字符串对象
- 字符串对象的编码可以是int,raw,embstr
- 如果是整型且可以用long表示则encoding -> int,且直接将整数值保存在ptr里。
- 如果字符串长度 > 32字节,则encoding -> raw,redisObject的ptr属性指向一个SDS对象地址。
- 如果字符串长度 <= 32字节,则encoding -> embstr,对象组成比较特殊。

-
embstr使用方式和raw效果一样,区别在于
-
raw每次分配两次空间,redisObject一次,SDS对象一次,而embstr只需要分配一次连续的内存空间如上图。
-
回收时,raw回收两次内存空间,embstr只需要回收一次。
-
- 对于longdouble浮点数如(3.14),都是以字符串保存encoding embstr或raw。
- 字符串encoding的相互转换
- 首先,redis中embstr不能修改,可以理解为只读的,一旦对embstr类型的字符串修改了,最终会转换为raw。
- 其次,对一个encoding为int类型的数据做append操作:
- set msg 10086 -> encoding msg 输出 int -> append msg "a god job" -> encoding msg 输出 raw。
- set msg test -> encoding msg 输出 embstr -> append msg "a" -> encoding msg 输出 raw。
列表对象
- 列表对象的编码可以是ziplist或者linkedlist
- RPUSH numbers 1 three 5
- 如果使用的ziplist编码,则底层如图

-
如果使用的是linkedlist编码,则底层如图
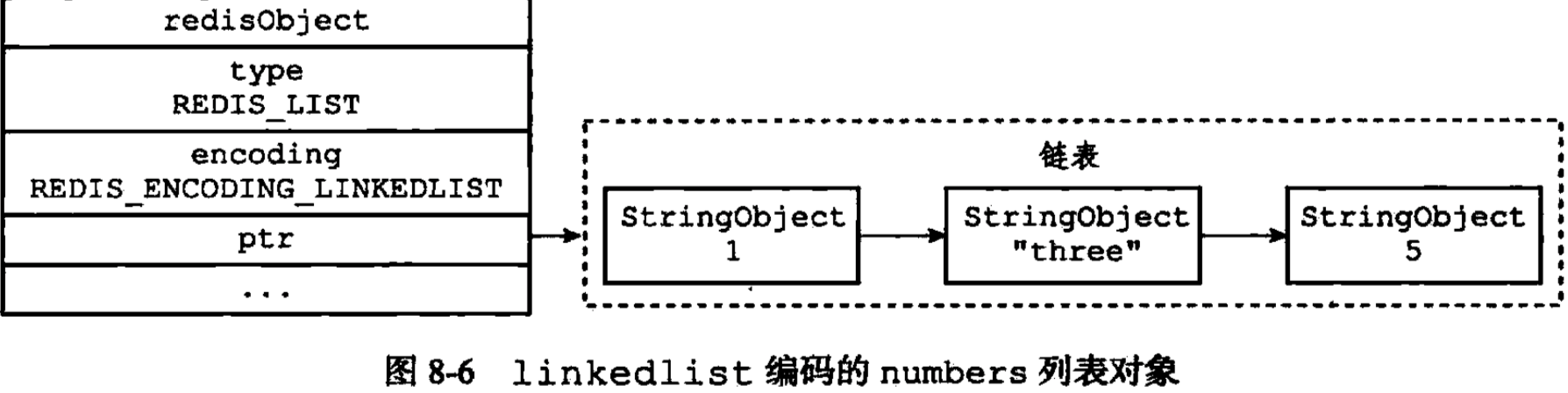
使用linkedlist编码的列表对象底层是嵌套的多个字符串对象,字符串对象是五个对象中唯一一个被其他对象嵌套的对象。
- 如果使用的ziplist编码,则底层如图
- 编码的转化

- 以上数值可配置,不赘述。
- 只要任一条件不被满足,ziplist马上会被转化成linkedlist
HASH对象
- HASH对象的编码可以是ziplist或者hashtable
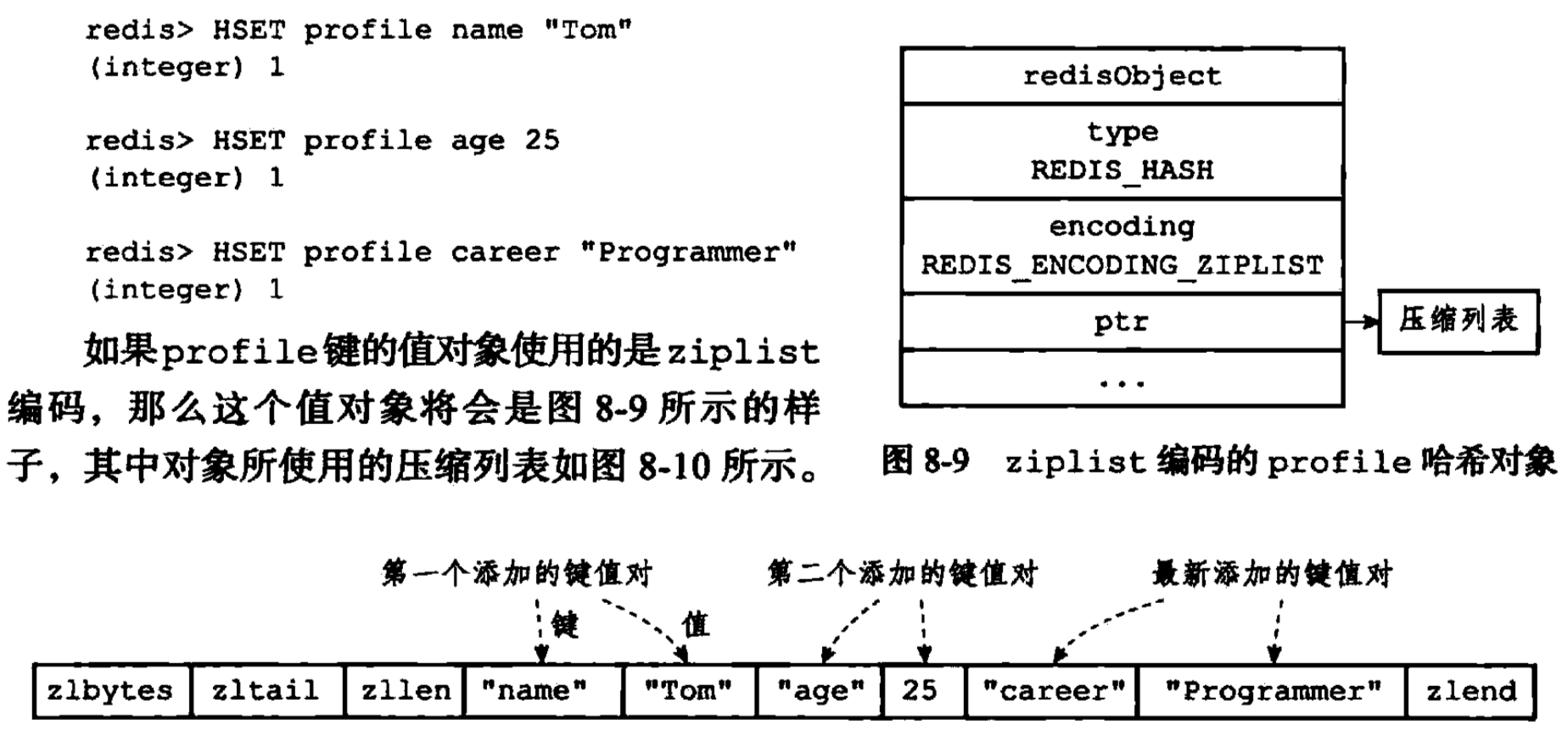
- ziplist
- 使用ziplist实现的hash对象在hset键值对进去的时候会顺序先将K放到压缩列表表尾,然后将V放到压缩列表表尾,换言之KV一定是紧挨在一起的。
- 先进的KV总是在后进的KV前,更靠近表头,换言之,顺序插入。
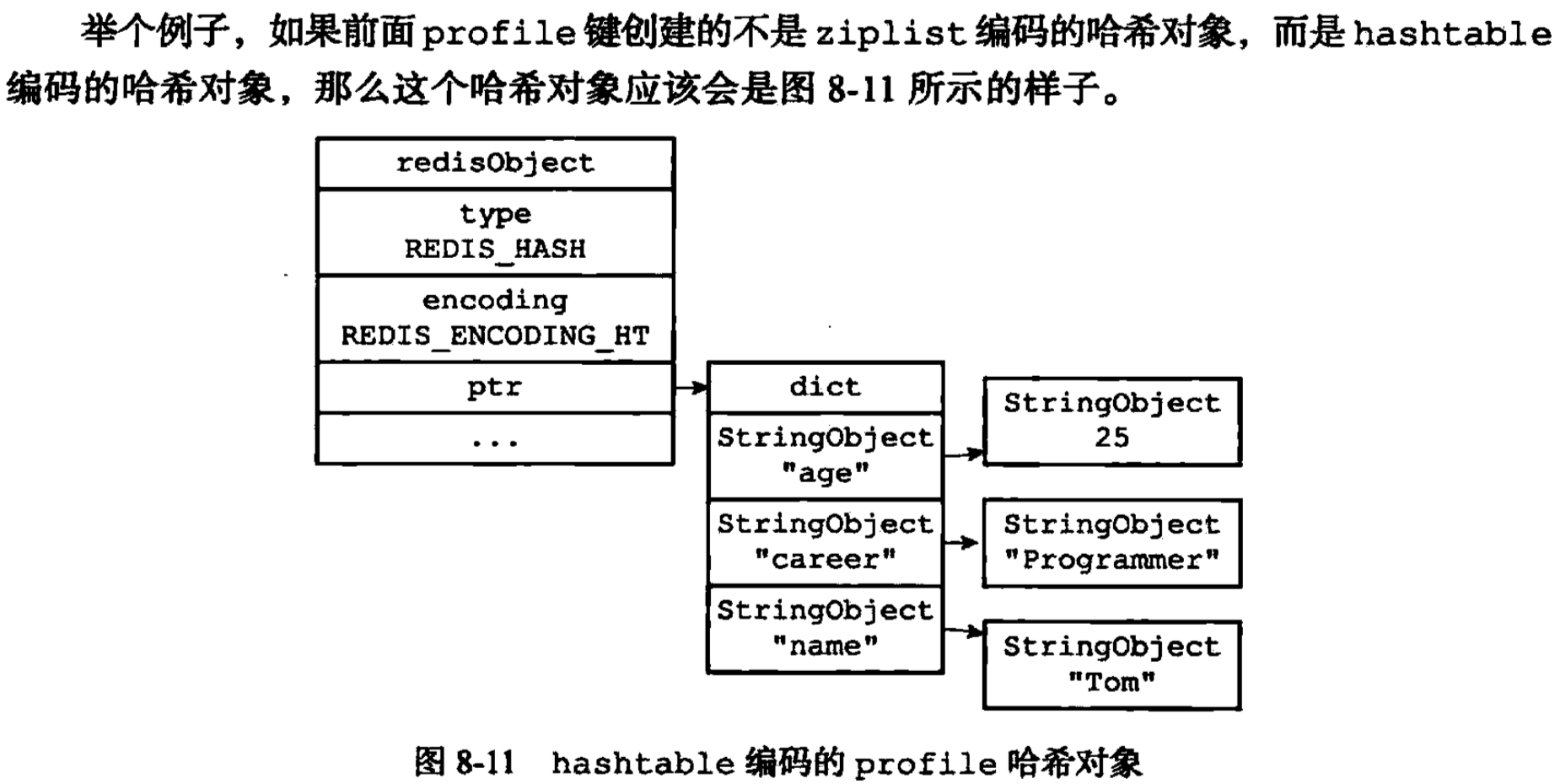
- hashtable实现的hash对象
- 底层使用字典表实现,hash对象中的每个键值对,都使用一个字典键值对来保存。
- 字典中的每个键都是一个字符串对象,对象中保存了键值对的键。
- 字典中的每个值都是一个字符串对象,对象中保存了键值对的值。
-
编码的转换
-

-
同样可以通过配置修改不赘述。
-
同样的一旦有元素不满足以上条件,整个hash对象都会变为hashtable编码。
-
集合对象
- 集合对象的编码可以是inset或者hashtable
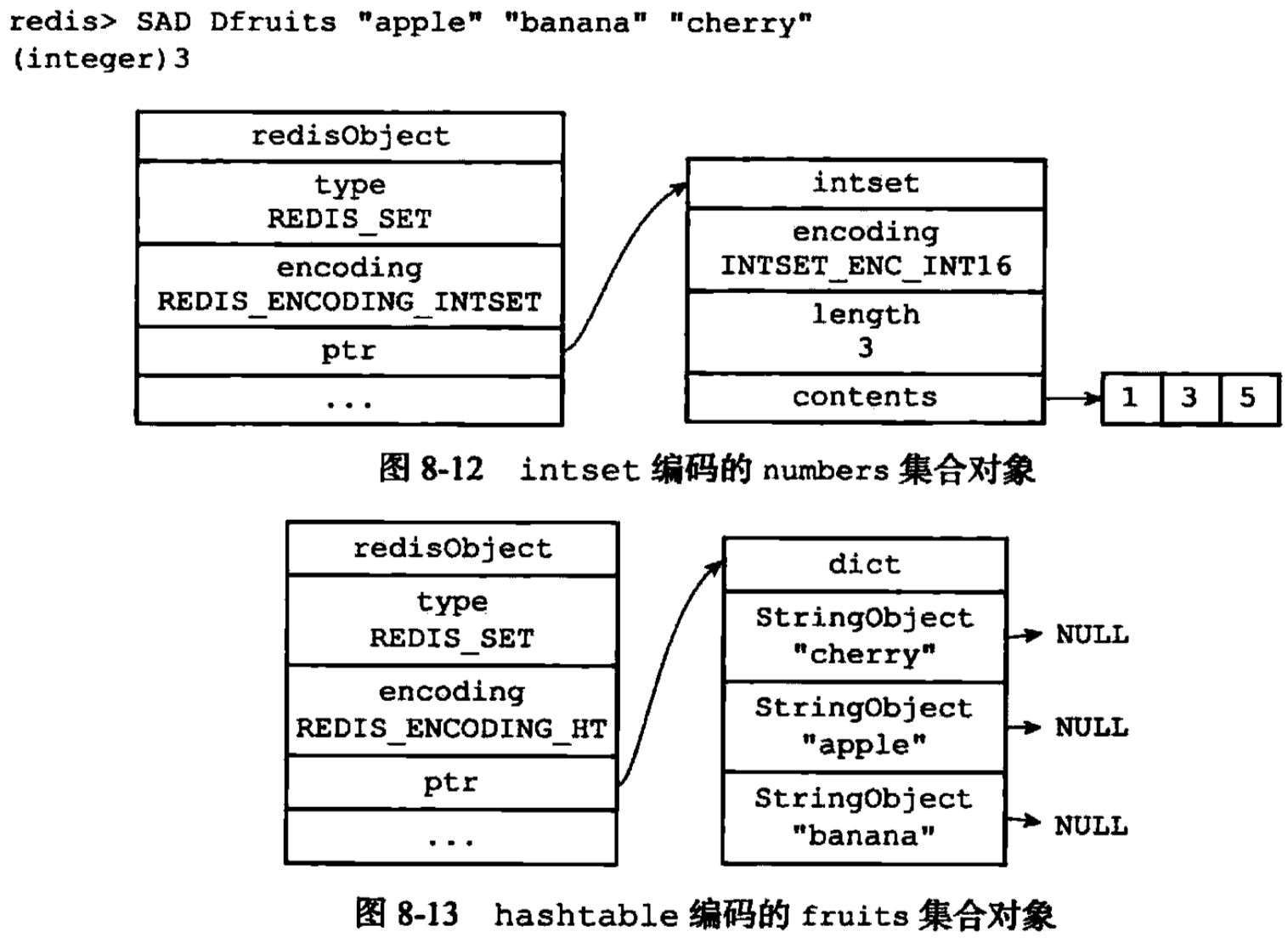
-
如上图,hashtable实现的集合对象类似于Java里hashset的实现。
-
编码的转换
-

-
同样可以通过配置文件配置,且一旦有元素不满足就整个数据结构重新编码。
-
有序集合对象
- 编码可以是ziplist或者skiplist
- ziplist编码
- 类似于ziplist实现的hash对象,将V和score挨在一起插入到压缩列表表尾。
- skiplist编码
- 同时包含一个字典和一个跳跃表
- 跳跃表保存了所有元素,每个元素都是一个跳跃表节点,跳跃表节点的score保存了分值,object属性保存了元素值。(ZRANGE,ZRANK就是依此实现的)
- 字典表则保存了每个元素值与分值的映射K存值,V存score。(ZSCROE依此实现O(1)时间复杂度拿到每个指定元素的分值)
- 在实际存储中,字典表和跳跃表会共享元素,不会造成空间浪费。
- 编码的转换
-

-
同样可以配置,当有一个元素不满足,都会导致重新编码。
-