难怪我没学会, 因为我的套路有问题. 错误点, 1,大而全 2,不注重思路
学习要领:
1, 小而精
2, 重思路(总结)
nodejs特点:
1.node提供了js的运行环境, 一般将node运行在服务端, 丰富了各种模块,jsplus
2.大量的工具库
3.事件驱动&异步IO,谷歌v8引擎
全局js对象是windows,而node环境下全局js对象是global
express 基于nodejs的web框架: Fast, unopinionated, minimalist web framework for Node.js
node命令参数
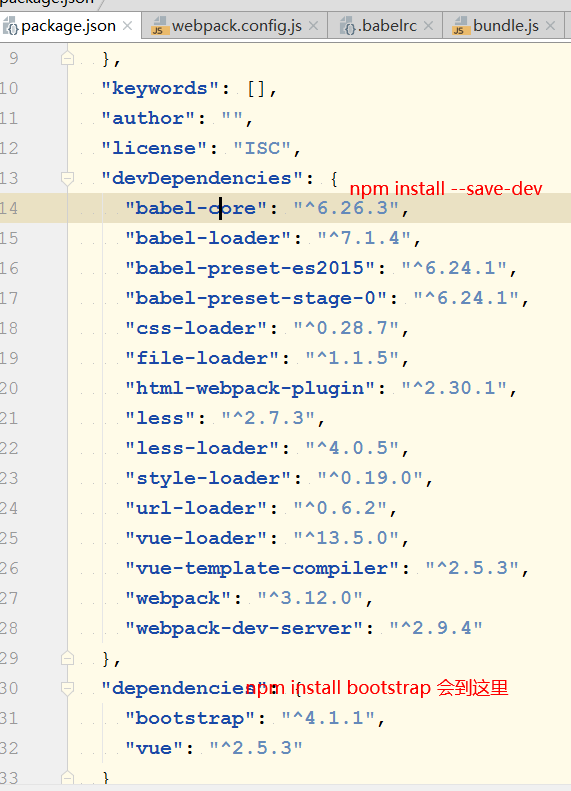
npm install module-name -save 自动把模块和版本号添加到dependencies部分,新版本的node可以省略这个参数
npm install module-name -save-dve 自动把模块和版本号添加到devdependencies部分
-S, --save: Package will appear in your dependencies.新版本node的可以省略
-D, --save-dev: Package will appear in your devDependencies.
-O, --save-optional: Package will appear in your optionalDependencies.
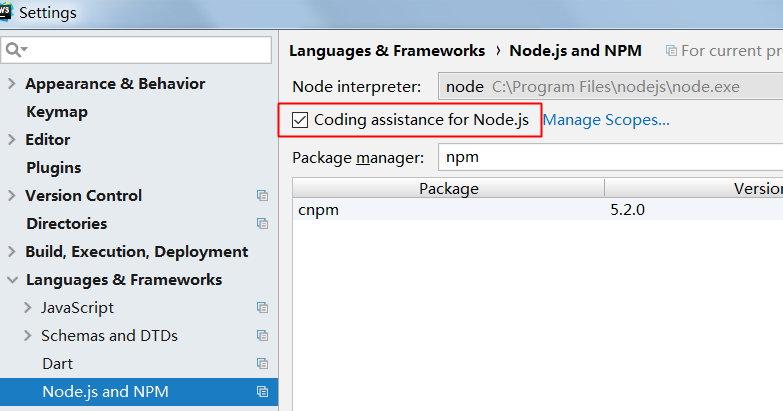
还有一个设置代理, 公司里会用到(因为有网络限制)
下载长期支持版
https://nodejs.org/en/
npm install -g cnpm --registry=https://registry.npm.taobao.org
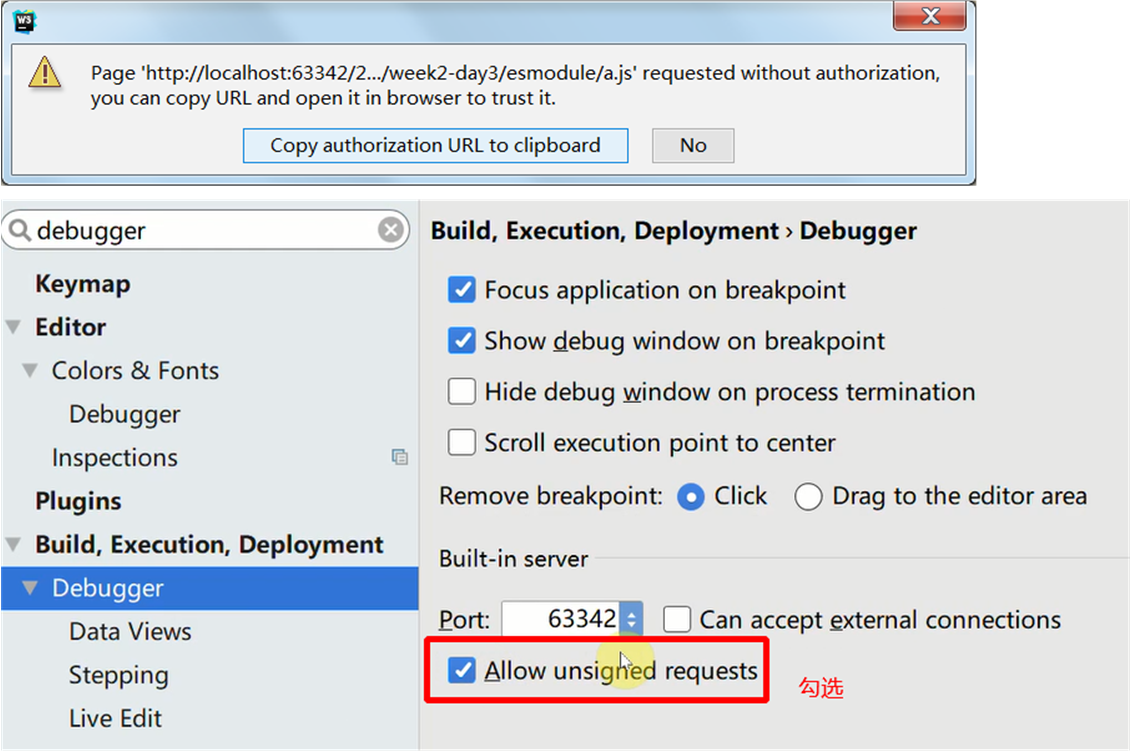
创建文件模板:
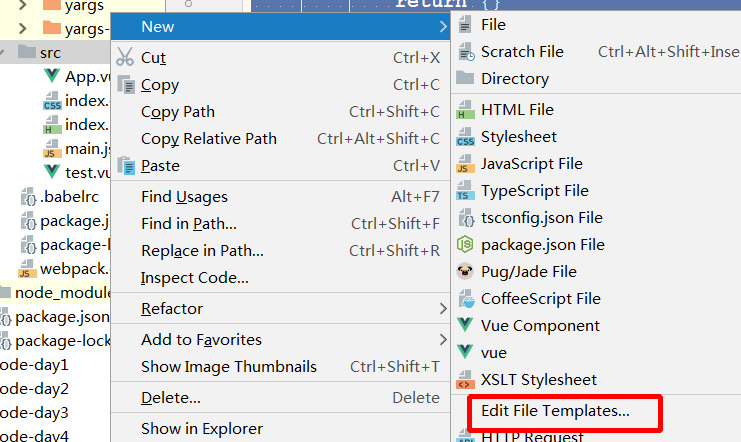
<template>
<div></div>
</template>
<script>
export default {
data() {
return {}
},
methods: {},
computed: {},
componets: {}
}
</script>
<style scoped>
</style>
cd s1
npm init -y # 默认是ISC协议, 一般是MIT协议,自由可更改,永久免费
npm install vue axios bootstrap
- repl环境: 即交互环境
read-eval-print loop '读取--求值--输出' 循环

思路:
1.创建服务器,访问
2,区分path和query
3,返回指定html, fs模块
4,返回任意html
5.根据后缀设置content-type
// 思路: 接收请求 -- 获取后缀 -- 设置content-type -- 响应
url里的path和query的区别
url里的path和query-http和url模块

var http = require("http"),
url = require("url"),
fs = require("fs");
s1 = http.createServer(function (req, res) {
// res.write("<h1>hello yifei</h1>");
// res.end();
var urlObj = url.parse(req.url, true),
pathname = urlObj['pathname'], //path
query = urlObj['query']; //?后面的参数 {}类型
console.log(pathname);
console.log(query);
res.end();//终结请求
});
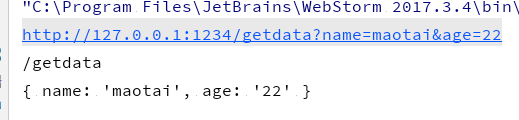
s1.listen(1234, function () {
console.log("http://127.0.0.1:1234/getdata/?name=maotai&age=22");
});
结果
fs模块: 返回网页
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>test</title>
<link rel="stylesheet" href="css/base.css">
</head>
<body>
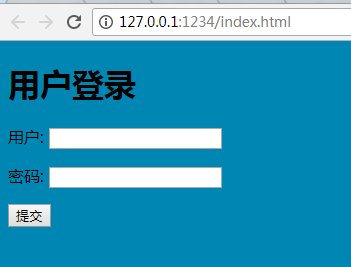
<h1>用户登录</h1>
<form action="/add.html" method="get">
<p>用户: <input type="text" name="username"></p>
<p>密码: <input type="text" name="password"></p>
<p><input type="submit"></p>
</form>
</body>
</html>
css/base.css
body{
background-color: #0086b3;
}
node代码
var http = require('http'),
url = require('url'),
fs = require('fs');
s1 = http.createServer(function (req, res) {
var urlObj = url.parse(req.url, true),
pathname = urlObj['pathname'],
query = urlObj['query'];
console.log(pathname, query);
if (pathname === "/index.html") {
var con = fs.readFileSync("./index.html"); //读取html,返回
res.end(con);
return;
}
if (pathname === "/css/base.css") { //index.html里会调用css
con = fs.readFileSync("./css/base.css","utf-8");
res.end(con);
return;
}
});
s1.listen("1234", function () {
console.log("http://127.0.0.1:1234/index.html");
});
根据pathname返回不通的url
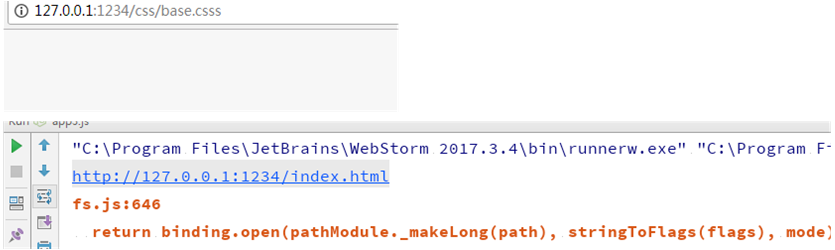
最简陋的实现(如果html不存在会报错)
var http = require("http"),
url = require("url"),
fs = require("fs");
s1 = http.createServer(function (req, res) {
var urlObj = url.parse(req.url),
pathname = urlObj['pathname'],
query = urlObj['query'];
pathname = "." + pathname;
var con = fs.readFileSync(pathname); //根据pathname返回不同的url
res.end(con);
return; //代表终结
});
s1.listen(1234, function () {
console.log("http://127.0.0.1:1234/index.html")
});
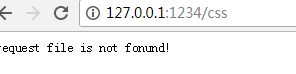
处理错误
var http = require("http"),
url = require("url"),
fs = require("fs");
s1 = http.createServer(function (req, res) {
var urlObj = url.parse(req.url),
pathname = urlObj['pathname'],
query = urlObj['query'];
try {
var con = fs.readFileSync('.'+pathname);
res.end(con);
} catch (e) {
res.end("request file is not fonund!")
}
return;
});
s1.listen(1234, function () {
console.log("http://127.0.0.1:1234/index.html")
});
处理mime
每一种资源文件都有自己的标识类型. 浏览器按照提供的MIME(content-type)类型渲染页面
即不通类型不同的显示,如html css
谷歌浏览器会智能处理一些类型.
// 思路: 接收请求 -- 获取后缀 -- 设置content-type -- 响应
var http = require('http'),
url = require('url'),
fs = require('fs');
s1 = http.createServer(function (req, res) {
var urlObj = url.parse(req.url),
pathname = urlObj['pathname'],
query = urlObj['query'];
var reg = /.(HTML|CSS|JS|JSON|TXT|ICO)/i;
var suffixMIME = 'text/plain';
if (reg.test(pathname)) {
var suffix = reg.exec(pathname)[1].toUpperCase();
switch (suffix) {
case "HTML":
suffixMIME = 'text/html';
break;
case "JS":
suffixMIME = 'text/javascript';
break;
case "CSS":
suffixMIME = 'text/css';
break;
case "JSON":
suffixMIME = 'application/json';
break;
case "ICO":
suffixMIME = 'application/octet-stream';
break;
}
}
try {
con = fs.readFileSync('.' + pathname);
res.writeHead(200, {'content-type': suffixMIME + ';charset=utf-8'});
res.end(con);
} catch (e) {
res.writeHead(404, {'content-type': 'text/plain;charset=utf-8'});
res.end("file not found")
}
});
s1.listen(1234, function () {
console.log("http://127.0.0.1:1234/index.html");
});