| 这个作业属于哪个课程 | 2020春|S班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 结对第二次作业——某次疫情统计可视化的实现 |
| 结对学号 | 221600423 & 221701404 |
| 这个作业的目标 | 疫情可视化 |
| 作业正文 | 结对第二次作业——某次疫情统计可视化的实现 |
| 其他参考文献 | ... |
1.GitHub
2.成品展示
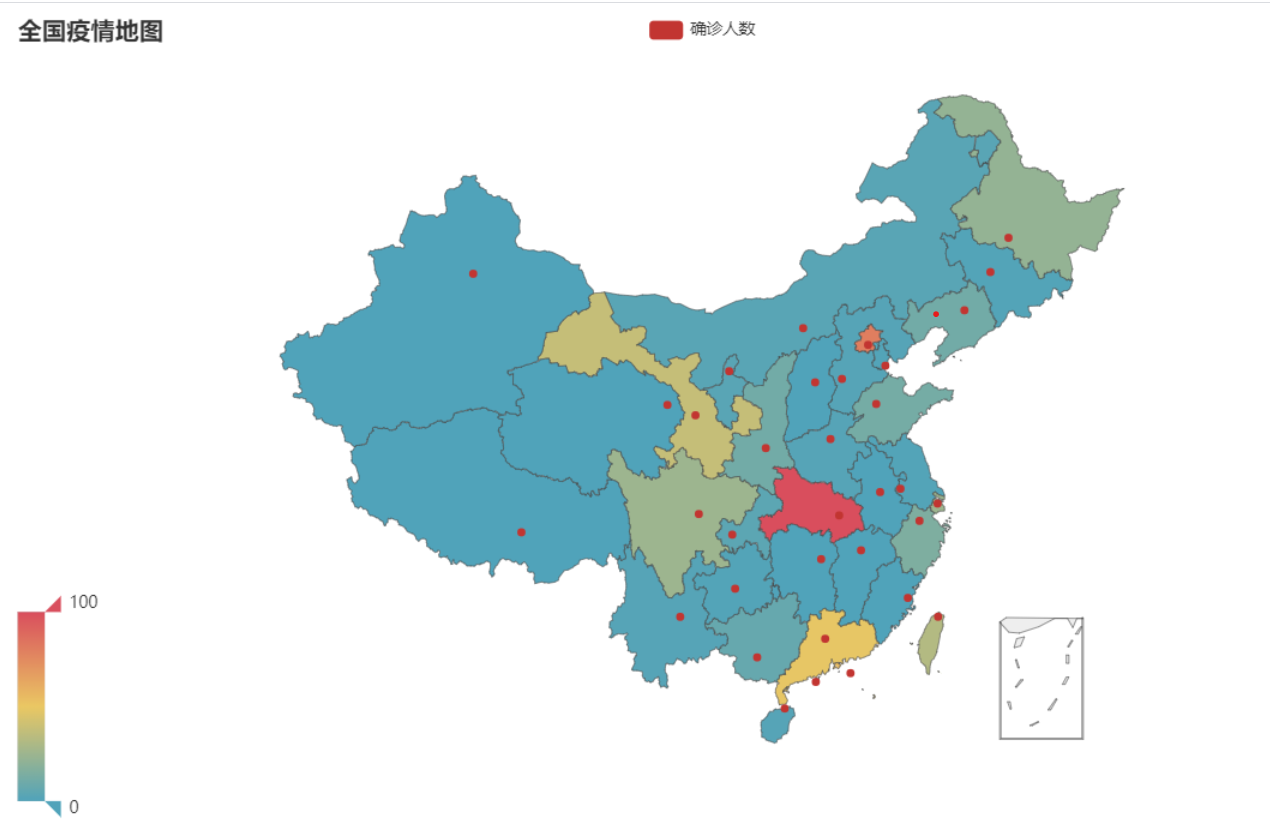
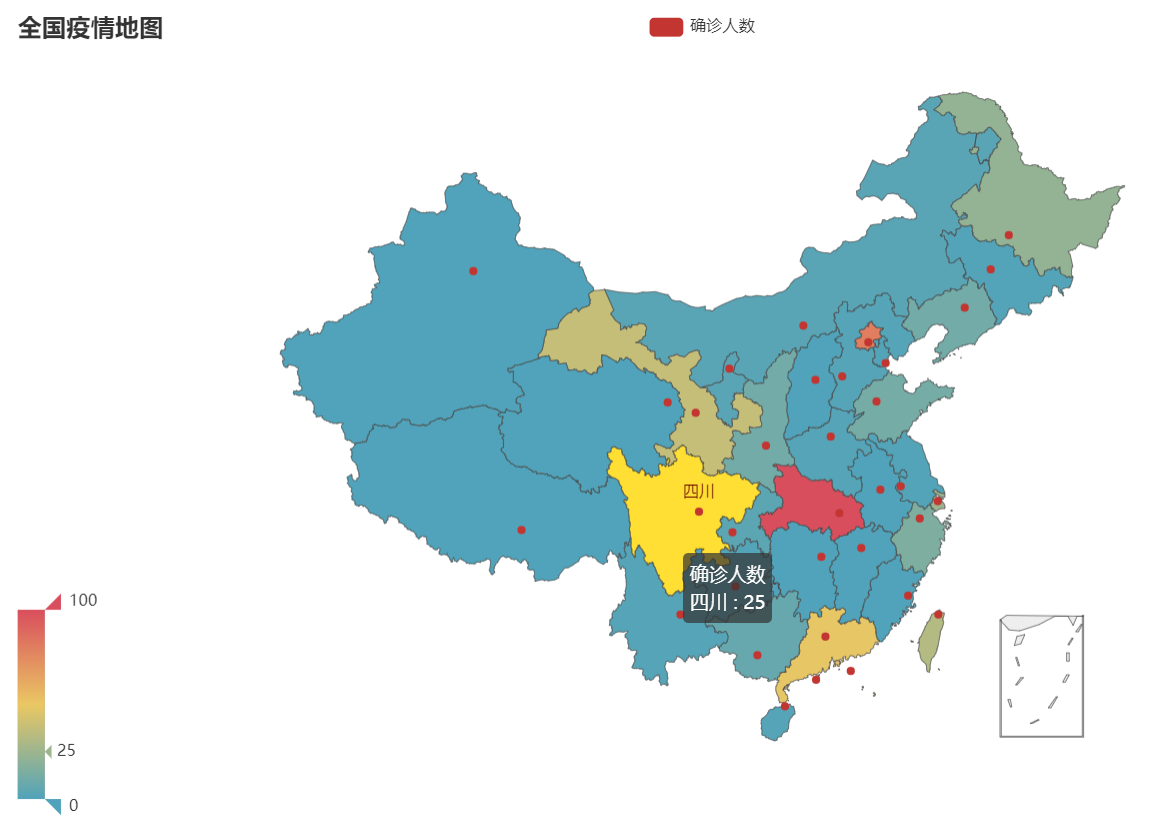
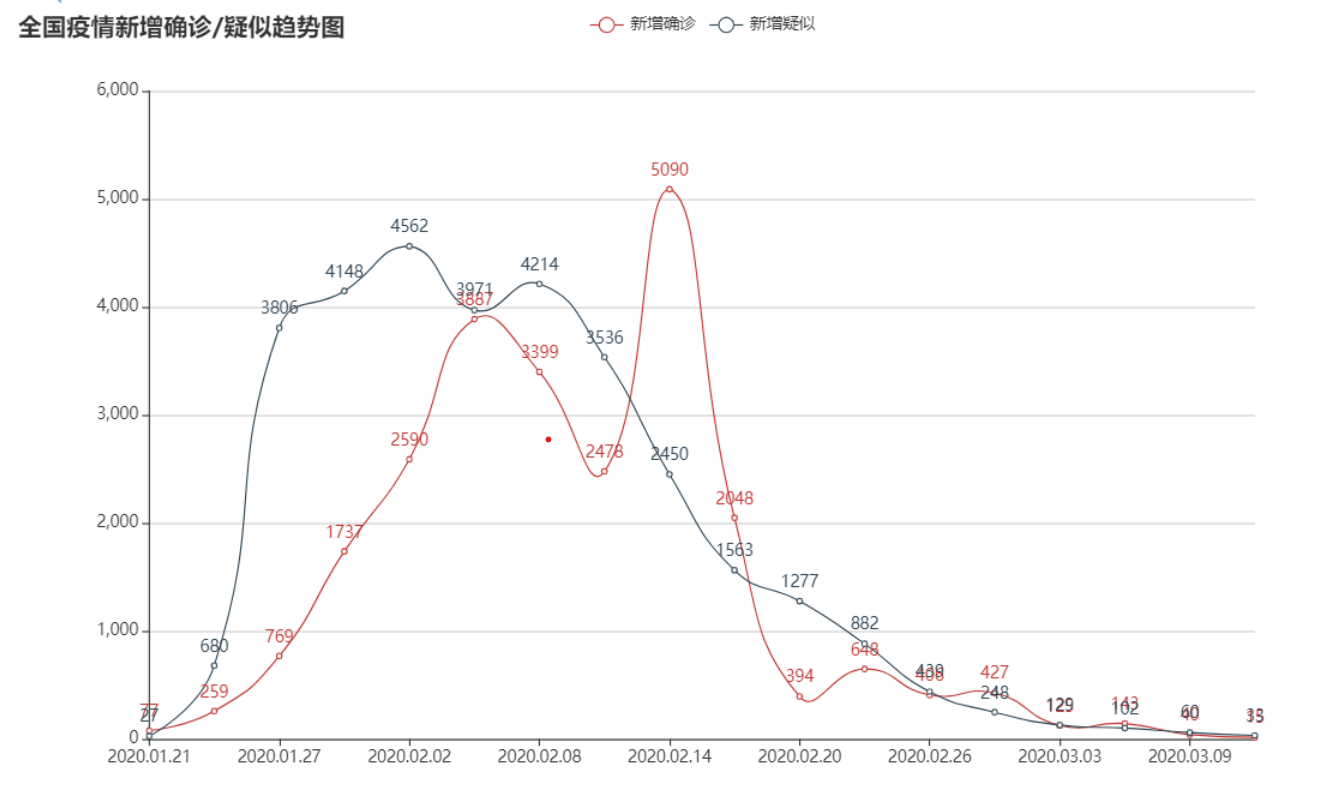

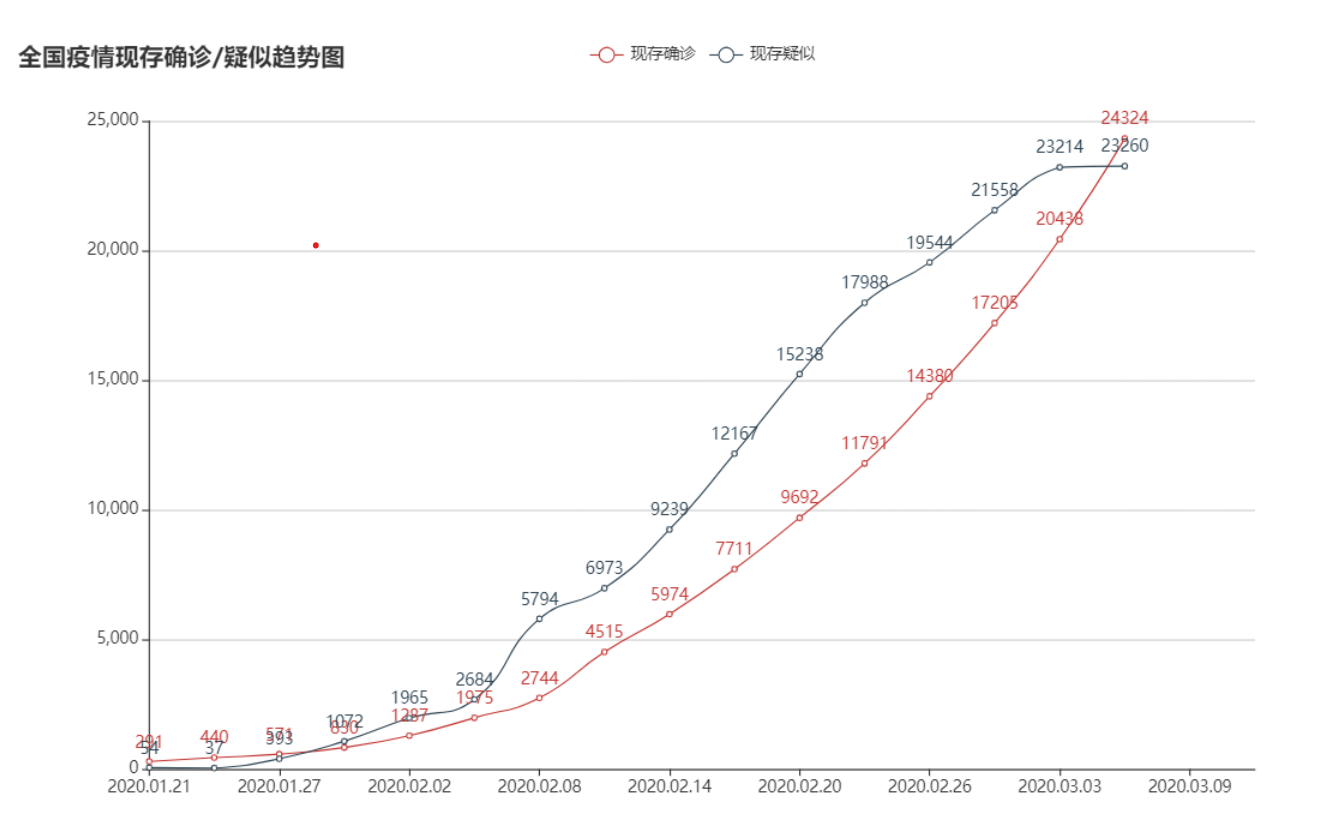
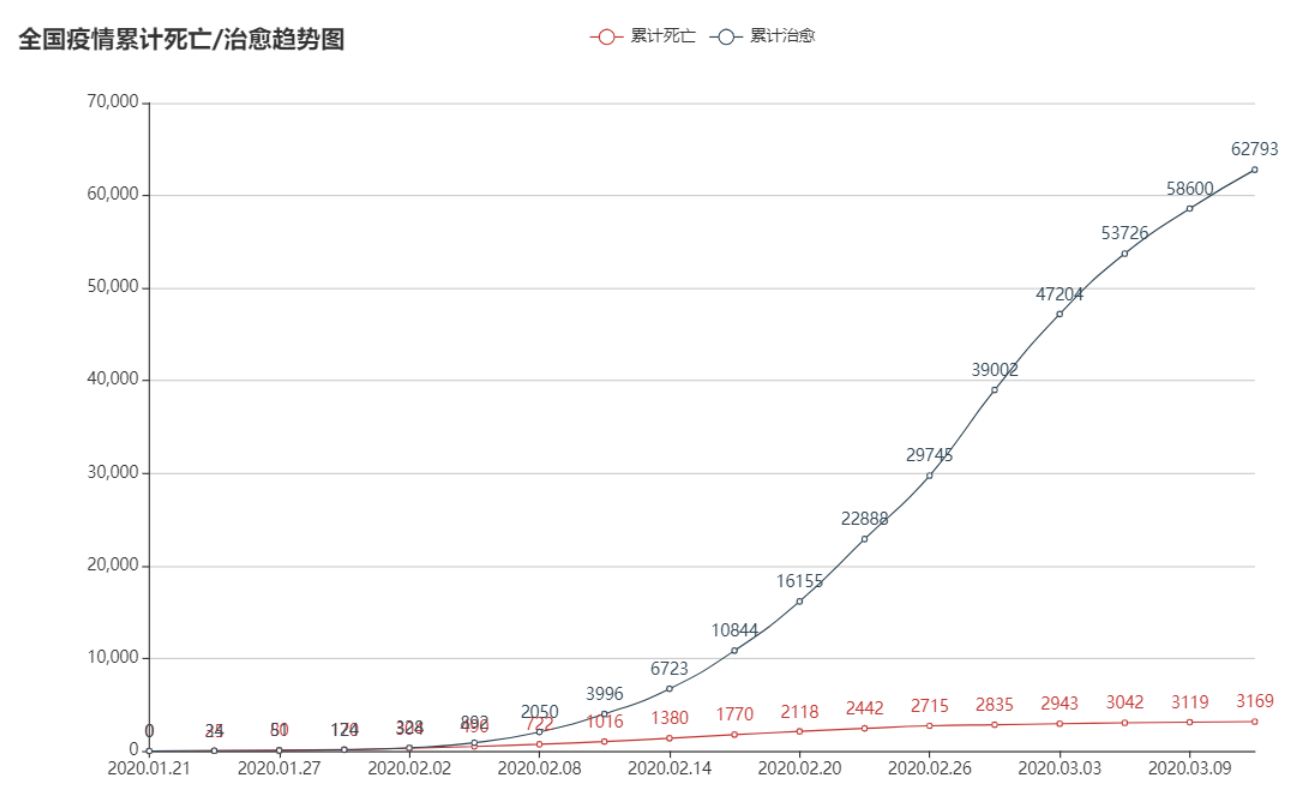
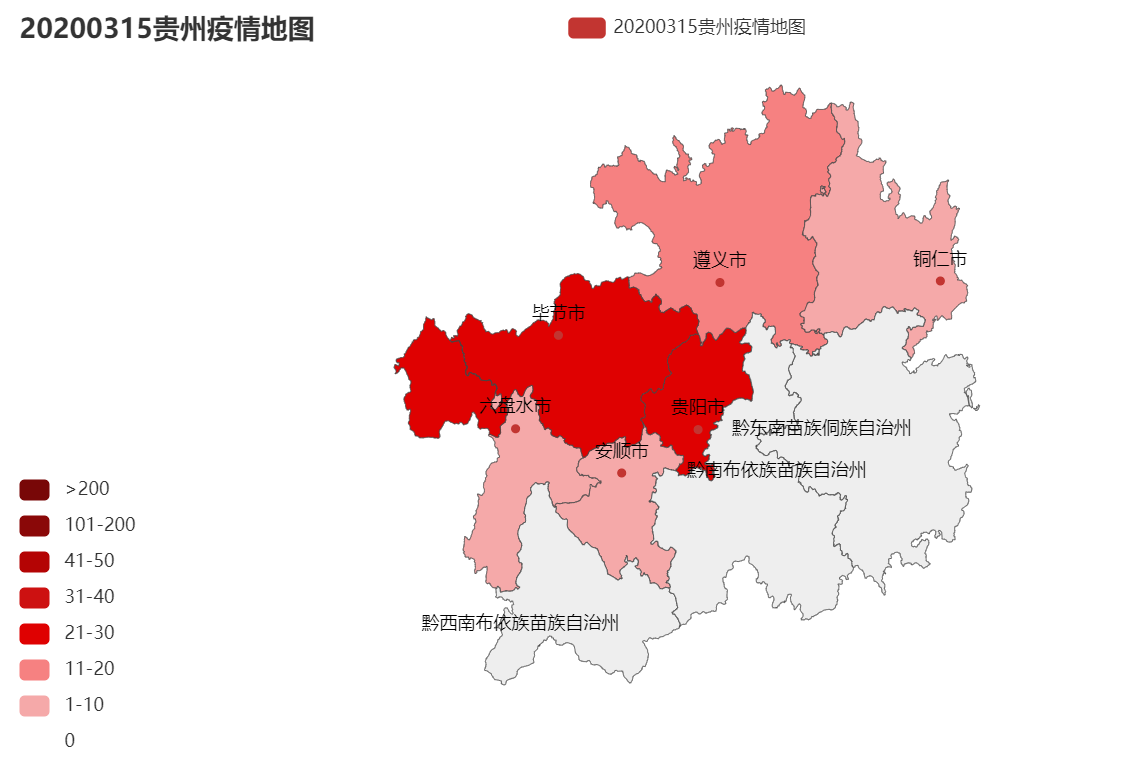
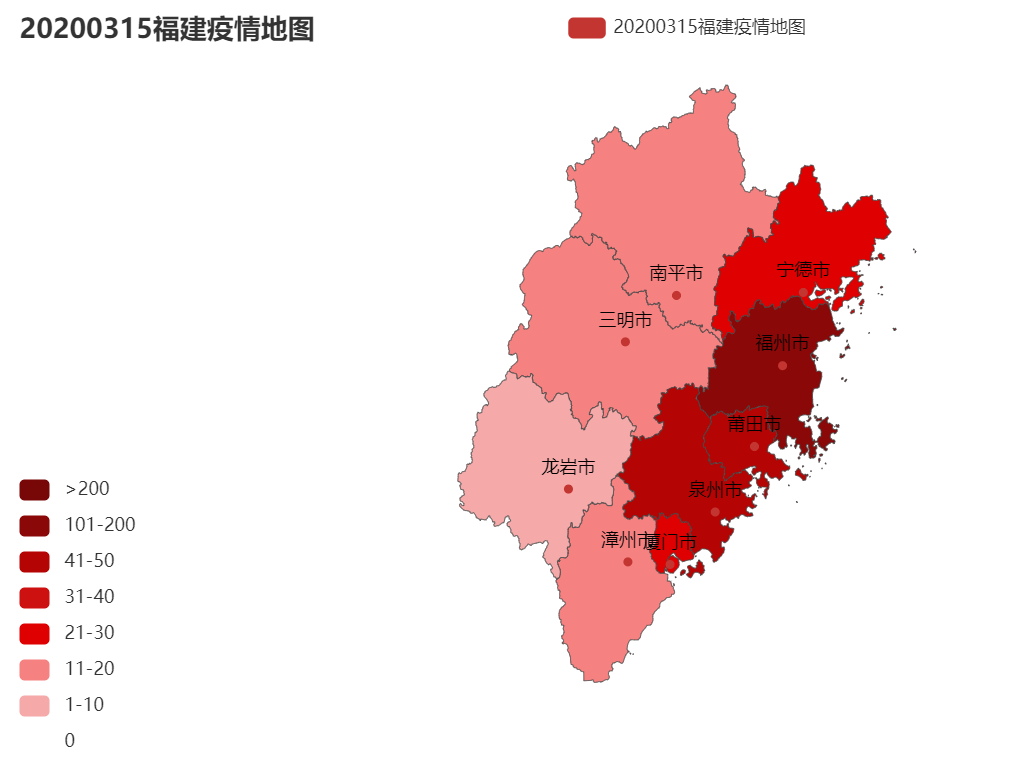
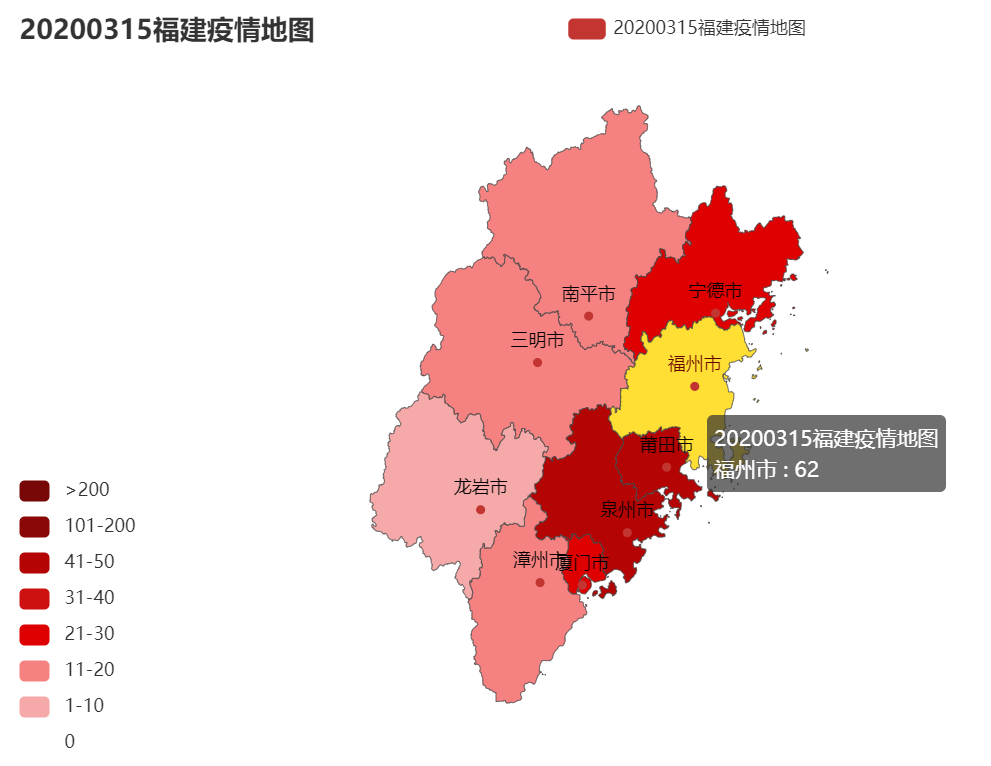
3.结对讨论
4.实现过程
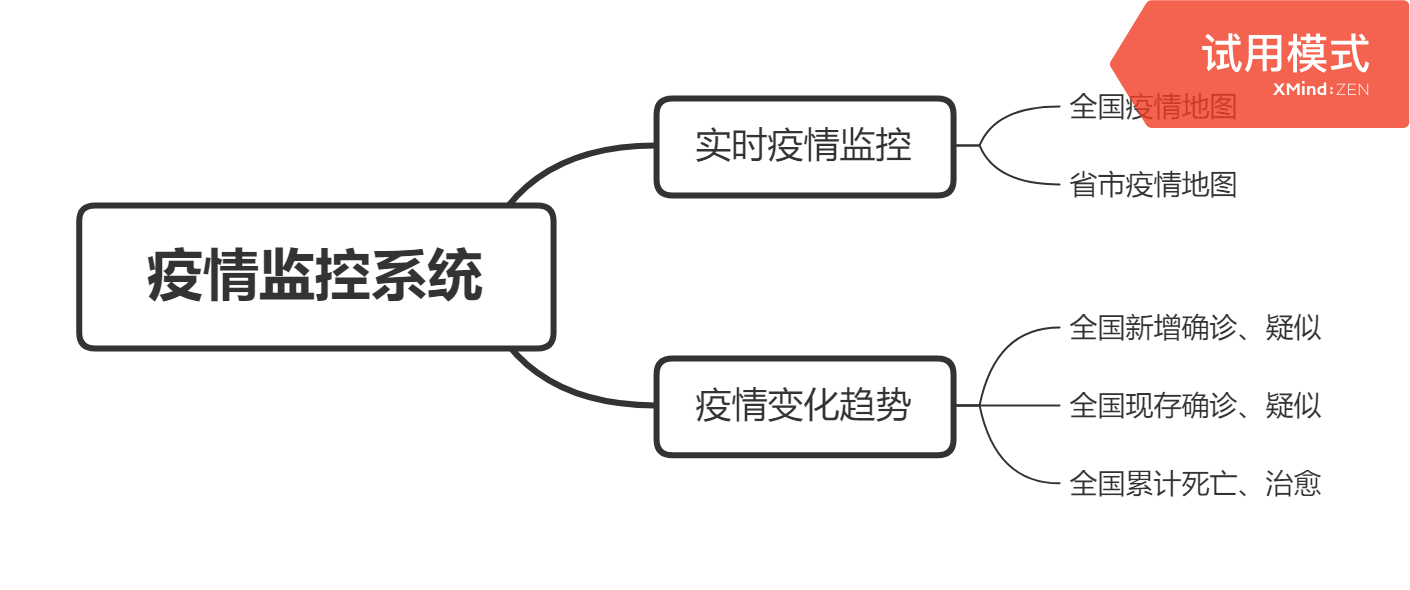
功能结构图
模块实现过程

5.代码说明
代码解释
本系统是基于Flask框架实现的web应用。用python网络爬虫获取丁香园的实时数据,用于绘制全国疫情分布地图,更新频率为每天一次。另外,疫情趋势图的数据来源为国家卫建委,根据官网每天发布的文档进行每日更新。
每个功能模块实现的思路一致,首先进行数据的采集和处理,准备需要用到的pyecharts地图。然后编写前端html代码,后再创建后台服务为前端页面提供数据传送,并为每个模块配置路由。
前端页面实现
<body>
<div id="map" style="1024px; height:600px;"></div>
<script>
$(
function () {
var chart = echarts.init(document.getElementById('map'), 'white', {renderer: 'canvas'});
$.ajax({
type: "GET",
url: "http://127.0.0.1:5000/mapChart",
dataType: 'json',
success: function (result) {
chart.setOption(result);
}
});
}
)
</script>
<div id="ConfNewLine" style="1024px; height:600px;"></div>
<script>
$(
function () {
var chart = echarts.init(document.getElementById('ConfNewLine'), 'white', {renderer: 'canvas'});
$.ajax({
type: "GET",
url: "http://127.0.0.1:5000/confChart",
dataType: 'json',
success: function (result) {
chart.setOption(result);
}
});
}
)
</script>
后台服务
def map_base()->Map:
province_distribution = {}
with open('data/province.csv', 'r', encoding="UTF-8") as f:
next(f)
dataLine = f.readline().strip("")
while dataLine != "":
tmpList = dataLine.split(",")
province_distribution[tmpList[1]] = int(tmpList[2])
dataLine = f.readline().strip("
")
f.close()
province = list(province_distribution.keys())
values = list(province_distribution.values())
c = (
Map()
.add("确诊人数", [list(z) for z in zip(province,values)], "china")
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title="全国疫情地图"),
visualmap_opts=opts.VisualMapOpts(max_= 100),)
)
return c
# 02. 疫情新增趋势图
def conf_new_base() -> Line:
df = pd.read_excel("data/linedata.xlsx",
usecols=[1],
names=None) # 读取项目名称列,不要列名
df_li = df.values.tolist()
dataY1 = []
dataY2 = []
dataX = []
for s_li in df_li:
dataY1.append(s_li[0])
ataY2.append(s_li[0])
dataX.append(s_li[0])
c = (
Line(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add_xaxis(dataX)
.add_yaxis("新增确诊", dataY1, is_smooth=True)
.add_yaxis("新增疑似", dataY2, is_smooth=True)
.set_global_opts(
title_opts=opts.TitleOpts(title="全国疫情新增确诊/疑似趋势图"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False),
)
)
return c
路由配置
@app.route("/")
def index():
content = table_base()
return render_template("index.html", content=content)
@app.route("/mapChart")
def get_map_chart():
c = map_base()
return c.dump_options_with_quotes()
@app.route("/confChart")
def get_conf_chart():
c = conf_new_base()
return c.dump_options_with_quotes()
@app.route("/confTotalChart")
def get_conf_total_chart():
c = conf_total_base()
return c.dump_options_with_quotes()
@app.route("/deadTotalChart")
def get_dead_total_chart():
c = dead_total_base()
return c.dump_options_with_quotes()
实时数据爬取及处理
class DxySARI(object):
def __init__(self):
self.start = 0
self.headers = {"User-Agent": random.choice(USER_AGENTS)}
self.dxyurl = 'https://3g.dxy.cn/newh5/view/pneumonia'
self.items = []
self.world_list = []
self.province_list = []
self.city_list = []
self.city_csv = '../data/city'
self.province_csv = '../data/province'
self.world_csv = '../data/world'
def get_html_page(self):
response = session.get(self.dxyurl)
page = response.html.html
# print(page)
start = page.find("window.getAreaStat = [")
# print(start)
temp = page[start+22:]
end = temp.find("]}catch(e){}")
temp = temp[0:end]
items = temp.split("]},")
last = items[-1]
items.pop()
newitems = []
for item in items:
item = item + "]}"
newitems.append(item)
# print(item)
newitems.append(last)
self.items = newitems
return newitems
def get_detail_info(self,items):
for item in items:
js = json.loads(item)
# print(js)
dc = {}
dc = dict(js)
self.province_list.append(dc)
# print(self.province_list)
cities = dc["cities"]
if cities:
for city in cities:
city["provinceName"] = dc["provinceName"]
self.city_list.append(city)
# print(city.keys())
print(self.province_list)
print(self.city_list)
def write_province_csv(self):
# filename = self.province_csv + getTime() + '.csv'
filename = self.province_csv + '.csv'
# print(filename)
header = ['provinceName', 'provinceShortName', 'currentConfirmedCount', 'confirmedCount', 'suspectedCount', 'curedCount', 'deadCount', 'comment', 'locationId', 'statisticsData', 'cities']
with open(filename, 'w', newline='',encoding='utf-8-sig') as csvfile:
file_pro = csv.writer(csvfile)
file_pro.writerow(header)
try:
for item in self.province_list:
#print(item.values())
file_pro.writerow(item.values())
except Exception as e:
print('Province数据写入异常' + e + '异常')
def write_city_csv(self):
# filename = self.city_csv + getTime() + '.csv'
filename = self.city_csv + '.csv'
# print(filename)
header = ['cityName', 'currentConfirmedCount', 'confirmedCount', 'suspectedCount', 'curedCount', 'deadCount', 'locationId', 'provinceName']
with open(filename, 'w', newline='',encoding='utf-8-sig') as csvfile:
file_city = csv.writer(csvfile)
file_city.writerow(header)
try:
for item in self.city_list:
#print(item.values())
file_city.writerow(item.values())
except Exception as e:
print('City数据写入异常' + e + '异常')
6.心路历程与收获
本次项目的实现是依赖于Flask框架进行开发的,并且需要用到Python,由于都是未接触过的知识,因此作业过程中碰了不少壁。由此深切感受到了多积累框架知识的重要性。
在结对编程中,任何一段代码都至少被两双眼睛看过,被两个脑袋思考过。代码被不断地复审,这样可以避免牛仔式的编程。同时,结对编程避免了“我的代码”还是“他的代码”的问题,使得代码的责任不属于某个人,而是属于两个人,进而属于整个团队,这样能够帮助团队成员建立集体拥有代码的意识,在一定程度 上避免了个人英雄主义。结对编程的过程也是一个互相督促的过程,每个人的一 举一动都在别人的视线之内,所有的想法都要受到对方的评价。这种督促的压 力,使得程序员更认真地工作。结对编程“迫使”程序员必须频繁地交流,而且要 提高自己的技术能力,以免被别人小看。但是要注意,每个人每天的高效率工作 时段不超过3—4个小时。结对编程中驾驶员和领航员的角色要经常互换,避免长 时间紧张工作而导致观察力和判断力下降。一对程序员完成预定任务之后,就可以休息,或者开展其他较轻松的工作。而不应该死板地按照工作日八小时的规定而继续编程。什么样的人适合结对编程?极限编程对工程师提出了更高的要求。 这种要求不关乎技术水平,也不关乎学历水平或工作经验。这种要求是对一个人的心智、道德修养的更高要求。结对编程中,编码不再是私人的工作,而是一种公开的“表演”。程序员的代码、工作方式、技术水平都变得公开和透明。-----------摘自《构建之法》
队友评价:
两人coding能力都有些薄弱,但队友整理数据和写文档很赞,总之一起肝作业的经历惨痛又难忘