一 HDFS HA架构图
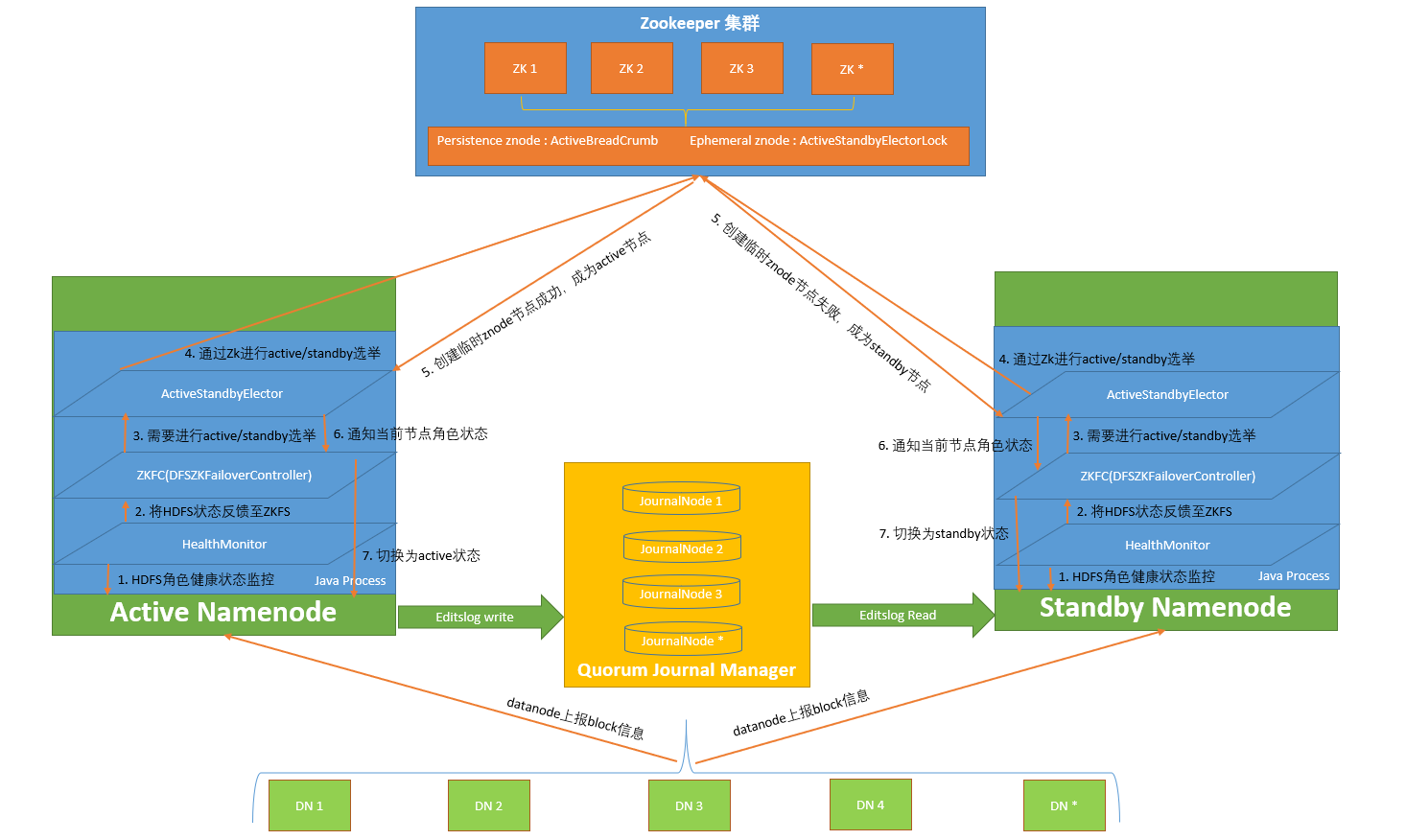
二 HDFS HA组件
- Active NameNode和Standby NameNode
在NameNode的HA方案中有两个不同状态的NameNode,分别为活跃态(Active)和备用状态(Standby),其中只有Active NameNode能对外提供服务,Standby NameNode会根据Active NameNode的状态变化,在必要时可切换成Active.
- ZKFC
ZKFC即ZKFailoverController,是基于Zookeeper的故障转移控制器,它负责控制NameNode的主备切换,ZKFC会监测NameNode的健康状态,当发现Active NameNode出现异常时会通过Zookeeper进行一次新的选举,完成Active和Standby状态的切换
- HealthMonitor
周期性调用NameNode的HAServiceProtocol RPC接口(monitorHealth 和 getServiceStatus),监控NameNode的健康状态并向ZKFC反馈
- ActiveStandbyElector
接收ZKFC的选举请求,通过Zookeeper自动完成主备选举,选举完成后回调ZKFC的主备切换方法对NameNode进行Active和Standby状态的切换.
- DataNode
NameNode包含了HDFS的元数据信息和数据块信息(blockmap),其中数据块信息通过DataNode主动向Active NameNode和Standby NameNode上报
- 共享存储系统
共享存储系统负责存储HDFS的元数据(EditsLog),Active NameNode(写入)和 Standby NameNode(读取)通过共享存储系统实现元数据同步,在主备切换过程中,新的Active NameNode必须确保元数据同步完成才能对外提供服务
三 HDFS详细切换过程
1. HealthMonitor监控namenode节点和集群状态
ZKFailoverController 在初始化的时候会创建 HealthMonitor,HealthMonitor 在内部会启动一个线程来循环调用 NameNode 的 HAServiceProtocol RPC 接口的方法来检测 NameNode 的状态,并将状态的变化通过回调的方式来通知 ZKFailoverController。
HealthMonitor 主要检测 NameNode 的两类状态,分别是 HealthMonitor.State 和 HAServiceStatus。
1) HealthMonitor.State
HealthMonitor.State 是通过 HAServiceProtocol RPC 接口的 monitorHealth 方法来获取的,反映了 NameNode 节点的健康状况,主要是磁盘存储资源是否充足。HealthMonitor.State 包括下面几种状态:
- INITIALIZING
HealthMonitor 在初始化过程中,还没有开始进行健康状况检测;
- SERVICE_HEALTHY
NameNode 状态正常;
- SERVICE_NOT_RESPONDING
调用 NameNode 的 monitorHealth 方法调用无响应或响应超时;
- SERVICE_UNHEALTHY
NameNode 还在运行,但是 monitorHealth 方法返回状态不正常,磁盘存储资源不足;
- HEALTH_MONITOR_FAILED
HealthMonitor 自己在运行过程中发生了异常,不能继续检测 NameNode 的健康状况,会导致 ZKFailoverController 进程退出;
HealthMonitor.State 在状态检测之中起主要的作用,在 HealthMonitor.State 发生变化的时候,HealthMonitor 会回调 ZKFailoverController 的相应方法来进行处理,具体处理见后文 ZKFailoverController 部分所述。
2)HAServiceStatus
HAServiceStatus 则是通过 HAServiceProtocol RPC 接口的 getServiceStatus 方法来获取的,主要反映的是 NameNode 的 HA 状态,包括:
- INITIALIZING
NameNode 在初始化过程中
- ACTIVE
当前 NameNode 为主 NameNode
- STANDBY
当前 NameNode 为备 NameNode
- STOPPING
当前 NameNode 已停止
HAServiceStatus 在状态检测之中只是起辅助的作用,在 HAServiceStatus 发生变化时,HealthMonitor 也会回调 ZKFailoverController 的相应方法来进行处理。
2. ActiveStandbyElector 选举与注册监听
为了便于理解,查看HDFS在zookeeper集群创建的 znode信息
[zk: sht-sgmhadoopdn-03:2181(CONNECTED) 2] ls /hadoop-ha/mycluster [ActiveBreadCrumb, ActiveStandbyElectorLock] zk: sht-sgmhadoopdn-03:2181(CONNECTED) 3] get /hadoop-ha/mycluster/ActiveBreadCrumb myclusternn1sht-sgmhadoopnn-01 �>(�> cZxid = 0x100000011 ctime = Thu Mar 28 00:02:38 CST 2019 mZxid = 0x100000014 mtime = Thu Mar 28 00:13:15 CST 2019 pZxid = 0x100000011 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 42 numChildren = 0 [zk: sht-sgmhadoopdn-03:2181(CONNECTED) 4] get /hadoop-ha/mycluster/ActiveStandbyElectorLock myclusternn1sht-sgmhadoopnn-01 �>(�> cZxid = 0x100000013 ctime = Thu Mar 28 00:13:13 CST 2019 mZxid = 0x100000013 mtime = Thu Mar 28 00:13:13 CST 2019 pZxid = 0x100000013 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x169bfa59c6a0002 dataLength = 42 numChildren = 0
1)ActiveStandbyElector 选举
Namenode(包括 YARN ResourceManager) 的主备选举是通过 ActiveStandbyElector 来完成的,ActiveStandbyElector 主要是利用了 Zookeeper 的写一致性和临时节点机制,具体的主备选举实现如下:创建锁节点 如果 HealthMonitor 检测到对应的 NameNode 的状态正常,那么表示这个 NameNode 有资格参加 Zookeeper 的主备选举。如果目前还没有进行过主备选举的话,那么相应的 ActiveStandbyElector 就会发起一次主备选举,尝试在 Zookeeper 上创建一个路径为/hadoop-ha//ActiveStandbyElectorLock 的临时节点 (${dfs.nameservices} 为 Hadoop 的配置参数 dfs.nameservices 的值,下同),Zookeeper 的写一致性会保证最终只会有一个节点的ActiveStandbyElector 创建成功,那么创建成功的 ActiveStandbyElector 对应的 NameNode 就会成为主 NameNode,ActiveStandbyElector 会回调ZKFailoverController 的方法进一步将对应的 NameNode 切换为 Active 状态。而创建失败的 ActiveStandbyElector 对应的 NameNode 成为备 NameNode,ActiveStandbyElector 会回调 ZKFailoverController 的方法进一步将对应的 NameNode 切换为 Standby 状态。
2)ActiveStandbyElector 注册监听
不管创建/hadoop-ha//ActiveStandbyElectorLock 节点是否成功,ActiveStandbyElector 随后都会向 Zookeeper 注册一个 Watcher 来监听这个节点的状态变化事件,ActiveStandbyElector 主要关注这个节点的 NodeDeleted 事件。
自动触发主备选举
如果 Active NameNode 对应的 HealthMonitor 检测到 NameNode 的状态异常时, ZKFailoverController 会主动删除当前在 Zookeeper 上建立的临时节点/hadoop-ha//ActiveStandbyElectorLock,这样处于 Standby 状态的 NameNode 的 ActiveStandbyElector 注册的监听器就会收到这个节点的 NodeDeleted 事件。收到这个事件之后,会马上再次进入到创建/hadoop-ha//ActiveStandbyElectorLock 节点的流程,如果创建成功,这个本来处于 Standby 状态的 NameNode 就选举为主 NameNode 并随后开始切换为 Active 状态。
当然,如果是 Active 状态的 NameNode 所在的机器整个宕掉的话,那么根据 Zookeeper 的临时节点特性,/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 节点会自动被删除,从而也会自动进行一次主备切换。
3. HDFS防止脑裂现象
Zookeeper 在工程实践的过程中经常会发生的一个现象就是 Zookeeper 客户端“假死”,所谓的“假死”是指如果 Zookeeper 客户端机器负载过高或者正在进行 JVM Full GC,那么可能会导致 Zookeeper 客户端到 Zookeeper 服务端的心跳不能正常发出,一旦这个时间持续较长,超过了配置的 Zookeeper Session Timeout 参数的话,Zookeeper 服务端就会认为客户端的 session 已经过期从而将客户端的 Session 关闭。“假死”有可能引起分布式系统常说的双主或脑裂 (brain-split) 现象。具体到本文所述的 NameNode,假设 NameNode1 当前为 Active 状态,NameNode2 当前为 Standby 状态。如果某一时刻 NameNode1 对应的 ZKFailoverController 进程发生了“假死”现象,那么 Zookeeper 服务端会认为 NameNode1 挂掉了,根据前面的主备切换逻辑,NameNode2 会替代 NameNode1 进入 Active 状态。但是此时 NameNode1 可能仍然处于 Active 状态正常运行,即使随后 NameNode1 对应的 ZKFailoverController 因为负载下降或者 Full GC 结束而恢复了正常,感知到自己和 Zookeeper 的 Session 已经关闭,但是由于网络的延迟以及 CPU 线程调度的不确定性,仍然有可能会在接下来的一段时间窗口内 NameNode1 认为自己还是处于 Active 状态。这样 NameNode1 和 NameNode2 都处于 Active 状态,都可以对外提供服务。这种情况对于 NameNode 这类对数据一致性要求非常高的系统来说是灾难性的,数据会发生错乱且无法恢复。Zookeeper 社区对这种问题的解决方法叫做 fencing,中文翻译为隔离,也就是想办法把旧的 Active NameNode 隔离起来,使它不能正常对外提供服务。
ActiveStandbyElector 为了实现 fencing,会在成功创建 Zookeeper 节点 hadoop-ha//ActiveStandbyElectorLock 从而成为 Active NameNode 之后,创建另外一个路径为/hadoop-ha//ActiveBreadCrumb 的持久节点,这个节点里面保存了这个 Active NameNode 的地址信息。Active NameNode 的 ActiveStandbyElector 在正常的状态下关闭 Zookeeper Session 的时候 (注意由于/hadoop-ha//ActiveStandbyElectorLock 是临时节点,也会随之删除),会一起删除节点/hadoop-ha//ActiveBreadCrumb。但是如果 ActiveStandbyElector 在异常的状态下 Zookeeper Session 关闭 (比如前述的 Zookeeper 假死),那么由于/hadoop-ha//ActiveBreadCrumb 是持久节点,会一直保留下来。后面当另一个 NameNode 选主成功之后,会注意到上一个 Active NameNode 遗留下来的这个节点,从而会回调 ZKFailoverController 的方法对旧的 Active NameNode 进行 fencing。
如果 ActiveStandbyElector 选主成功之后,发现了上一个 Active NameNode 遗留下来的/hadoop-ha//ActiveBreadCrumb 节点 ,那么 ActiveStandbyElector 会首先回调 ZKFailoverController 注册的 fenceOldActive 方法,尝试对旧的 Active NameNode 进行 fencing,在进行 fencing 的时候,会执行以下的操作:
首先尝试调用这个旧 Active NameNode 的 HAServiceProtocol RPC 接口的 transitionToStandby 方法,看能不能把它转换为 Standby 状态。
如果 transitionToStandby 方法调用失败,那么就执行 Hadoop 配置文件之中预定义的隔离措施,Hadoop 目前主要提供两种隔离措施,通常会选择 sshfence:
sshfence:通过 SSH 登录到目标机器上,执行命令 fuser 将对应的进程杀死;
shellfence:执行一个用户自定义的 shell 脚本来将对应的进程隔离;
只有在成功地执行完成 fencing 之后,选主成功的 ActiveStandbyElector 才会回调 ZKFailoverController 的 becomeActive 方法将对应的 NameNode 转换为 Active 状态,开始对外提供服务。