发表时间:2020(ICLR 2020)
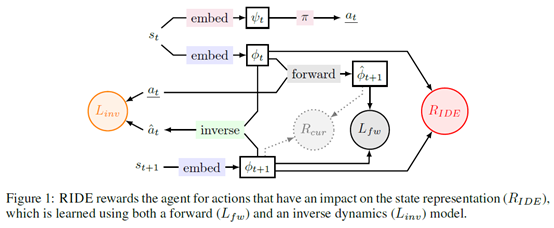
文章要点:这篇文章提出了一个新的intrinsic reward机制,Rewarding Impact-Driven Exploration (RIDE),鼓励agent采取使得状态表征变化大的动作,相较于之前的方法,这个方式在procedurally-generated environments这类很难访问同一个状态多次的环境上效果更好(这里作者提出了两类sparse reward的环境,singleton和procedurally-generated。Singleton指环境每次都一样,不会因为不同episode而有区别,比如Montezuma's Revenge每次出生点位一样,关卡也一样。procedurally-generated就是环境是逐渐生成的,并且每次生成都不一样)。同时作者说这个方法的intrinsic reward不会随着训练过程而减少,并且这种根据状态表征的差异来设计intrinsic reward的方式更偏向于agent的动作对环境起作用的目标,从而不会overfitting到一些无关特征上(our intrinsic reward does not diminish during the course of training and it rewards the agent substantially more for interacting with objects that it can control)。
具体的,作者首先学一个state representation
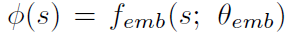
然后根据这个representation学一个forward dynamics model和inverse dynamics model。前向模型根据(phi_t)和(a_t)预测下一个(phi_(t+1)),
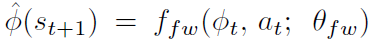
训练的损失函数为
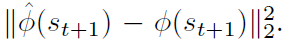
后向模型根据(phi_t)和(phi_(t+1))来预测agent采取了什么动作
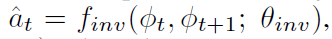
训练的损失函数为交叉熵损失
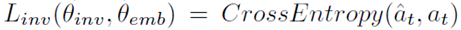
有了这个之后,intrinsic reward就根据相邻两个状态的表征的差异给出
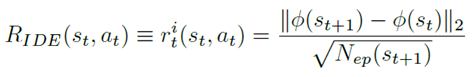
其中(N_{ep})是访问次数,如果状态空间是高维空间,就用episodic pseudo-counts代替。然后整个训练的目标函数为
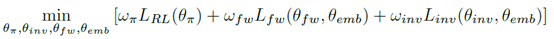
第一个损失是RL的损失,第二个是前向网络的损失,第三个是后向网络的损失。
总结:很自然的一个想法,可能做出来就是效果好吧。不过这些方法离真正解决sparse reward问题还很远啊。这类问题确实太难了,任重道远,加油啊大家。
疑问:之前有paper说intrinsic reward要diminish才能保证收敛渐进无偏,然后这篇文章又说不diminish的intrinsic reward才好,这。。。