py编码骨灰级总结
思路: python执行py文件步骤--py2/3定义变量时unicode差异
1,py2 py3执行py文件的步骤
2,py2 定义变量x='mao'
1.x='mao', # 以文件头编码,因此出现内存中不一定全是unicode
2,x=u'mao' # 等同于 x='mao'.decode('gbk'),从这里可以看出,站在unicode角度想问题
1,unicode在内存中
2,unicode内存存在硬盘,需encode,因此unicode可以encode到任意编码
3,py3 定义变量x='mao'
默认就是x=u'maotai'
4,乱码问题
1,存文件时候乱码
2,读文件时乱码
5.python加载第一步时候乱码
1,理解notepad++打开文件原理
2,理解pycharm打开文件原理
3,理解open()+r模式打开文件读取本质
4,python解释器先读文件
如果文件utf8编码
py2默认以ascii加载
可在py文件头指定
py3默认以utf8加载
6,py文件头指定的编码会影响啥?
1.影响py2加载py文件时
2.影响py2自定义变量.
7,注意py2的,转unicode时候传的是自己.(下面有代码)
8, print函数会自动decode成终端的编码, 如果想看内存中数据,需要print 列表形式.
- py2中定义变量以文件头编码
#coding:gbk
x='上'
y='下'
print([x,y]) #['xc9xcf', 'xcfxc2']
#x代表16进制,此处是c9cf总共4位16进制数,一个16进制四4个比特位,4个16进制数则是16个比特位,即2个Bytes,这就证明了按照gbk编码中文用2Bytes
# 这里我可以把它decode成unicode编码
y='下'.decode('gbk') # 或
y=u'下'
print乱码:
1,将unicode print即可,如果不是unicode则转为unicde后print, 终端编码
2,以什么方式encode,就以什么方式decode.
内容编码+文件打开编辑器编码要一致.
py3定义个变量:
x='maotai' # 以unicode存储
print(x) # print函数自定以终端编码解码
编码及ascii
字符串要存储到硬盘里,必须先变成二进制,因为硬盘只能存二进制. 如何变, 需要做一步操作,即encode.
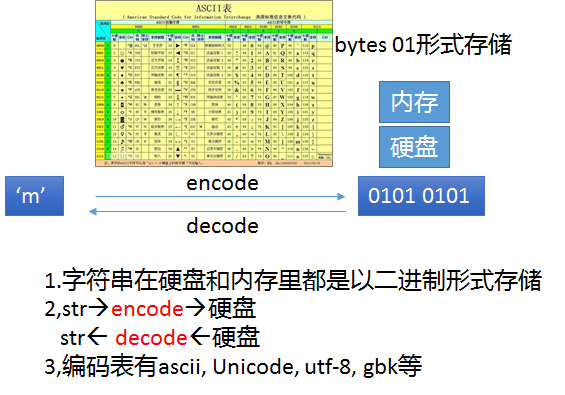
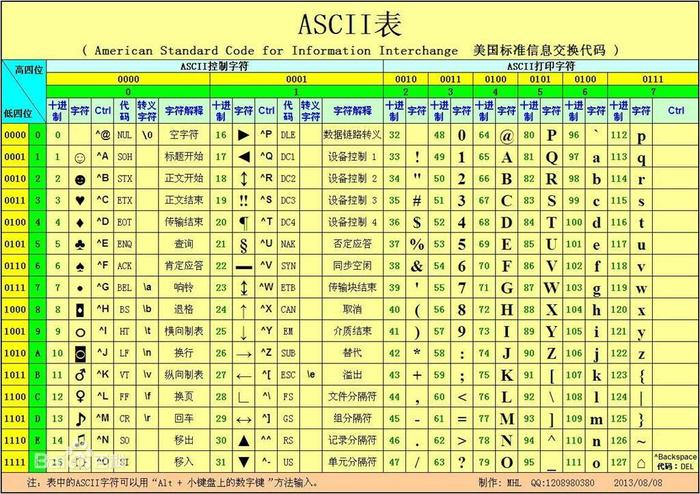
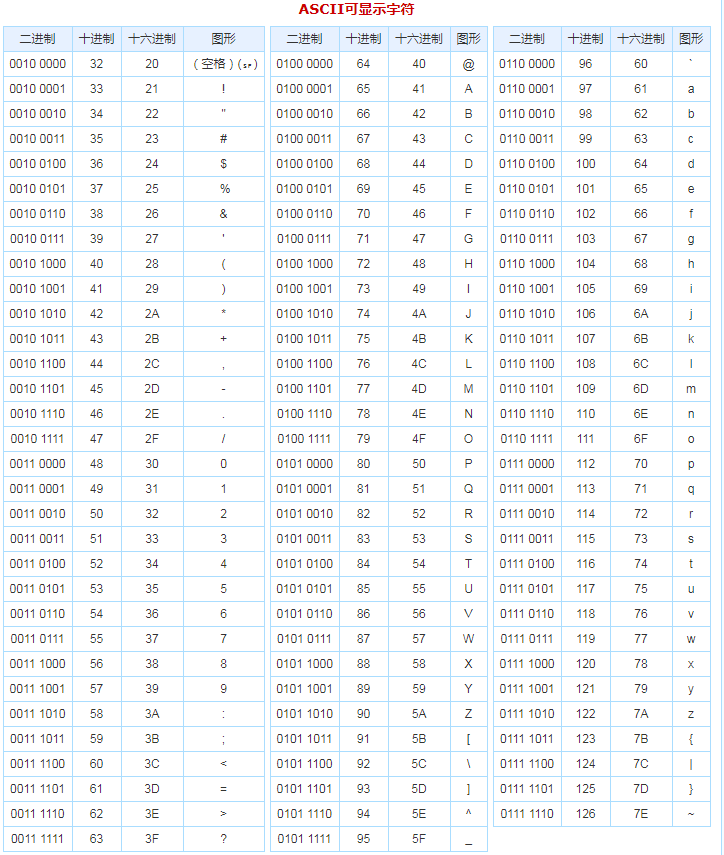
了解ascii编码
计算机由美国人发明,最早的字符编码为ASCII,只规定了英文字母数字和一些特殊字符与数字的对应关系。最多只能用 8 位来表示(一个字节),即:2**8 = 256,
所以,ASCII码最多只能表示 256 个符号
一个有意思的乱码:
1.windows下记事本写中文,保存txt(编码)(默认gbk).
2,将txt放到linux下查看(解码)(默认utf-8),出现乱码


1.windows下notepad++写中文,保存txt(编码)(使用utf8).
2,将txt放到linux下查看(解码)(默认utf-8),不会出现乱码
而我在win下nodepad++存储
文件转移到linux下,则不会乱码.

字符串编码成二进制
计算机里除了字符串,还有图片视频&声音, 先搞清楚字符串编码
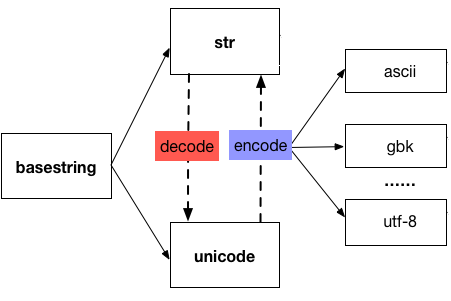
str -- encode --> bytes
str <-- decode <-- bytes
将字符串转换为二进制打印:
思路: 字符串变成二进制,需要编码,即encode -- 字符串的encode有两种方法
1,bytes()
2,str.encode()
- 方法1: bytes()函数
name_b = bytes(name,encoding="utf-8")
print(type(name)) # <class 'str'>
print(type(name_b)) # <class 'bytes'>
- 方法2: 字符串.encode('utf-8')
In [8]: name.encode('utf-8')
Out[8]: b'maotai'
python的open函数
思路:
open的参数:
f = open("test.txt",'rt',encoding="utf-8")
1,open默认以rt模式打开(点开open可看源码有些)
r 读
t text模式(文本文件模式)(还有binary模式,如图生音乐.)
2,编码
open()如果无encoding参数,则使用系统编码,如过指定,则使用指定的
win: (cp936)gbk
linux: utf-8
3,open打开和notepad打开文件本质相同
都是从硬盘--->展现(decode二进制过程)
4,f.write以gb2312的编码写到文件里
f = open("test.txt", 'r+', encoding='gb2312')
f.write("maotai")
encoding参数真正含义: 以...解码读, 以...编码存.
open方法mode带b时,不能指定encoding参数,否则报错
rb模式读二进制,并且打印,打印时需要decode
wb模式写二进制,写的时候需将字符串转为二进制后写
1,bytes()函数
2,str.encode('')
f = open("test.txt",'rb')
print(f.read().decode("utf-8"))
f = open("test.txt",'wb')
f.write(bytes('test2
',encoding="utf-8"))
f.write('test3
'.encode("utf-8"))
f = open("test.txt",'ab') #在文件末尾追加内容(不换行)
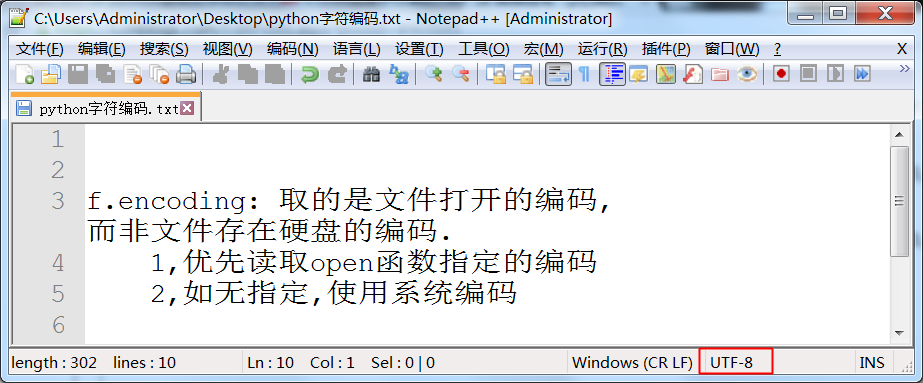
f.encoding: 取的是文件打开的编码, 而非文件存在硬盘的编码.
1,优先读取open函数指定的编码
2,如无指定,使用系统编码
f = open("test.txt")
print(f.encoding) # cp936(code page936页),即gbk
f = open("test.txt",encoding='utf-8')
print(f.encoding) # utf-8
先搞清楚notepad++读文件原理:(以utf8解码后展示)
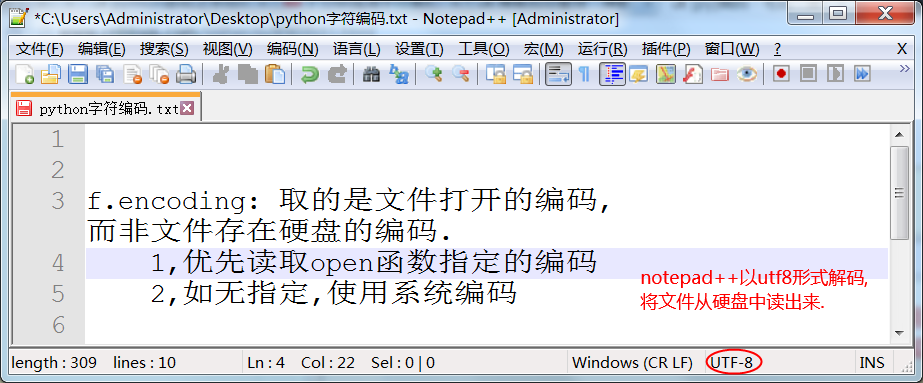
open()+r模式本质上和notepad++读文件原理一样.
思路: 以open指定的编码解码读取出来.
open()+w模式: 乱码问题:
思路: open用gbk写, pycharm以utf8方式读,则显示乱码


思路: open以utf8编码写, open以gbk读,则显示乱码

图片/视频&声音: 硬盘--屏幕展示
计算机的0和1是怎么变成我们屏幕上看到的图片、视频和声音的?
图片: 像素,如果是黑白图片
2bit: 4种颜色
位数越多,能展示的颜色越丰富
视频: 一张张的图片组成,原理和图片一样
声音: 采样--量化,然后模拟各种高低电平
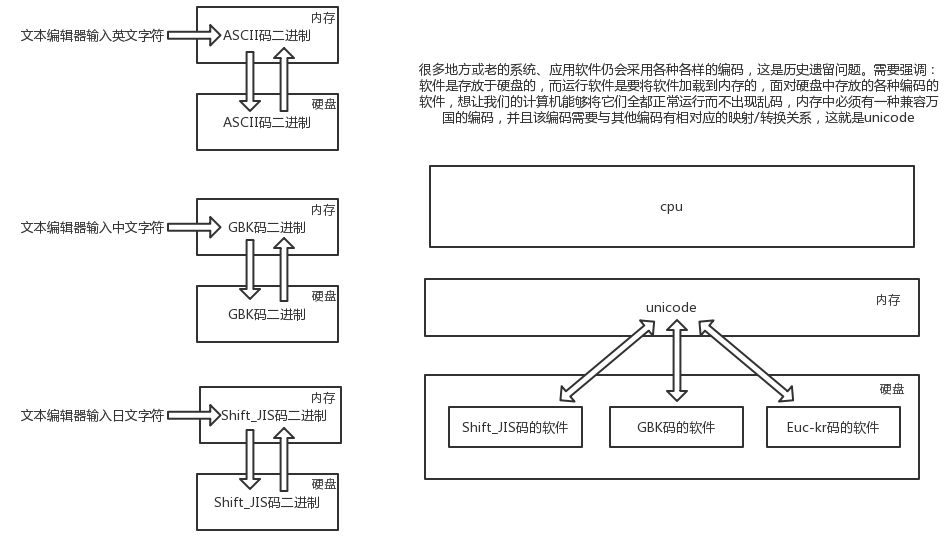
python中字符编码处理
ascii适用于英语国家---中国/日本文字众多,发明自己的编码(存盘)---为统一,发明unicode编码---为优化空间发明utf-8
- unicode编码存在的意义:
1,解决历史编码不统一问题
1,内存中编码都统一成了unicode,硬盘上还是你们自己国家的
2,如果已解决这个问题,内存和硬盘上都用utf-8也是ok的.
编码|占用空间(字节)
ascii|1
unicode|英汉:2
utf-8|英1,汉3
注: python一般硬盘中使用utf8,内存中的编码固定使用unicode
- python执行代码步骤
1,解释器打开py文件
以什么编码打开?
如果py文件不指定:
py2: ascii解码加载到内存
py3: utf-8解码加载到内存
如果py文件头指定,以指定的头解码加载到内存
#coding=utf8
代码加载到内存统一转换unicode编码存储,这里可以将unicode理解为二进制01010.
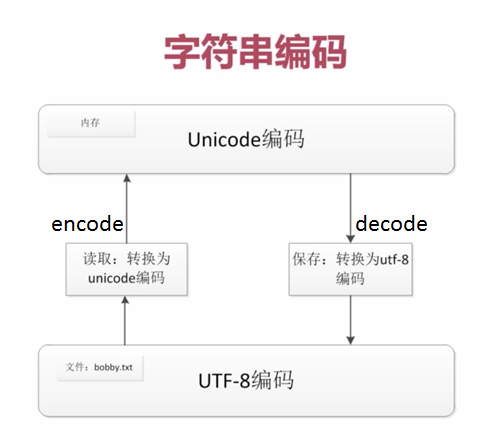
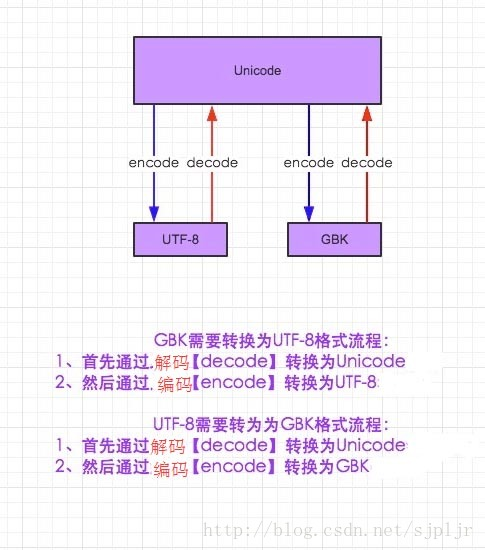
2,执行代码
py2执行
定义字符串
1,字符串先看头部,以头部编码存
2,如果指定了u,以unicode编码存储
x = u'毛台'
py3执行:
定义字符串
1,默认以u,unicode方式编码存储
2,encode成gbk
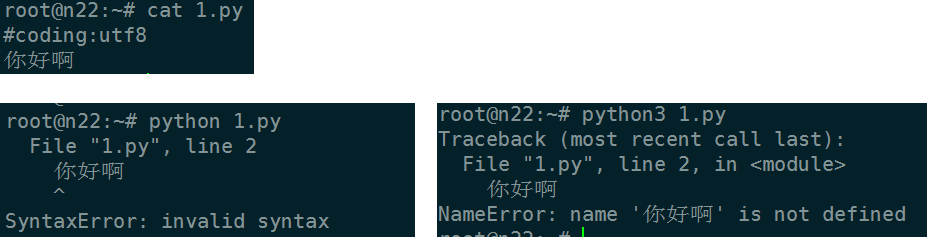
类型是byte
思路: 写个py文件,py2执行报asscii无法解码加载, py3报语法错误. 说明py2第一关加载都没过, py3过了第一关,(因为py3默认以utf8加载,恰好linux默认文件编码utf8),py3第二步扫描语法错误时候报错.

思路: 写py,指定编码为utf8.py2 py3都语法错误. 说明py2 3都已经过了加载第一关, 到了第二关扫描语法错误.