1、给一个单词a,如果通过交换单词中字母的顺序可以得到另外的单词b,那么b是a的兄弟单词,比如的单词army和mary互为兄弟单词。
解析:
现在要给出一种解决方案,对于用户输入的单词,根据给定的字典找出输入单词有哪些兄弟单词。请具体说明数据结构和查询流程,要求时间和空间效率尽可能地高。
字典树的典型应用,一般情况下,字典树的结构都是采用26叉树进行组织的,每个节点对应一个字母,查找的时候,就是一个字母一个字母的进行匹配,算法的时间复杂度就是单词的长度n,效率很高。因此这个题目可以定义一个字典树作为数据结构来查询的,时间效率会很高,这样就转化为在一棵字典树中查找兄弟单词,只要在字典树中的前缀中在存储一个vector结构的容器,这样查找起来就是常数级的时间复杂度了,效率很高的。。
数据结构可以定义如下:
1 struct word 2 { 3 vector<string> brother; // 用于保存每个单词的兄弟单词 4 word *next[26]; // 字典树中每个节点代表一个字符,并指向下一个字符 5 };
如上述数据结构所示,字典树的建立是在预处理阶段完成的,首先根据字典中的单词来建立字典树,建立的时候,需要稍微特殊处理一下,就是比如pots、stop和tops互为兄弟单词,那么在字典中按照首字母顺序的话,应该先遇到pots单词,那么我首先对其进行排序,结果是opts,那么字典树中就分别建立4个节点,分别为o->p->t->s,当然这个是不同层次的,在节点s处的vector容器brother中添加单词pots,遇到stop的时候,同样的方法,排序是opts,此时发现这4个节点已经建立了,那么只需要在第四个节点s处的vector容器brother中添加单词stop,tops单词的处理方法是同样的。
这样建立完字典树后,查询兄弟单词的效率就会很高了,比哈希的效率还要高;查到tops的兄弟的单词的时候,首先排序,那么就是opts,然后在字典树中查找opts,在s处将其vector容器brother中的的单词输出就是tops的所有兄弟单词。
其他思路:
思路一:
1. 关键时怎么定义一个key,使得兄弟单词有相同的key,不是兄弟的单词有不同的key。例如,将单词按字母从小到大重新排序后作为其key,比如bad的key为abd。
2. 先做一个预处理,遍历字典,使用链表将所有兄弟单词串在一起,hash_map的key为单词的key,value为链表。将每个单词都按照key加入到对应的链表当中。
3. 当需要找兄弟单词时,只需求取这个单词的key,然后到hash_map中找到对应的链表即可。
简单代码:
1 string GetKey(const string& word)//每个单词的关键字key 2 { 3 string key(word); 4 sort(key.begin(), key.end()); 5 return key; 6 } 7 //从字典文件中读取单词,建立map,关键字为单词的关键字key 8 void CreateDic(const char* file, map<string,list<string> > Dic) 9 { 10 ifstream fin(file); 11 string word,key; 12 while(fin>>word && !word.empty()) 13 { 14 key = GetKey(word); 15 Dic[key].push_back(word); 16 } 17 fin.close(); 18 } 19 //查找单词的兄弟单词,存放在ans中 20 void WordSearch(const string& word, map<string,list<string> >& Dic,list<string>& ans) 21 { 22 string key = GetKey(word); 23 //if(Dic.count(key) == 0)//是否需要更新词典 24 // Dic[key].push_back(word); 25 if(Dic.count(key) != 0) 26 copy(Dic[key].begin(), Dic[key].end(), back_inserter(ans)); 27 }
思路2:
在思路1中主要的问题是key的求取需要较多时间,从这里着手,我们换一个求key的方法:
可以直接定义一个映射关系,每个字母对应一个素数:
a=2 b=3 c=5 d=7 e=11 f=13 g=17
h=19 i=23 j=29 k=31 l=37 m=41 n=43
o=47 p=53 q=59 r=61 s=67 t=71
u=73 v=79 w=83 x=89 y=97 z=101
将每个单词所有字母的素数相乘,可以确保兄弟单词的key相同,非兄弟单词的key不同。
唯一的问题是可能key的结果太大,可以使用Java的BigInteger类。
2、系统中维护了若干数据项,我们对数据项的分类可以分为三级,首先我们按照一级分类方法将数据项分为A、B、C......若干类别,每个一级分类方法产生的类别又可以按照二级分类方法分为a、b、c......若干子类别,同样,二级分类方法产生的类别又可以按照是三级分类方法分为i、ii、iii......若干子类别,每个三级分类方法产生的子类别中的数据项从1开始编号。我们需要对每个数据项输出日志,日志的形式是key_value对,写入日志的时候,用户提供三级类别名称、数据项编号和日志的key,共五个key值,例如,write_log(A,a,i,1,key1),获取日志的时候,用户提供三级类别名称、数据项编号,共四个key值,返回对应的所有的key_value对,例如get_log(A,a,i,1,key1),
请描述一种数据结构来存储这些日志,并计算出写入日志和读出日志的时间复杂度。
分析:
多级分类对应多级hash_map。
4、数组al[0,mid-1]和al[mid,num-1]是各自有序的,对数组al[0,num-1]的两个子有序段进行merge,得到al[0,num-1]整体有序。要求空间复杂度为O(1)。注:al[i]元素是支持'<'运算符的。
分析:
代码如下所示。
1 /* 2 数组a[begin, mid] 和 a[mid+1, end]是各自有序的,对两个子段进行Merge得到a[begin , end]的有序数组。 要求空间复杂度为O(1) 3 方案: 4 1、两个有序段位A和B,A在前,B紧接在A后面,找到A的第一个大于B[0]的数A[i], A[0...i-1]相当于merge后的有效段,在B中找到第一个大于A[i]的数B[j], 5 对数组A[i...j-1]循环右移j-k位,使A[i...j-1]数组的前面部分有序 6 2、如此循环merge 7 3、循环右移通过先子段反转再整体反转的方式进行,复杂度是O(L), L是需要循环移动的子段的长度 8 */ 9 #include<iostream> 10 using namespace std; 11 12 void Reverse(int *a , int begin , int end ) //反转 13 { 14 for(; begin < end; begin++ , end--) 15 swap(a[begin] , a[end]); 16 } 17 void RotateRight(int *a , int begin , int end , int k) //循环右移 18 { 19 int len = end - begin + 1; //数组的长度 20 k %= len; 21 Reverse(a , begin , end - k); 22 Reverse(a , end - k + 1 , end); 23 Reverse(a , begin , end); 24 } 25 26 // 将有序数组a[begin...mid] 和 a[mid+1...end] 进行归并排序 27 void Merge(int *a , int begin , int end ) 28 { 29 int i , j , k; 30 i = begin; 31 j = 1 + ((begin + end)>>1); 32 while(i <= end && j <= end && i<j) 33 { 34 while(i <= end && a[i] < a[j]) 35 i++; 36 k = j; //暂时保存指针j的位置 37 while(j <= end && a[j] < a[i]) 38 j++; 39 if(j > k) 40 RotateRight(a , i , j-1 , j-k); //数组a[i...j-1]循环右移j-k次 41 i += (j-k+1); 42 //第一个指针往后移动,因为循环右移后,数组a[i....i+j-k]是有序的 43 } 44 } 45 46 void MergeSort(int *a , int begin , int end ) 47 { 48 if(begin == end) 49 return ; 50 int mid = (begin + end)>>1; 51 MergeSort(a , begin , mid); //递归地将a[begin...mid] 归并为有序的数组 52 MergeSort(a , mid+1 , end); //递归地将a[mid+1...end] 归并为有序的数组 53 Merge(a , begin , end); //将有序数组a[begin...mid] 和 a[mid+1...end] 进行归并排序 54 } 55 56 int main(void) 57 { 58 int n , i , a[20]; 59 while(cin>>n) 60 { 61 for(i = 0 ; i < n ; ++i) 62 cin>>a[i]; 63 MergeSort(a , 0 , n - 1); 64 for(i = 0 ; i < n ; ++i) 65 cout<<a[i]<<" "; 66 cout<<endl; 67 } 68 return 0; 69 }
5、线程和进程的区别及联系?如何理解“线程安全”问题?
分析:
进程和线程都是由操作系统所体会的程序运行的基本单元,系统利用该基本单元实现系统对应用的并发性。
1、简而言之,一个程序至少有一个进程,一个进程至少有一个线程.
2、线程的划分尺度小于进程,使得多线程程序的并发性高。
3、另外,进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。
4、线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
5、从逻辑角度来看,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。这就是进程和线程的重要区别。
线程安全:由于多线程之间共享内存和其他资源,因而就有了一个新的概念:多线程安全。试想,如果多个线程共享同一段代码,那么同时运行的时候,如果没有相应的机制(例如锁机制),就会产生不确定的结果,这就是非线程安全的。因而线程安全就是指多线程之间同步运行的时候不会产生莫名其妙或者不确定的结果(由于多线程执行的顺序是不可见和不可预知的),或者,通俗点讲,多线程下的线程安全就是多个线程同步工作的情况下,运行的结果和单线程运行的情况下没有什么区别,大多数情况下,这就是线程安全的。
算法与程序设计一
网页爬虫在抓取网页时,从指定的URL站点入口开始爬取这个站点上的所有URL link,抓取到下一级link对应的页面后,同样对页面上的link进行抓取从而完成深度遍历。为简化问题,我们假设每个页面上至多只有一个link,如从www.baidu.com/a.html链接到www.baidu.com/b.html再链到www.baidu.com/x.html,当爬虫抓取到某个页面时,有可能再链回www.baidu.com/b.html,也有可能爬取到一个不带任何link的终极页面。当抓取到相同的URL或不包含任何link的终极页面时即完成爬取。爬虫在抓取到这些页面后建立一个单向链表,用来记录抓取到的页面,如:a.html->b.html->x.html...->NULL。
问:
对于爬虫分别从www.baidu.com/x1.html和www.baidu.com/x2.html两个入口开始获得两个单向链表,得到这两个单向链表后,如何判断他们是否抓取到了相同的URL?(假设页面URL上百亿,存储资源有限,无法用hash方法判断是否包含相同的URL)
请先描述相应的算法,再给出相应的代码实现。(只需给出判断方法代码,无需爬虫代码)
分析:
两个单向链表的相交问题。
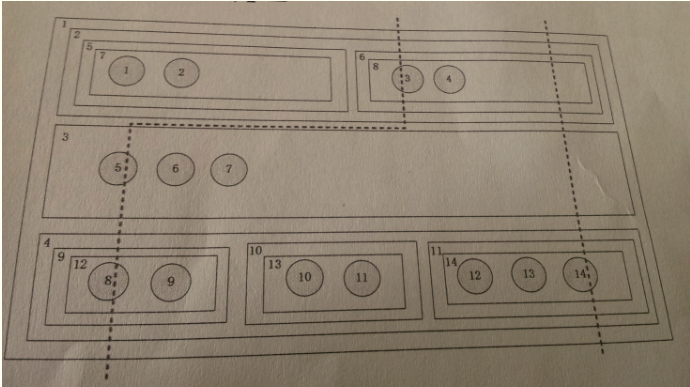
4、有一种结构如下图所示,它由层的嵌套组成,一个父层中只能包含垂直方向上或者是水平方向上并列的层,例如,层1可以包含2、3、4三个垂直方向上的层,层2可以包含5和6两个水平方向的层,在空层中可以包含数据节点,所谓的空层是指不包含子层的层,每个空层可以包含若干个数据节点,也可以一个都不包含。
在这种结构上面,我们从垂直方向上划一条线,我们约定每一个子层中我们只能经过一个数据节点,在这种情况下,每条线可以经过多个数据节点,也可以不经过任何数据节点,例如,线1经过了3、5、8三个数据节点,线2只经过了14个数据节点。
(1)给出函数,实现判断两个数据节点,是否可能同时被线划中,给出具体的代码。
(2)给出函数,输出所有一条线可以划中的数据节点序列, 可以给出伪代码实现。
系统设计题
1、相信大家都使用过百度搜索框的suggestion功能,百度搜索框中的suggestion提示功能如何实现?请给出实现思路和主要的数据结构、算法。有什么优化思路可以使得时间和空间效率最高?
分析:
常见的Ajax提示框的实现是基于字典树,根据前缀扫出相应的单词(热点词),最后根据top K算法求出前K个热点词。并展示给用户。应用字典树来求前缀和TOP K对热词进行统计排序。。这里是用数据库保存数据,而查询的时候是通过数据库委托的like取相应的前缀查询,因而掩盖了很多数据结构和算法的细节。实际应用中,每个热词可能还有相应的计数或者权重,根据权重选取相应的热词并取top K进行展示。
也可以建立倒排索引。
2、两个200G大小的文件A和B,AB文件里内容均为无序的一行一个正整数字(不超过2^63),请设计方案,输出两个文件中均出现过的数字,使用一台内存不超过16G、磁盘充足的机器。
方案中指明使用java编程时使用到的关键工具类,以及为什么?
分析:
又是海量数据的处理,大型互联网公司最爱做的面试无非就是这些个问题:top K,求相同,大文件统计ip,统计在线人数。为什么现在硬件大大发展的情况下我们还要谈海量数据处理,大概是因为:利用有限的资源处理更多的事情,本身就是一个很有挑战性的课题。而这些问题,最重要的是思路。
对于本题。由于两个文件的大小都大大超过了内存的限制。因而不能直接放入内存。可考虑对文件进行hash分为多个小文件(根据每一行的值)。hash的文件由于相同的key都存在一个文件中,因而只需要比较相同的文件中的数字。最后归并之,得到所有的A文件和B文件中相同的数字。
补充:
1、面向对象设计的三个基本要素和五个基本原则。
分析:
面向对象设计的三个基本要素:封装、继承、多态。
面向对象设计的五个基本原则:
单一职责原则:一个类,最好只做一件事情,只有一个引起它的变化。
开放封闭原则:软件实体应该是可扩展的,而不可修改的。
Liskov替换原则:子类必须能够替换器基类。
依赖倒置原则:依赖于抽象。
接口隔离原则:使用多个小的专门的接口,而不要使用一个大的总接口。
2、给定一个凸四边形,如何判断一个点在这个凸四边形内还是外?
分析:
如果一个点在这个凸四边形内,那么按照逆时针方向走的话,该点一定会在每一条的左边。
所以方法就是:按照逆时针方向遍历这个凸四边形的每一条边的两个顶点A(X1,Y1)和B(X2,Y2),然后判断给定点是否在AB矢量左边就可以了。
而判断一个点是否在一个矢量的左边,可以利用矢量叉积。
设A(x1,y1),B(x2,y2),给定点是C(x3,y3),构造两条矢量边:
AB=(x2-x1,y2-y1), AC=(x3-x1,y3-y1)
则AB和AC的叉积为(2*2的行列式):
|x2-x1, y2-y1|
|x3-x1, y3-y1|
值为:r = (x2-x1)(y3-y1) - (y2-y1)(x3-x1)
然后利用右手法则进行判断:
如果r > 0,则点C在矢量AB的左边
如果r < 0,则点C在矢量AB的右边
这样就可以判断点C与AB的相对位置了。然后按照逆时针方向,对凸四边形的每一条边都如此判断,如果每次都判断出C在左边,那么就说明这个点在凸多边形内部了。
3、有N个节点,每两个节点相邻,每个节点只与2个节点相邻,因此,N个顶点有N-1条边。每一条边上都有权值wi,定义节点i到节点i+1的边为wi。
求:不相邻的权值和最大的边的集合。
分析:
对于这个问题可能看起来不是很好处理,把问题更加规范一些:给出一个数组,求出其中一个子集,使得子集中每个元素在原数组中两两都不相邻并使子集的和最大。
因为不能选择两个相邻的元素,那么对于第i个元素的选择的可能性就包含选择i和不选择i个元素,至于选与不选,其实是和第i-1个元素有直接关系的。
考虑两种情况:
(1)选择i,那么第i-1个元素一定不能选;
(2)不选择i,那么第i-1个元素是可以选的,也可以不选的,这决定于第i-2个元素对i-1的影响;
从这两种情况中可以看出,如果知道第i-1次被选中和不被选中时前i个元素(元素下标从0开始计算)了最大子集和,那么我们可以算出选择i和不选择i各可以获得的最大子集和。
那么我们可以得到一个这样的公式, 其中DS[i]记录第i个元素被选中时的前i+1个元素的最大子集和。 NS[i]记录第i个元素未被选中时的前i+1个元素的最大子集和:
接下来看一下例子,假设现在有一个8个元素的数组:
1 7 4 0 9 4 8 8
那么 NS数组为:
0 1 7 7 7 16 16 24
DS数组为
1 7 5 7 16 11 24 24
具体代码如下所示。
1 #include <iostream> 2 #include <string.h> 3 #include <stdlib.h> 4 using namespace std; 5 6 7 #define NMax 1000 8 9 int data[NMax]; 10 int table[NMax][2]; 11 12 int GetMaxSubsetSum(int len) 13 { 14 memset(table, 0 , sizeof(table)); 15 //第0行表示NS,表示该元素未被选中 16 //第一行表示DS,表示该元素被选中 17 table[0][0] = 0; 18 table[0][1] = data[0]; 19 20 //动态规划 过程 21 for (int i = 1; i < len; ++i) 22 { 23 table[i][0] = max(table[i-1][1], table[i-1][0]); 24 table[i][1] = table[i-1][0] + data[i]; 25 } 26 27 //打印原始数组 28 for (int i = 0; i < len; ++i) 29 cout << data[i] <<" "; 30 cout <<endl; 31 32 //打印NS数组 33 for (int i = 0; i < len; ++i) 34 cout << table[i][0] <<" "; 35 cout <<endl; 36 37 //打印DS数组 38 for (int i = 0; i < len; ++i) 39 cout << table[i][1] <<" "; 40 cout <<endl; 41 42 //返回整个数组的最大值 43 return max(table[len-1][0], table[len-1][1]); 44 } 45 46 int main() 47 { 48 int len; cin >> len; 49 if (len <= 0)return 1; 50 for (int i = 0; i < len ; ++i) 51 { 52 data[i] = rand()% 10; 53 } 54 55 cout << GetMaxSubsetSum(len)<<endl; 56 }
3、简述数据库以及线程死锁产生的原理以及必要条件,简述如何避免死锁。
分析:
数据库是以一定组织方式存储在一起的,能为多个用户共享的,具有尽可能小的冗余度的、与应用彼此独立的相互关联的数据集合。包括关系、网状、层次等类型的数据库。
4、字母a-z,数字0-9,现需要其中任意3个作为密码,请输出所有可能组合。(伪码CC++JAVA)(10分)
分析:
组合问题。
5、用递归算法写一个函数,求字符串最长连续字符的长度,比如aaaabbcc的长度为4,aabb的长度为2,ab的长度为1。
分析:
1 int findContinuousCharacter(char *pStr) 2 { 3 if(*pStr == '�') 4 { 5 return 0; 6 } 7 if(*(pStr + 1) == '�') 8 { 9 return 1; 10 } 11 12 if(*pStr == *(pStr + 1)) 13 { 14 return 1 + find(pStr + 1); 15 } 16 17 return find(pStr + 1); 18 } 19 int main() 20 { 21 char str[] = "daac"; 22 cout<<find(str)<<endl; 23 }
5、 假设一个大小为100亿个数据的数组,该数组是从小到大排好序的,现在该数组分成若干段,每个段的数据长度小于20「也就是说:题目并没有说每段数据的size 相同,只是说每个段的 size < 20 而已」,然后将每段的数据进行乱序(即:段内数据乱序),形成一个新数组。请写一个算法,将所有数据从小到大进行排序,并说明时间复杂度。
分析:
思路一、如@四万万网友所说:维护一个20个元素大小的小根堆,然后排序,每次pop取出小根堆上最小的一个元素(log20),然后继续遍历原始数组后续的(N-20)个元素,总共pop (N-20)次20个元素小根堆的log20的调整操作。
思路二@飘零虾、如果原数组是a[],那么a[i+20]>=a[i]恒成立(因为每段乱序区间都是小于20的,那么向后取20,必然是更大的区间的元素)。
第一个数组:取第0、20、40、60、80...
第二个数组:取第1、21、41、61、81...
...
第20个数组:取第19、39、59、79... (上述每个数组100亿/20 个元素)
共计20个数组,每个数组100亿/20 个元素「注:这5亿个元素已经有序,不需要再排序」,且这20个数组都是有序的,然后对这20个数组进行归并,每次归并20个元素。时间复杂度跟上述思路一一样,也是N*logK(N=100亿,K=20)。
此外,读者@木叶漂舟直接按每组20个排序,将排好的20个与前20个调整拼接,调整两端接头处的元素,写了个简单地demo: http://t.cn/zlELAzs。不过,复杂度有点高,目前来说中规中矩的思路还是如上文中@四万万网友 所说思路一「@张玮-marihees按照思路一:http://weibo.com/1580904460/z1v5jxJ9P,写了一份代码:http://codepad.org/T5jIUFPG,欢迎查看」。
说明:以上补充内容来自于网友,谢谢各位。
转载请注明:http://www.cnblogs.com/iloveyouforever/
2013-11-18 20:25:17