原文链接 http://nerd-is.in/2013-09/scala-learning-collections/
所有集合都扩展自Iterable特质
集合有三大类,分别为序列,集和映射
对于几乎所有集合类,Scala都同时提供了可变的和不可变的版本
Scala列表要么是空的,要么拥有一头一尾,其中尾部本身又是一个列表
集是无先后次序的集合
用LinkedHashSet来保留插入顺序,或者用SortedSet来按顺序进行迭代
+将元素添加到无先后顺序的集合中;+: 和 :+ 向前或向后追加到序列;
++将两个集合串接在一起;-和--移除元素
Iterable和Seq特质有数十个用于常见操作的方法
在编写冗长繁琐的循环之前,先看看这些方法是否满足你的需要
映射 折叠 和拉链操作是很有用的技巧,用来将函数或操作应用到集合中的元素。
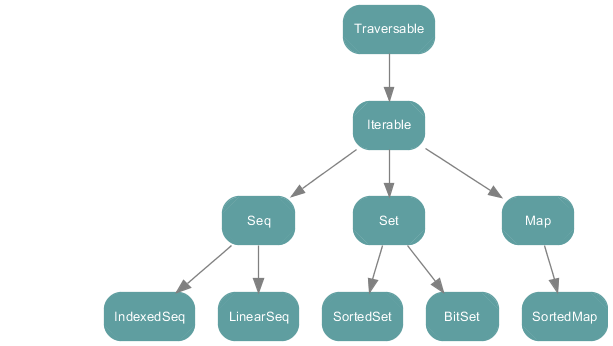
Seq是一个有先后次序的序列,比如数组或列表。IndexedSeq允许我们通过整型的
下标快速的访问任意元素。ArrayBuffer是带下标的,但是链表不是。
Set是一组无先后次序的值,SortedSet中,元素以某种排过序的顺序访问。
Map是一组KV对偶,SortedMap按照键的排序访问其中的实体。
可变和不可变集合
package test.scala.lang.set_
object TestSet {
def main(args: Array[String]): Unit = {
testDigits
}
def digits(n: Int): Set[Int] = {
if (n > 0) {
digits(-n)
} else if (n < 10) {
Set(n)
} else digits(n/10) + (n % 10)
}
//测试不可变集合
def testDigits = {
val r = digits(123)
val rr = r.+(9)
println(r == rr)
}
}
序列
Vector是ArrayBuffer的不可变版本,一个带下标的序列,支持快速的随机访问。
向量是以树形结构的形式实现的,每个节点可以有不超过32个子节点。
列表
def testList = {
val t = List(4, 3)
println(t.head)
println(t.tail)
val tt = t.tail
println(tt.head)
println(tt.tail)
val ttt = 1 :: List(2, 3)
println(ttt)
println(sum(ttt))
}
def sum(lst: List[Int]): Int = lst match {
case Nil => 0
case h :: t => h + sum(t)
}
原文发表于:http://nerd-is.in/2013-09/scala-learning-collections/
原本是觉得这一章主要是介绍了各种集合及其用法,看过就可以了。
不过到后面的部分,出现了一些新的概念,果然还是需要记录一下。
在本文中我就将集合介绍部分和使用方法部分省略掉了。
主要的集合特质
Scala中所有的集合都扩展了Iterable特质。集合又可以分为三类:
有先后次序的序列Seq;值的集合Set;键值对构成的对偶的映射Map。
三类集合下分别还实现了特殊访问方式的特质:可以由下标来进行随机访问的IndexedSeq;
可按照顺序访问的SortedSet;可按顺序访问的SortedMap。
迭代器
在迭代器之前,已经介绍了集合的不少使用方法,多是带有函数式特征的。
而且在Scala中,也更加鼓励使用这些方法来进行操作。在面向对象编程中,
迭代器是更加常见的,用来操作集合的方法。
对于完整构造需要很大开销的集合来说,使用迭代器是个不错的想法。
比如在用Source.fromFile读取文件的时候。使用迭代器时,只有在需要的时候才去取元素,
所以不会一次性将文件全部读取到内存。而使用迭代器时,
需要注意的当然是迭代器是否有效,以及迭代器的指向位置。
流(A3)
流,stream,是一个尾部被懒计算的不可变列表。流会缓存下中间计算过的值,所以可以重新访问已经访问过的值,这点是与迭代器不同的。
懒视图
其他的集合也可以得到懒(lazy)计算相似的效果。使用集合的view方法。懒视图不会存储已经计算过的值。
懒视图可以用来避免构建大型中间集合,适合于处理需要多种方式进行变换的大型集合。
在上面的代码中,就避免了从pow方法中构建的中间集合map。
线程安全的集合
可变集合可以混入特质来使集合的操作变为同步的。这样的特质共有六个,都以Synchronized开头,详细的我就不列了。
需要注意的是,混入特质后,只是将操作变为同步的,并不能保证集合是线程安全的。(比如,并发进行修改和遍历集合。)
通常可以使用java.util.concurrent包中的类来保证线程安全,而且可以将这些集合也转换成Scala集合来使用(使用JavaConversions)。
并行集合
在Scala中可以方便地得到一个集合的并行实现。
上面的代码中coll是一个大型集合,而par方法会得到集合的并行实现——会尽可能地并行地执行结合方法。将上面的求和来说明,集合会被分成多个区块,然后由多个线程来对这些区块来进行求和,最后将区块的结果汇总得到最终的和。
par方法返回的是ParIterable的子类型,但ParIterable并不是Iterable的子类型。可以使用ser方法将并行集合转换回串行集合。
本章的内容虽然多,但基本都是些用久了没不会有问题的内容。不过集合用来增删的操作真是有点多啊。
2. 解答: