的方式为.
simplePtr := &simple
fmt.Println("simplePtr:", simplePtr.Name, simplePtr.Age, simplePtr.Gender, simplePtr.Score)
// 在定义期间对结构体进行赋值是,如果每个字段都赋值了,那么字段的名字可以省略不写
// 如果指定局部变量赋值,那么必须明确指定变量名称
jack := Student{
Name: "jack",
Age: 48,
// Gender: false,
// Score: 10,
}
jack.Gender = false
fmt.Println(jack)
}
init函数
- C语言没有init函数,C语言需要自己去写init,然后在构造函数中调用
- Golang自带init函数,每一个包都可以包含一个或多个init函数
- 这个init会在包被引用的时候(import)进行自动调用
- 应用场景:比如初始化,加载配置等
package utility
import "fmt"
// 这个init会在包被引用的时候(import)进行自动调用
// init函数没有参数,没有返回值,原型固定如下:
// 一个包中包含多个init时,调用顺序是不确定的(同一个包的多个文件都可以有init)
// init函数不允许用户显式调用
// 有的时候引用一个包,可能只想用这个包的init函数(mysql的init对驱动进行初始化),但是不想使用这个包里面的其他函数,为了方式编译器报错可以使用_形式来处理(import _ "xxx/xxx")
func init(){
fmt.Println("this is first init int page utility")
}
func init(){
fmt.Println("this is second init int page utility")
}
func Sayhi() {
fmt.Println("hello world")
}
package main
import "src/utility"
func main() {
utility.Sayhi()
}

defer(延迟)
- defer是一个关键字,可以用于修饰语句,函数,确保这条语句可以在当前栈退出的时候执行
- 一般用于做资源清理工作
- 例如:解锁,关闭文件等
- 可以在一个函数中多次调用
- 执行时会类似于栈的机制,先入后出
lock.Lock()
a = "hello world"
lock.Unlock() // 多线程资源竞争的时候,有的时候会忘记写Unlock导致资源被锁住
// Golang可以使用defer来解决这个问题
1. lock.Lock()
2. defer lock.Unlock() // 在当前栈退出的时候(例如:函数结束时)
3. a = "hello world"
// 执行顺序 1 > 3 > 2
// 1.当执行完加锁操作时lock.Lock()
// 2.Golang会将语句2自动压栈,然后执行第3代码
// 执行完第3句代码后,Golang再去调用defer lock.Unload()
例如,读取一个文件内容,并通过defer关闭文件
package main
import (
"fmt"
"os"
)
func main() {
readFile("main.go")
}
func readFile(fileName string) {
// Golang一般会将错误码当作最后一个参数返回
// err一般nil代表没有错误,执行成功,非nil表示执行失败
file, err := os.Open(fileName)
// defer file.Close()
// 创建一个匿名函数同时调用
defer func() {
fmt.Println("准备关闭文件...")
file.Close()
}()
if err != nil{
fmt.Println("打开文件失败,err",err)
}
buf := make([]byte, 1024)
len,_ := file.Read(buf)
fmt.Println("读取文件的真实长度:",len)
fmt.Println("读取的文件内容:",string(buf))
// 可以使用上面的defer file.close()来等当前栈退出后自动关闭文件
// file.Close()
}
自增语法
C语言:i++,i--,--i,++i
Go语言:i++,i--,没有++i和--i,自增语法必须单独一行
Golang不支持的语法
- 自增/自减:++i/--i
- 不支持地址加减
- 不支持三目运算符(? :)
- 只有false才能代表假逻辑,数组0和nil不能