决策树就是一层一层的if-else, 数据最好是离散型的

决策树是有监督学习。利用训练集,最终训练为一棵树(叶子节点是类别,中间是属性)



————————————————————————————————————————————————————————————————
决策树的构建方法 id3方法
信息熵的概念:


ID3构建决策树的思想:
分布越均匀,越混乱,熵越大。结点上的数据类值都相同(毫无悬念,系统一点也不混乱,熵最小)
因此一个好的决策树划分,应该是每次都找一个属性划分,这个属性划分完,结点尽量聚集在一类,即划分完以后熵很小。
因此计算熵增益(信息增益)。

用原系统的熵减去划分后系统的熵,找到差距最大的那个属性。

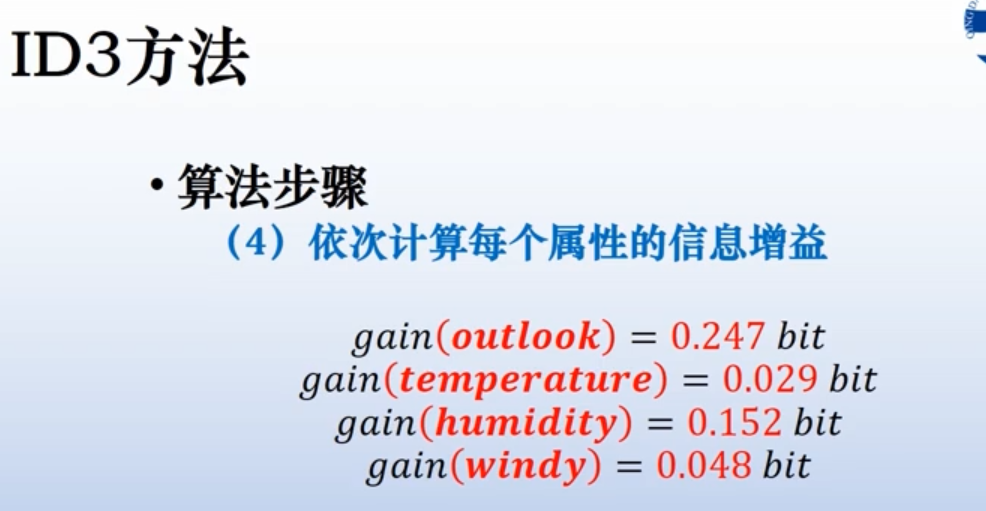
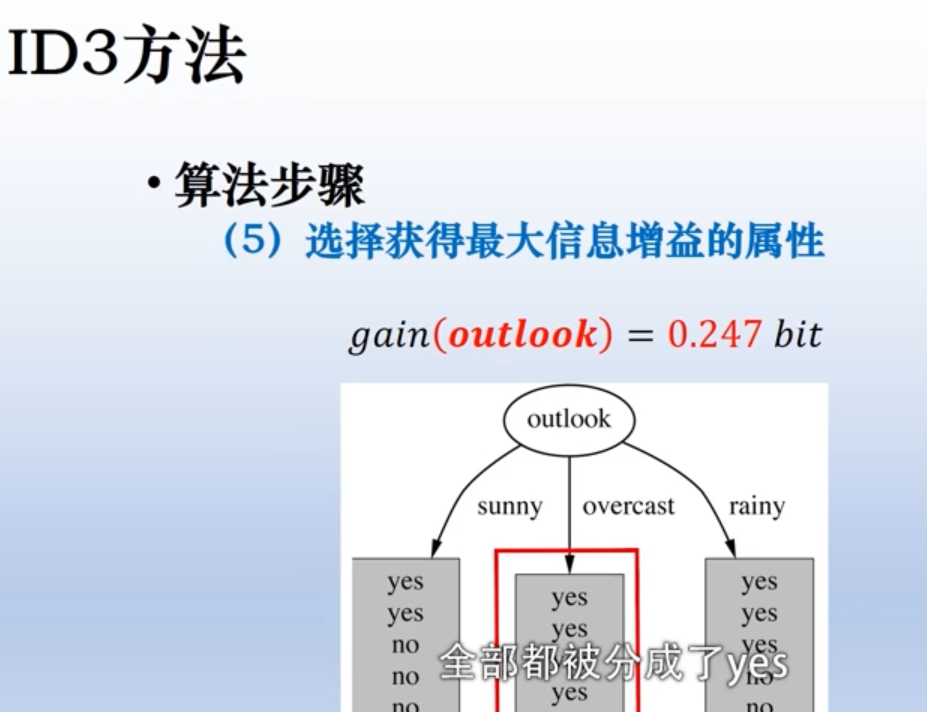

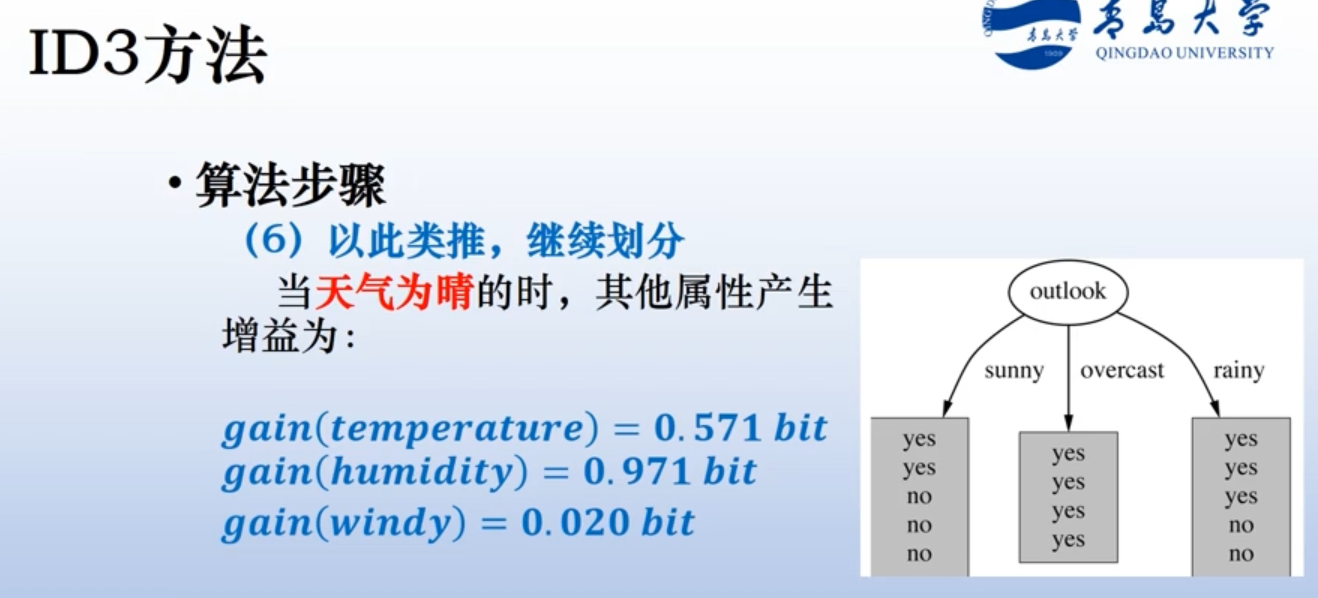
ID3如何终止:

ID3性质,不会回溯,已经选择过的属性,不会被重新计算和考虑。

————————————————————————————————————————————————————————————————————————————————————————————————————————————————————
过拟合及剪枝算法


数据划分法,就是用训练集和测试集。用训练集生成决策树,使用测试集测试,当错误率最小时,停止树的生长。

后减枝,就是合并分支。

C4.5和CART算法,这种决策树建立方法已经包含了减枝。
——————————————————————————————————————————————————————
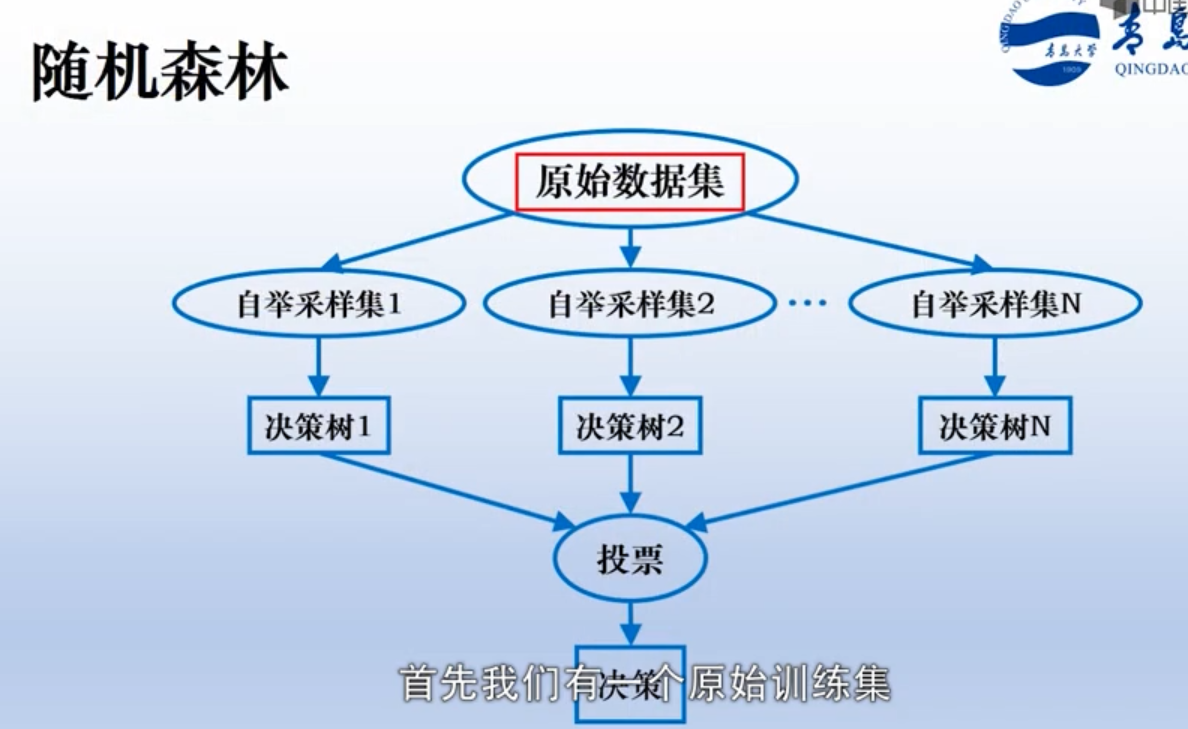
随机森林,就是决策树的森林。

1. 有放回的随机抽取,构成训练子集, 对N个子训练集分别构建决策树
2. 也可以对特征进行采样(类似于用来进行特征筛选)
3、投票。