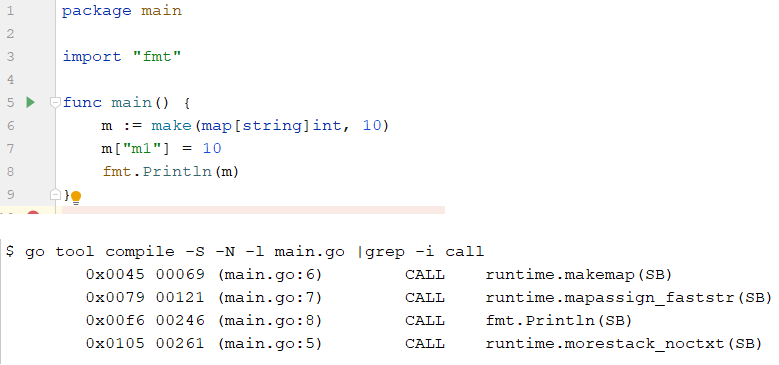
map数据结构概述
map 的设计也被称为 “The dictionary problem”,
它的任务是设计一种数据结构用来维护一个集合的数据,
并且可以同时对集合进行增删查改的操作。
map最主要的数据结构有两种:
哈希查找表(Hash table)
查找表用一个哈希函数将 key 分配到不同的桶(bucket,也就是数组的不同 index)
开销主要在哈希函数的计算以及数组的常数访问时间。在很多场景下,哈希查找表的性能很高。
哈希查找表最差是 O(N), 平均查找效率是 O(1)
遍历哈希查找表则是乱序的
解决冲突的办法: 链表法和开放地址法
搜索树(Search tree)
一般采用自平衡搜索树,包括:AVL 树,红黑树(c++)。
自平衡搜索树法的最差搜索效率是 O(logN)
遍历自平衡搜索树,返回的 key 序列,一般会按照从小到大的顺序
注: Go 语言采用的是哈希查找表,并且使用链表解决哈希冲突。
hash函数
hash函数,有加密型和非加密型。
加密型的一般用于加密数据、数字摘要等,典型代表就是md5、sha1、sha256、aes256这种;
非加密型的一般就是查找。在map的应用场景中,用的是查找。选择hash函数主要考察的是两点:性能、碰撞概率。
golang使用的hash算法根据硬件选择,如果cpu支持aes,那么使用aes hash,否则使用memhash,
map的实现细节
//初始化: 最重要的肯定就是确定一开始要有多少个桶,初始化哈希种子等等
func makemap_small() *hmap {
h := new(hmap)
h.hash0 = fastrand()
return h
}
// makemap implements Go map creation for make(map[k]v, hint).
func makemap(t *maptype, hint int, h *hmap) *hmap {
.....
// initialize Hmap
if h == nil {
h = (*hmap)(newobject(t.hmap))
}
h.hash0 = fastrand()
// find size parameter which will hold the requested # of elements
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
......
return h
}
-
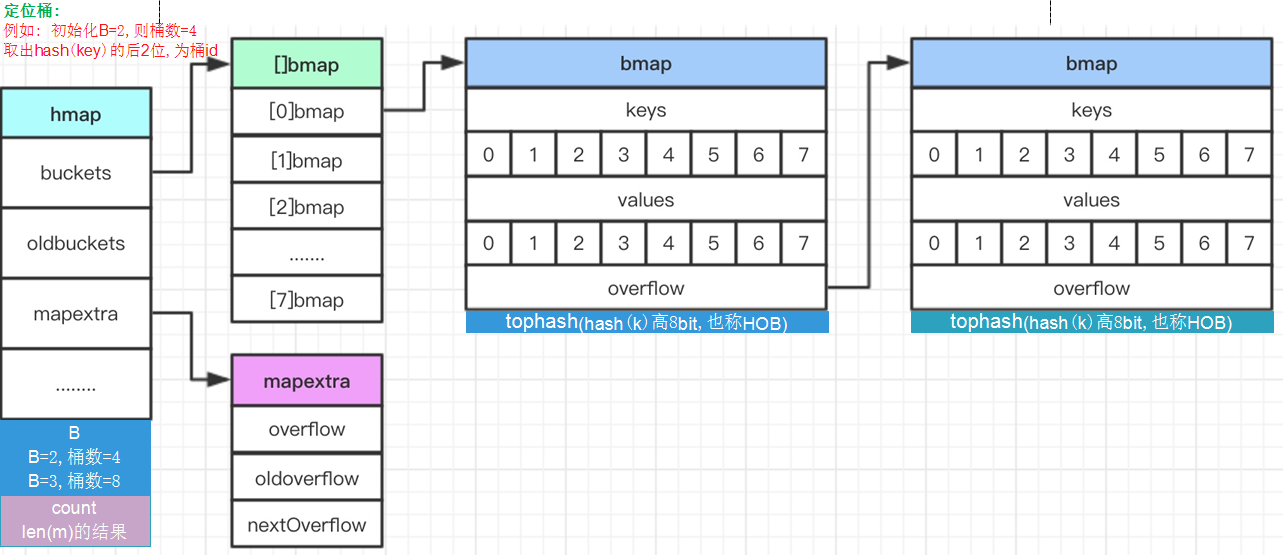
存储逻辑结构
-
map数据结构
// A header for a Go map.
type hmap struct {
count int // len()返回的map的大小 即有多少kv对
flags uint8
B uint8 // 表示hash table总共有2^B个buckets
hash0 uint32 // hash seed
buckets unsafe.Pointer // 按照low hash值可查找的连续分配的数组,初始时为16个Buckets. 当bucket(桶为0时)为nil
oldbuckets unsafe.Pointer
nevacuate uintptr
overflow *[2]*[]*bmap //溢出链 当初始buckets都满了之后会使用overflow
}
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
keys [8]keytype // 第二个是8个key、8个value
values [8]valuetype
pad uintptr
overflow uintptr // 第三个是溢出时,下一个溢出桶的地址
}
// 注意: key、value、overflow字段都不显示定义,而是通过maptype计算偏移获取的。
注:
之所以把所有k1k2放一起而不是k1v1是因为key和value的数据类型内存大小可能差距很大,
比如map[int64]int8,考虑到字节对齐,kv存在一起会浪费很多空间。
GET
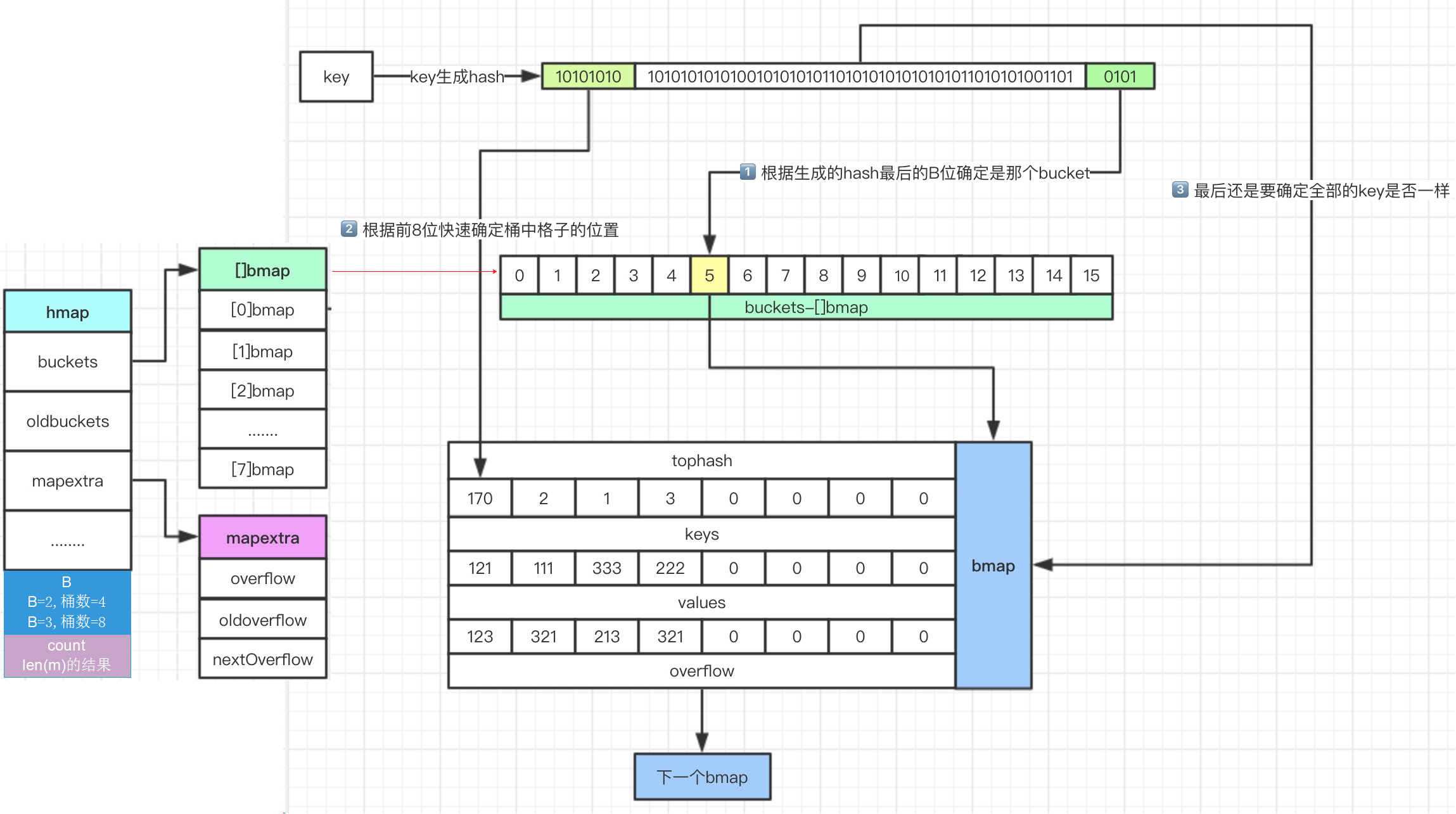
1. 计算出key的hash
2. 用最后的“B”位来确定在哪个桶(“B”就是前面说的那个,B为4,就有16个桶,0101用十进制表示为5,所以在5号桶)
3. 根据key的前8位快速确定是在哪个格子(额外说明一下,在bmap中存放了每个key对应的tophash,是key的前8位)
4. 最终还是需要比对key完整的hash是否匹配,如果匹配则获取对应value
5. 如果都没有找到,就去下一个overflow找


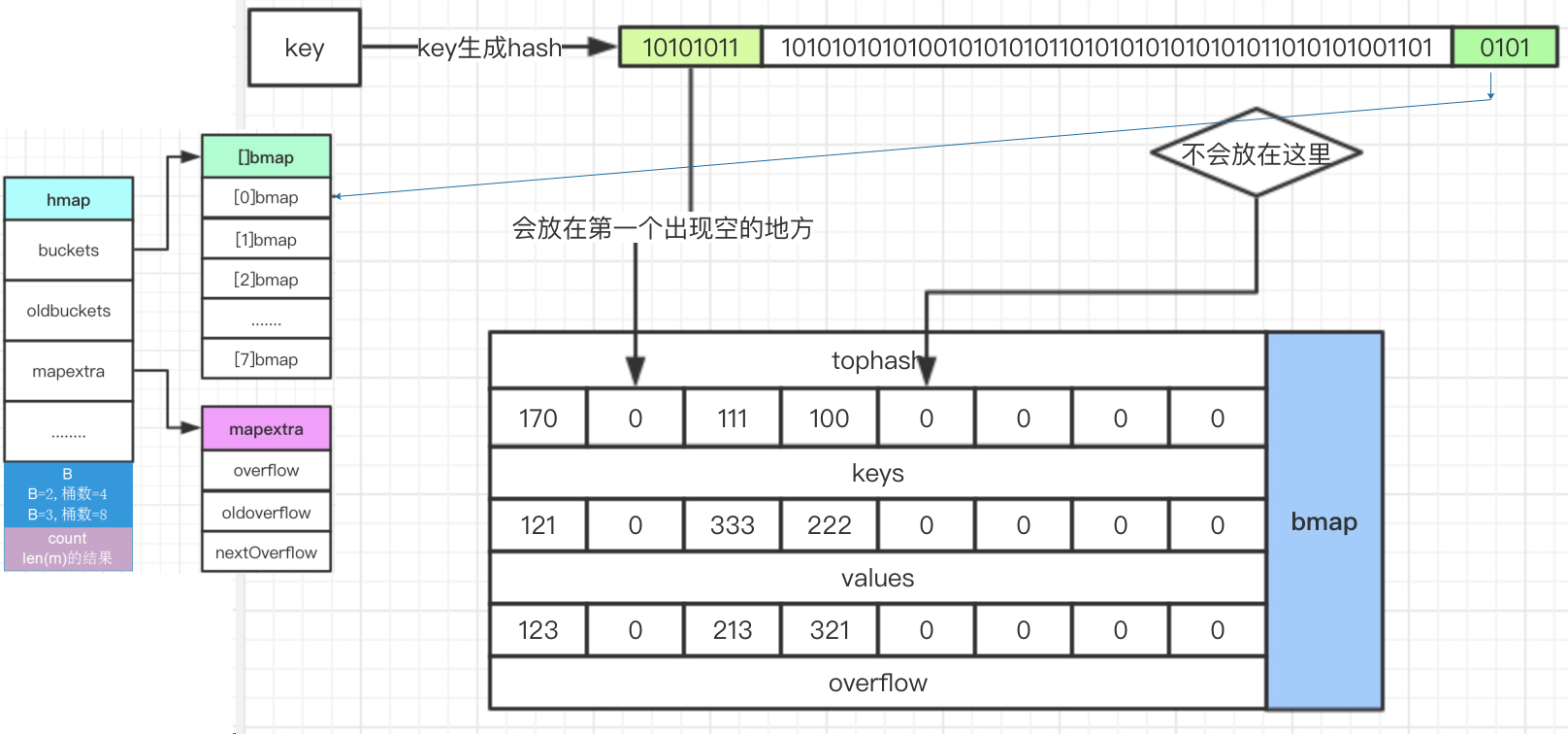
PUT
go/src/runtime/hashmap.go的mapassign函数
1. 通过key的后“B”位确定是哪一个桶
2. 通过key的前8位快速确定是否已经存在
3. 最终确定存放位置,如果8个格子已经满了,没地方放了,那么就重新创建一个bmap作为溢出桶连接在overflow
扩容
装载因子
如果你看过Java的HashMap实现,就知道有个装载因子,同样的在golang中也有,但是不一样哦。装载因子的定义是这个样子:
loadFactor := count / (2^B)
其中count为map中元素的个数,B就是之前个那个“B”
翻译一下就是装载因子 = (map中元素的个数)/(map当前桶的个数)
扩容条件1
装载因子 > 6.5(这个值是源码中写的)
其实意思就是,桶只有那么几个,但是元素很多,证明有很多溢出桶的存在(可以想成链表拉的太长了),那么扫描速度会很慢,就要扩容。
扩容条件2
overflow 的 bucket 数量过多:当 B 小于 15,如果 overflow 的 bucket 数量超过 2^B ;当 B >= 15,如果 overflow 的 bucket 数量超过 2^15 。
其实意思就是,可能有一个单独的一条链拉的很长,溢出桶太多了,说白了就是,加入的key不巧,后B位都一样,一直落在同一个桶里面,这个桶一直放,虽然装载因子不高,但是扫描速度就很慢。
扩容条件3
当前不能正在扩容
map小结
是否线程安全?否,而且并发操作会抛出异常。
源码位置:src/runtime/hashmap.go
每次遍历map顺序是否一致?不一致,每次遍历会随机个数,通过随机数来决定从哪个元素开始。