
1. Create environment for stream computing
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.getConfig().disableSysoutLogging(); env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000)); env.enableCheckpointing(5000); // create a checkpoint every 5 seconds env.getConfig().setGlobalJobParameters(parameterTool); // make parameters available in the web interface env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
public static StreamExecutionEnvironment getExecutionEnvironment() { if (contextEnvironmentFactory != null) { return contextEnvironmentFactory.createExecutionEnvironment(); } // because the streaming project depends on "flink-clients" (and not the other way around) // we currently need to intercept the data set environment and create a dependent stream env. // this should be fixed once we rework the project dependencies ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); if (env instanceof ContextEnvironment) { return new StreamContextEnvironment((ContextEnvironment) env); } else if (env instanceof OptimizerPlanEnvironment || env instanceof PreviewPlanEnvironment) { return new StreamPlanEnvironment(env); } else { return createLocalEnvironment(); } }
2. Now we need to add the data source for further computing
DataStream<KafkaEvent> input = env .addSource( new FlinkKafkaConsumer010<>( parameterTool.getRequired("input-topic"), new KafkaEventSchema(), parameterTool.getProperties()).assignTimestampsAndWatermarks(new CustomWatermarkExtractor())) .keyBy("word") .map(new RollingAdditionMapper());
public <OUT> DataStreamSource<OUT> addSource(SourceFunction<OUT> function) { return addSource(function, "Custom Source"); }
@SuppressWarnings("unchecked")
public <OUT> DataStreamSource<OUT> addSource(SourceFunction<OUT> function, String sourceName, TypeInformation<OUT> typeInfo) {
if (typeInfo == null) {
if (function instanceof ResultTypeQueryable) {
typeInfo = ((ResultTypeQueryable<OUT>) function).getProducedType();
} else {
try {
typeInfo = TypeExtractor.createTypeInfo(
SourceFunction.class,
function.getClass(), 0, null, null);
} catch (final InvalidTypesException e) {
typeInfo = (TypeInformation<OUT>) new MissingTypeInfo(sourceName, e);
}
}
}
boolean isParallel = function instanceof ParallelSourceFunction;
clean(function);
StreamSource<OUT, ?> sourceOperator;
if (function instanceof StoppableFunction) {
sourceOperator = new StoppableStreamSource<>(cast2StoppableSourceFunction(function));
} else {
sourceOperator = new StreamSource<>(function);
}
return new DataStreamSource<>(this, typeInfo, sourceOperator, isParallel, sourceName);
}
public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper) { TypeInformation<R> outType = TypeExtractor.getMapReturnTypes(clean(mapper), getType(), Utils.getCallLocationName(), true); return transform("Map", outType, new StreamMap<>(clean(mapper))); }
public <R> SingleOutputStreamOperator<R> transform(String operatorName, TypeInformation<R> outTypeInfo, OneInputStreamOperator<T, R> operator) { // read the output type of the input Transform to coax out errors about MissingTypeInfo transformation.getOutputType(); OneInputTransformation<T, R> resultTransform = new OneInputTransformation<>( this.transformation, operatorName, operator, outTypeInfo, environment.getParallelism()); @SuppressWarnings({ "unchecked", "rawtypes" }) SingleOutputStreamOperator<R> returnStream = new SingleOutputStreamOperator(environment, resultTransform); getExecutionEnvironment().addOperator(resultTransform); return returnStream; }
@Internal public void addOperator(StreamTransformation<?> transformation) { Preconditions.checkNotNull(transformation, "transformation must not be null."); this.transformations.add(transformation); }
protected final List<StreamTransformation<?>> transformations = new ArrayList<>();
public KeyedStream<T, Tuple> keyBy(String... fields) { return keyBy(new Keys.ExpressionKeys<>(fields, getType())); } private KeyedStream<T, Tuple> keyBy(Keys<T> keys) { return new KeyedStream<>(this, clean(KeySelectorUtil.getSelectorForKeys(keys, getType(), getExecutionConfig()))); }
3. The data from data source will be streamed into Flink Distributed Computing Runtime and the computed result will be transfered to data Sink.
input.addSink( new FlinkKafkaProducer010<>( parameterTool.getRequired("output-topic"), new KafkaEventSchema(), parameterTool.getProperties()));
public DataStreamSink<T> addSink(SinkFunction<T> sinkFunction) { // read the output type of the input Transform to coax out errors about MissingTypeInfo transformation.getOutputType(); // configure the type if needed if (sinkFunction instanceof InputTypeConfigurable) { ((InputTypeConfigurable) sinkFunction).setInputType(getType(), getExecutionConfig()); } StreamSink<T> sinkOperator = new StreamSink<>(clean(sinkFunction)); DataStreamSink<T> sink = new DataStreamSink<>(this, sinkOperator); getExecutionEnvironment().addOperator(sink.getTransformation()); return sink; }
@Internal public void addOperator(StreamTransformation<?> transformation) { Preconditions.checkNotNull(transformation, "transformation must not be null."); this.transformations.add(transformation); }
protected final List<StreamTransformation<?>> transformations = new ArrayList<>();
4. The last step is to start executing.
env.execute("Kafka 0.10 Example");
The mapper computing template is defined as blow.
private static class RollingAdditionMapper extends RichMapFunction<KafkaEvent, KafkaEvent> { private static final long serialVersionUID = 1180234853172462378L; private transient ValueState<Integer> currentTotalCount; @Override public KafkaEvent map(KafkaEvent event) throws Exception { Integer totalCount = currentTotalCount.value(); if (totalCount == null) { totalCount = 0; } totalCount += event.getFrequency(); currentTotalCount.update(totalCount); return new KafkaEvent(event.getWord(), totalCount, event.getTimestamp()); } @Override public void open(Configuration parameters) throws Exception { currentTotalCount = getRuntimeContext().getState(new ValueStateDescriptor<>("currentTotalCount", Integer.class)); } }
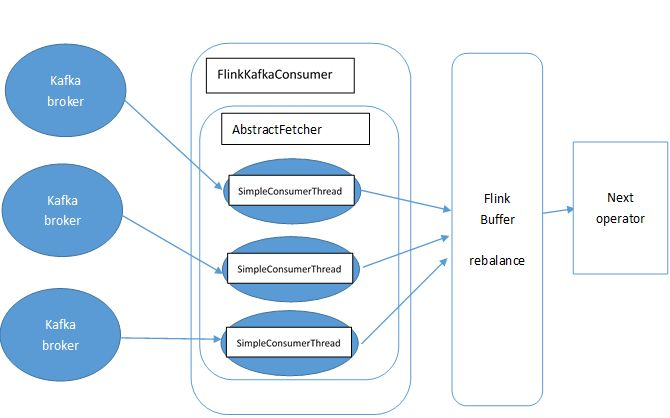
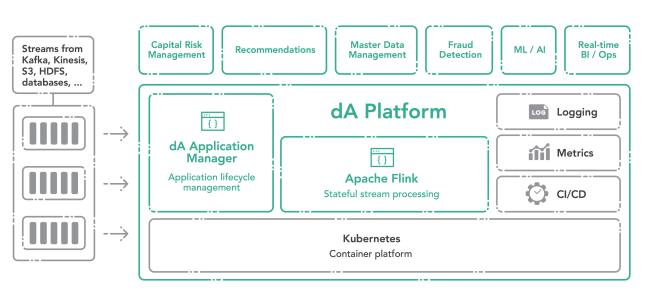
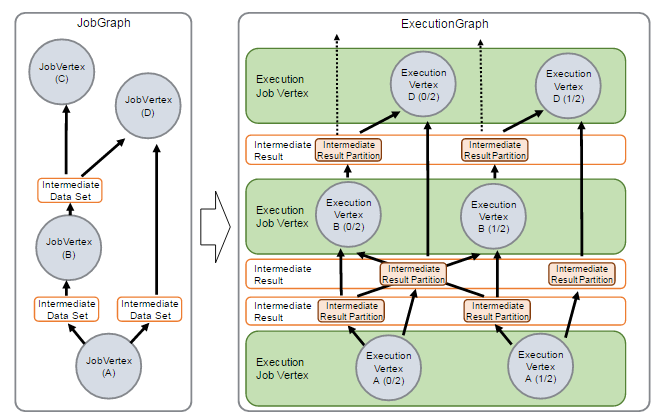
http://www.debugrun.com/a/LjK8Nni.html