Some concepts as blow:
- Welcome to Akka, a set of open-source libraries for designing scalable, resilient systems that span processor cores and networks. Akka allows you to focus on meeting business needs instead of writing low-level code to provide reliable behavior, fault tolerance, and high performance.
- Many common practices and accepted programming models do not address important challenges inherent in designing systems for modern computer architectures.
- To be successful, distributed systems must cope in an environment where components crash without responding, messages get lost without a trace on the wire, and network latency fluctuates.
- Multi-threaded behavior without the use of low-level concurrency constructs like atomics or locks — relieving you from even thinking about memory visibility issues.
- Transparent remote communication between systems and their components — relieving you from writing and maintaining difficult networking code.
- A clustered, high-availability architecture that is elastic, scales in or out, on demand — enabling you to deliver a truly reactive system
- Akka’s use of the actor model provides a level of abstraction that makes it easier to write correct concurrent, parallel and distributed systems.
- By learning Akka and how to use the actor model, you will gain access to a vast and deep set of tools that solve difficult distributed/parallel systems problems in a uniform programming model where everything fits together tightly and efficiently.
- Provides a way to handle parallel processing in a high performance network — an environment that was not available at the time.
- Objects can only guarantee encapsulation (protection of invariants) in the face of single-threaded access, multi-thread execution almost always leads to corrupted internal state. Every invariant can be violated by having two contending threads in the same code segment.
- While locks seem to be the natural remedy to uphold encapsulation with multiple threads, in practice they are inefficient and easily lead to deadlocks in any application of real-world scale.
- Locks work locally, attempts to make them distributed exist, but offer limited potential for scaling out.
- Additionally, locks only really work well locally. When it comes to coordinating across multiple machines, the only alternative is distributed locks. Unfortunately, distributed locks are several magnitudes less efficient than local locks and usually impose a hard limit on scaling out. Distributed lock protocols require several communication round-trips over the network across multiple machines, so latency goes through the roof.
- The illusion of shared memory on modern computer architectures.
- There is no real shared memory anymore, CPU cores pass chunks of data (cache lines) explicitly to each other just as computers on a network do. Inter-CPU communication and network communication have more in common than many realize. Passing messages is the norm now be it across CPUs or networked computers.
- Instead of hiding the message passing aspect through variables marked as shared or using atomic data structures, a more disciplined and principled approach is to keep state local to a concurrent entity and propagate data or events between concurrent entities explicitly via messages.
- This is surprisingly similar to how networked systems work where messages/requests can get lost/fail without any notification.
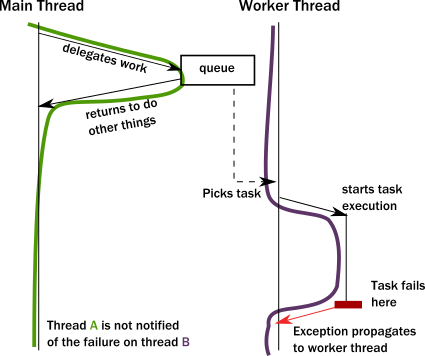
- To achieve any meaningful concurrency and performance on current systems, threads must delegate tasks among each other in an efficient way without blocking. With this style of task-delegating concurrency (and even more so with networked/distributed computing) call stack-based error handling breaks down and new, explicit error signaling mechanisms need to be introduced. Failures become part of the domain model.
- Concurrent systems with work delegation needs to handle service faults and have principled means to recover from them. Clients of such services need to be aware that tasks/messages might get lost during restarts. Even if loss does not happen, a response might be delayed arbitrarily due to previously enqueued tasks (a long queue), delays caused by garbage collection, etc. In face of these, concurrent systems should handle response deadlines in the form of timeouts, just like networked/distributed systems.
- Instead of calling methods, actors send messages to each other. Sending a message does not transfer the thread of execution from the sender to the destination. An actor can send a message and continue without blocking. Therefore, it can accomplish more in the same amount of time.

- An important difference between passing messages and calling methods is that messages have no return value.
- By sending a message, an actor delegates work to another actor. As we saw in The illusion of a call stack, if it expected a return value, the sending actor would either need to block or to execute the other actor’s work on the same thread. Instead, the receiving actor delivers the results in a reply message.
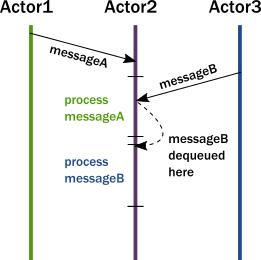
- In summary, this is what happens when an actor receives a message:
- The actor adds the message to the end of a queue.
- If the actor was not scheduled for execution, it is marked as ready to execute.
- A (hidden) scheduler entity takes the actor and starts executing it.
- Actor picks the message from the front of the queue.
- Actor modifies internal state, sends messages to other actors.
- The actor is unscheduled.
- To accomplish this behavior, actors have:
- A mailbox (the queue where messages end up).
- A behavior (the state of the actor, internal variables etc.).
- Messages (pieces of data representing a signal, similar to method calls and their parameters).
- An execution environment (the machinery that takes actors that have messages to react to and invokes their message handling code).
- An address (more on this later).
- This is a very simple model and it solves the issues enumerated previously. Main concepts are same as basis of distributed system or MQ. Task/Message/Jobs/RPC encapsulation of method calling with interface name,method name,method parameter type, method arguments.
- Encapsulation is preserved by decoupling execution from signaling (method calls transfer execution, message passing does not).
- There is no need for locks. Modifying the internal state of an actor is only possible via messages, which are processed one at a time eliminating races when trying to keep invariants.
- There are no locks used anywhere, and senders are not blocked. Millions of actors can be efficiently scheduled on a dozen of threads reaching the full potential of modern CPUs. Task delegation is the natural mode of operation for actors.
- State of actors is local and not shared, changes and data is propagated via messages, which maps to how modern memory hierarchy actually works. In many cases, this means transferring over only the cache lines that contain the data in the message while keeping local state and data cached at the original core. The same model maps exactly to remote communication where the state is kept in the RAM of machines and changes/data is propagated over the network as packets.
- Actors handle error situations gracefully.Since we no longer have a shared call stack between actors that send messages to each other, we need to handle error situations differently. There are two kinds of errors we need to consider.
- The first case is when the delegated task on the target actor failed due to an error in the task (typically some validation issue, like a non-existent user ID). In this case, the service encapsulated by the target actor is intact, it is only the task that itself is erroneous. The service actor should reply to the sender with a message, presenting the error case. There is nothing special here, errors are part of the domain and hence become ordinary messages.
- The second case is when a service itself encounters an internal fault. Akka enforces that all actors are organized into a tree-like hierarchy, i.e. an actor that creates another actor becomes the parent of that new actor. This is very similar how operating systems organize processes into a tree. Just like with processes, when an actor fails, its parent actor is notified and it can react to the failure. Also, if the parent actor is stopped, all of its children are recursively stopped, too. This service is called supervision and it is central to Akka.
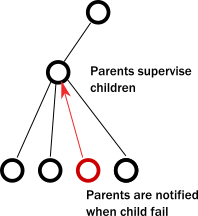
- There is always a responsible entity for managing an actor: its parent. Restarts are not visible from the outside: collaborating actors can keep continuing sending messages while the target actor restarts.
- Before delving into some best practices for writing actors, it will be helpful to preview the most commonly used Akka libraries. This will help you start thinking about the functionality you want to use in your system.
-
<dependency> <groupId>com.typesafe.akka</groupId> <artifactId>akka-actor_2.12</artifactId> <version>2.5.17</version> </dependency>The core Akka library is
akka-actor, but actors are used across Akka libraries, providing a consistent, integrated model that relieves you from individually solving the challenges that arise in concurrent or distributed system design. From a birds-eye view, actors are a programming paradigm that takes encapsulation, one of the pillars of OOP, to its extreme. Unlike objects, actors encapsulate not only their state but their execution. Communication with actors is not via method calls but by passing messages. - While this difference may seem minor, it is actually what allows us to break clean from the limitations of OOP when it comes to concurrency and remote communication.
- For now, the important point is that this is a model that handles concurrency and distribution at the fundamental level instead of ad hoc patched attempts to bring these features to OOP.
- Challenges that actors solve include the following:
- How to build and design high-performance, concurrent applications.
- How to handle errors in a multi-threaded environment.
- How to protect my project from the pitfalls of concurrency.
-
<dependency> <groupId>com.typesafe.akka</groupId> <artifactId>akka-remote_2.12</artifactId> <version>2.5.17</version> </dependency>Remoting enables actors that live on different computers, to seamlessly exchange messages. While distributed as a JAR artifact, Remoting resembles a module more than it does a library.
- Thanks to the actor model, a remote and local message send looks exactly the same. The patterns that you use on local systems translate directly to remote systems. You will rarely need to use Remoting directly, but it provides the foundation on which the Cluster subsystem is built.
- Challenges Remoting solves include the following:
- How to address actor systems living on remote hosts.
- How to address individual actors on remote actor systems.
- How to turn messages to bytes on the wire.
- How to manage low-level, network connections (and reconnections) between hosts, detect crashed actor systems and hosts, all transparently.
- How to multiplex communications from an unrelated set of actors on the same network connection, all transparently.