本次实验以爬取“国家统计局”首页中的【上海市城乡居民收支基本情况】为例,国家统计局(https://data.stats.gov.cn/index.htm)其他页面的爬取方法大同小异
1.爬虫基本流程
- 发起请求:通过http/https库向目标站点发起请求,即发送一个request,请求可以包含额外的headers等信息,等待服务器响应
- 获取相应内容:如果服务器能正常响应,会得到一个response,response的内容便是所要获取的页面内容,类型可能有HTML,json字符串,二进制数据(如图片视频)等类型
- 解析内容:得到的内容可能是HTML,可以用正则表达式,网页解析库进行解析,可能是json,可以直接转为json对象,可能是二进制数据,可以做保存或者进一步的处理
(本次实验得到的解析内容是json) - 保存数据:可以存为文本,也可以保存至数据库,或者特定格式的文件
2.打开网页并分析
国家统计局的网站很奇怪,明明是https却会告警不安全,首次打开界面如下(本人使用的是谷歌浏览器)

点击“高级”-“继续前往”,方可进入首页
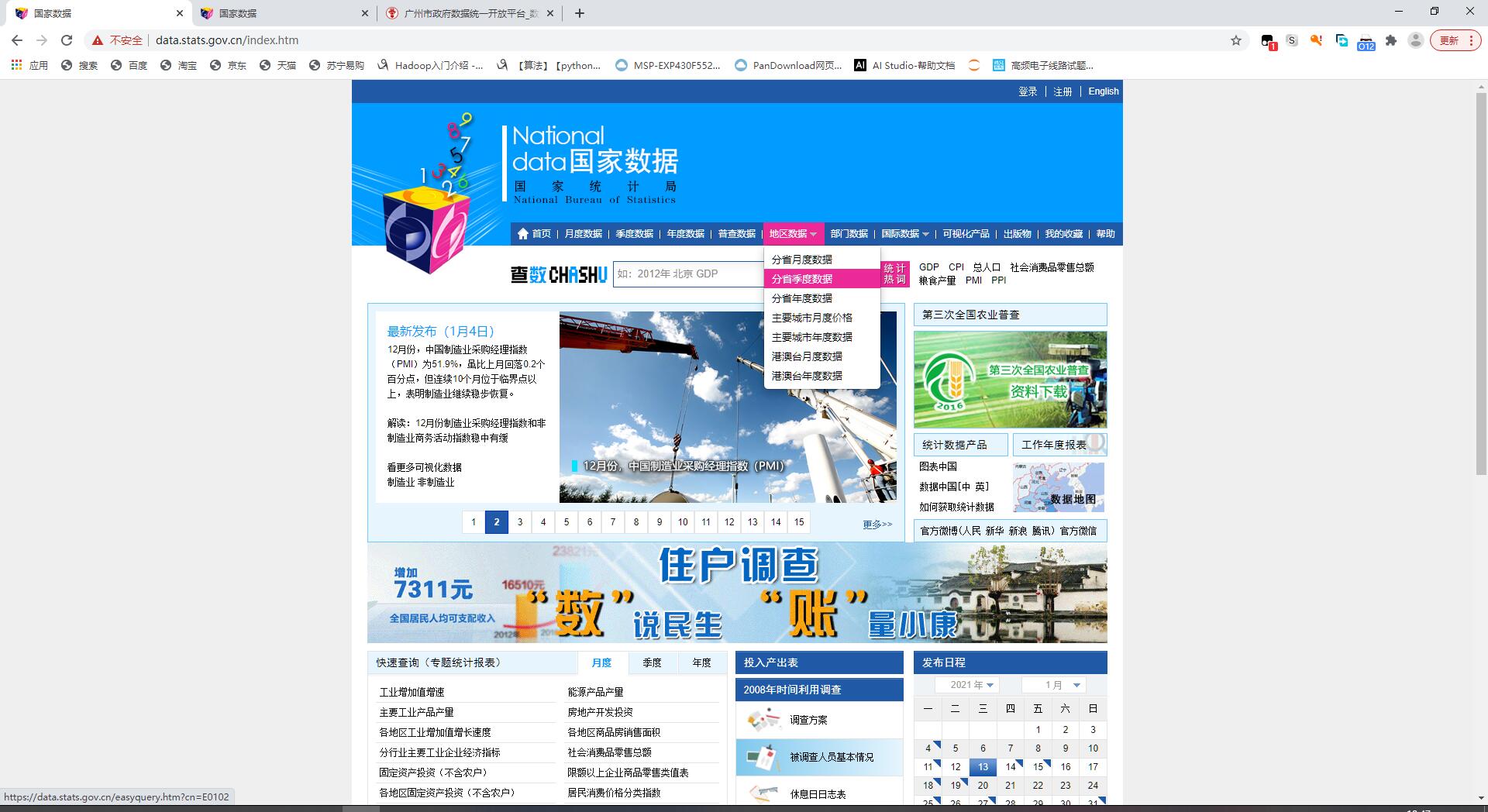
选择“季度数据”-“分省季度数据”
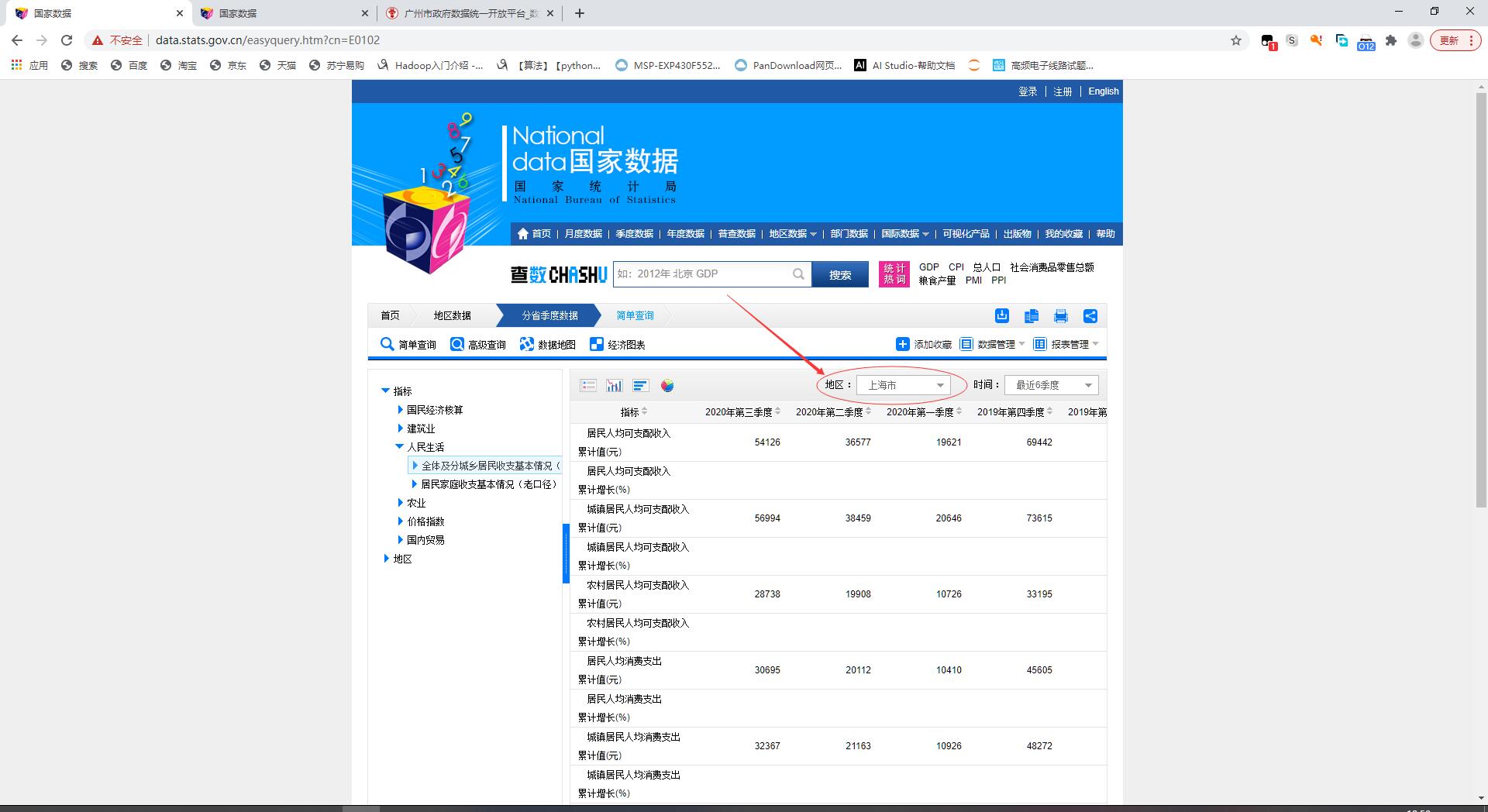
选择“人民生活”-“城乡收支情况”

地区修改为“上海市”
按下F12,进入浏览器调试模式

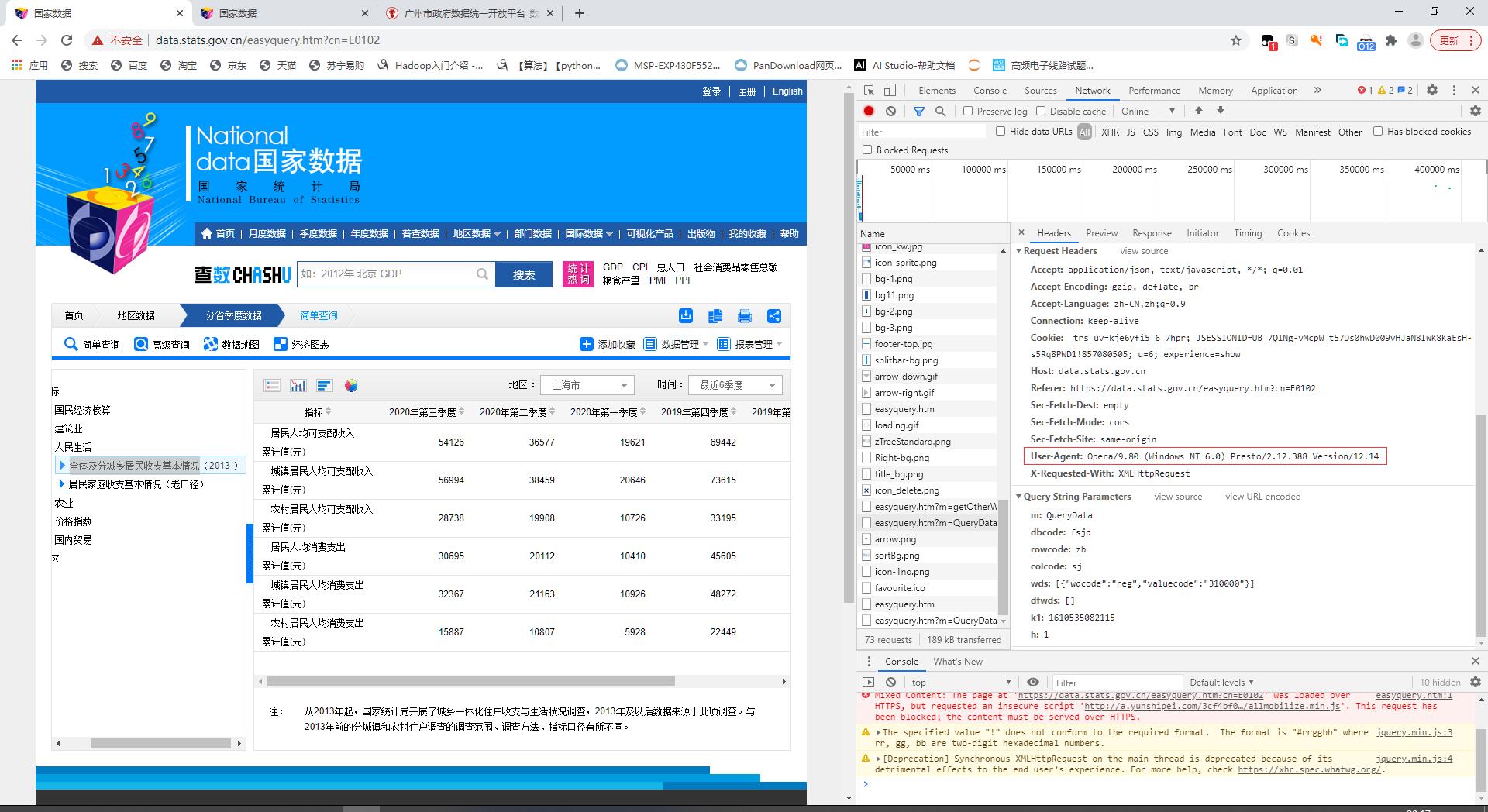
刷新重新获取网页信息,找到easyquery.htm?m=Query Data&dbc...的文件。可以先选中"XHR"过滤条件,缩小查找范围
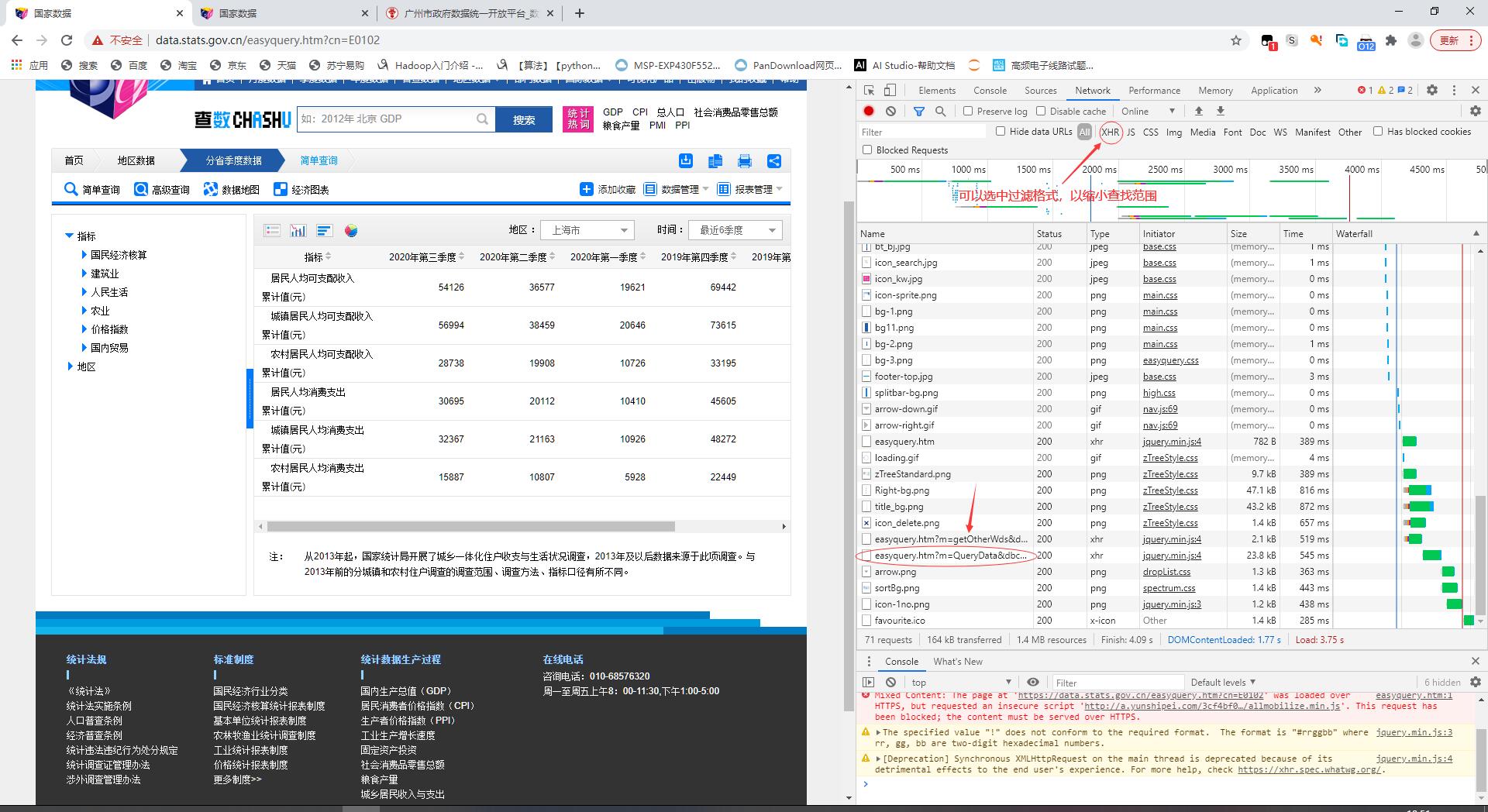
怎么确认这个文件就包含有我们要找的数据呢?点击“response”板块,向右拖动滑块可以看到表格数据可以一一对应(但数据并没有连续出现)
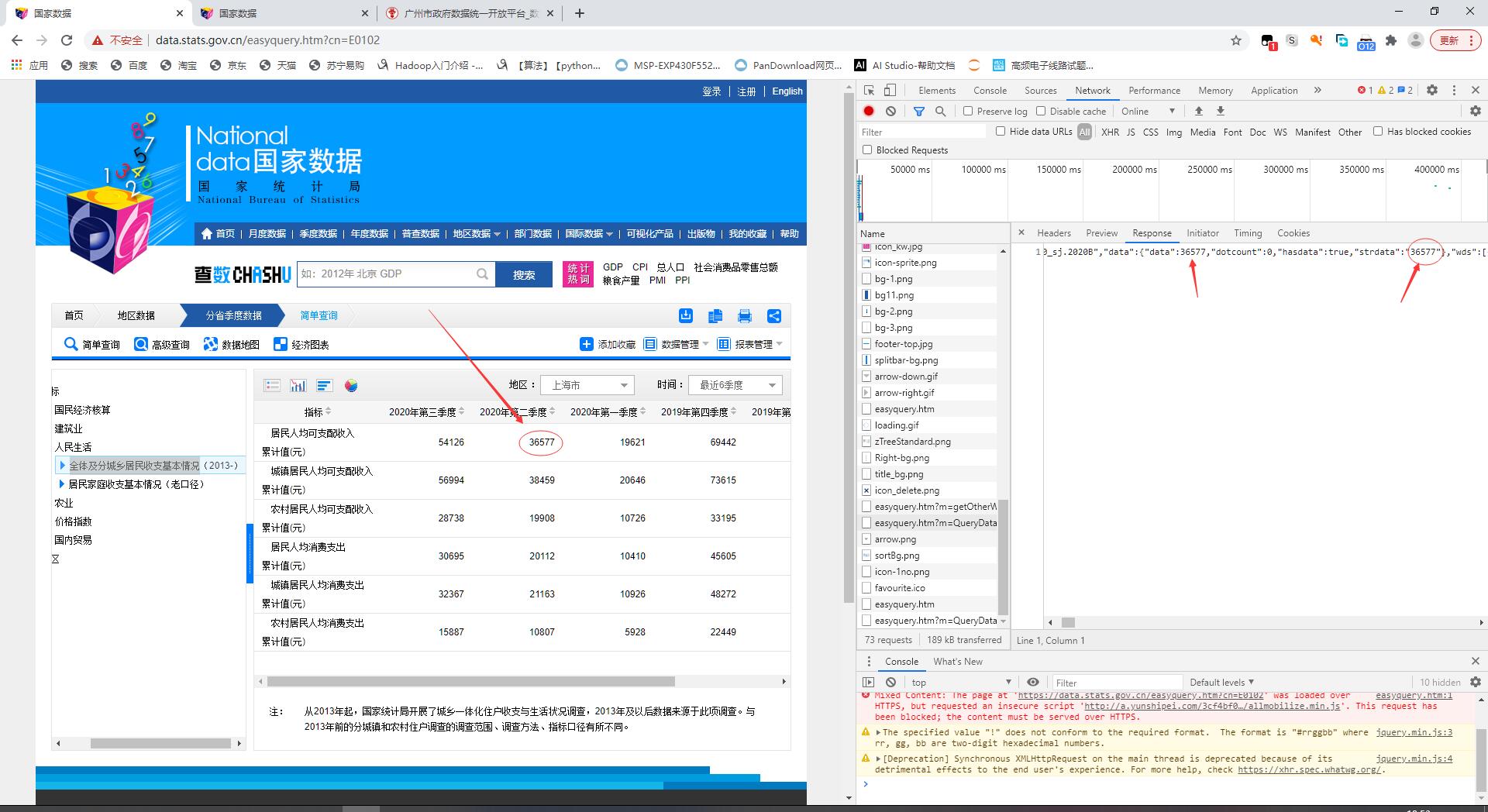
注意:这里的data和strdata看上去一样,但实际格式不一样,data是int或double格式,strdata是str格式,这个表格有一些空数据行,字符串格式方便做判断,字符串转数字使用eval()即可
3.完整代码及解析
注:缺少的库可以在命令行使用pip命令安装,如缺少requests库,可以在命令行输入命令
pip install requests
import urllib3
# 使用urllib3.disable_warnings()在关闭SSL认证(verify=False)情况下
# 将requests请求禁用安全请求警告
import requests # 使用Requests发送网络请求
import time # 用来获取时间戳(计算当前时间,用于网页验证)
import json # 处理json文件
import numpy as np # 处理数组
import pandas as pd # np.array()转换成pd.DataFrame格式,再使用to_excel()写入excel表格
# 获取毫秒级时间戳,用于网页验证
def getTime():
return int(round(time.time() * 1000))
# 数据预处理,获取json列表中层层包裹的strdata元素(数据)
def getList(length):
List=[]
for i in range(length):
temp = js['returndata']['datanodes'][i]['data']['strdata']
# 城乡居民收支列表中,原网站有同比增长数据为空,若直接使用eval()会报错,需要先判断
if(len(temp)!=0):
# eval()数字转字符串
List.append(eval(temp))
return List
if __name__ == '__main__':
# 请求目标网址(链接?前面的东西)
url='https://data.stats.gov.cn/easyquery.htm'
# 请求头,User-Agent: 用来证明你是浏览器,满足一定格式即可,不一定和自己的浏览器一样
headers={'User-Agent':'Mozilla/5.0(Windows;U;Windows NT6.1;en-US;rv:1.9.1.6) Geko/20091201 Firefox/3.5.6'}#浏览器代理
# 构造参数键值对,具体数值从网页结构参数中获取
key={}
key['m']='QueryData'
key['dbcode']='fsjd'
key['rowcode']='zb'
key['colcode']='sj'
key['wds']='[{"wdcode":"reg","valuecode":"310000"}]'
key['k1']=str(getTime())
# "wdcode":"reg" 地区栏
# 上海 310000
key['dfwds']='[{"wdcode":"zb","valuecode":"A0300"},{"wdcode":"sj","valuecode":"LAST6"}]'
# "wdcode":"zb" 选取左侧哪个条目,"wdcode":"sj"选项框中选取"最近6季度"
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings()
# 发出请求,使用post方法,这里使用前面自定义的头部和参数
# !!!verify=False,国家统计局20年下半年改用https协议,若不加该代码无法通过SSL验证
r = requests.post(url, headers=headers, params=key,verify=False)
# 使用json库中loads函数,将r.text字符串解析成dict字典格式存储于js中
js = json.loads(r.text)
# 得到所需数据的一维数组,利用np.array().reshape()整理为二维数组
length=len(js['returndata']['datanodes'])
res=getList(length)
# 总数据划分成6行的格式
array=np.array(res).reshape(len(res)//6,6)
# np.array()转换成pd.DataFrame格式,后续可使用to_excel()直接写入excel表格
df_shanghai=pd.DataFrame(array)
df_shanghai.columns=['2020年第三季度','2020年第二季度','2020年第一季度','2019年第四季度',
'2019年第三季度','2019年第二季度']
df_shanghai.index=['居民人均可支配收入累计值(元)',
'城镇居民人均可支配收入累计值(元)',
'农村居民人均可支配收入累计值(元)',
'居民人均消费支出累计值(元)',
'城镇居民人均消费支出累计值(元)',
'农村居民人均消费支出累计值(元)']
print(df_shanghai)
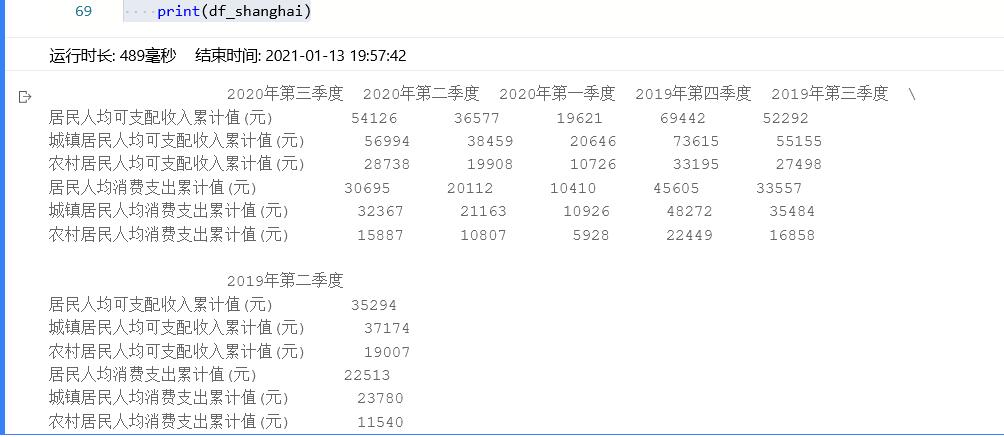
4.部分代码说明
数据提取
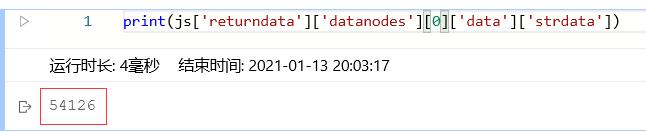
得到表格中的数据需要先分析提取到的js文件,打印内容如下:

将五层列表层层剥开,得到需要的strdata
请求网站
请求目标网址(''?''前面的东西)
url='https://data.stats.gov.cn/easyquery.htm'
请求头,User-Agent: 用来证明你是浏览器,满足一定格式即可,不一定要和自己的浏览器一样
headers={'User-Agent':'Mozilla/5.0(Windows;U;Windows NT6.1;en-US;rv:1.9.1.6) Geko/20091201 Firefox/3.5.6'}#浏览器代理
构造参数键值对,下列参数会以 & 连接,放在链接的''?''后面
key={}
key['m']='QueryData'
key['dbcode']='fsjd'
key['rowcode']='zb'
key['colcode']='sj'
key['wds']='[{"wdcode":"reg","valuecode":"310000"}]'
key['k1']=str(getTime())
key['dfwds']='[{"wdcode":"zb","valuecode":"A0300"},{"wdcode":"sj","valuecode":"LAST6"}]'

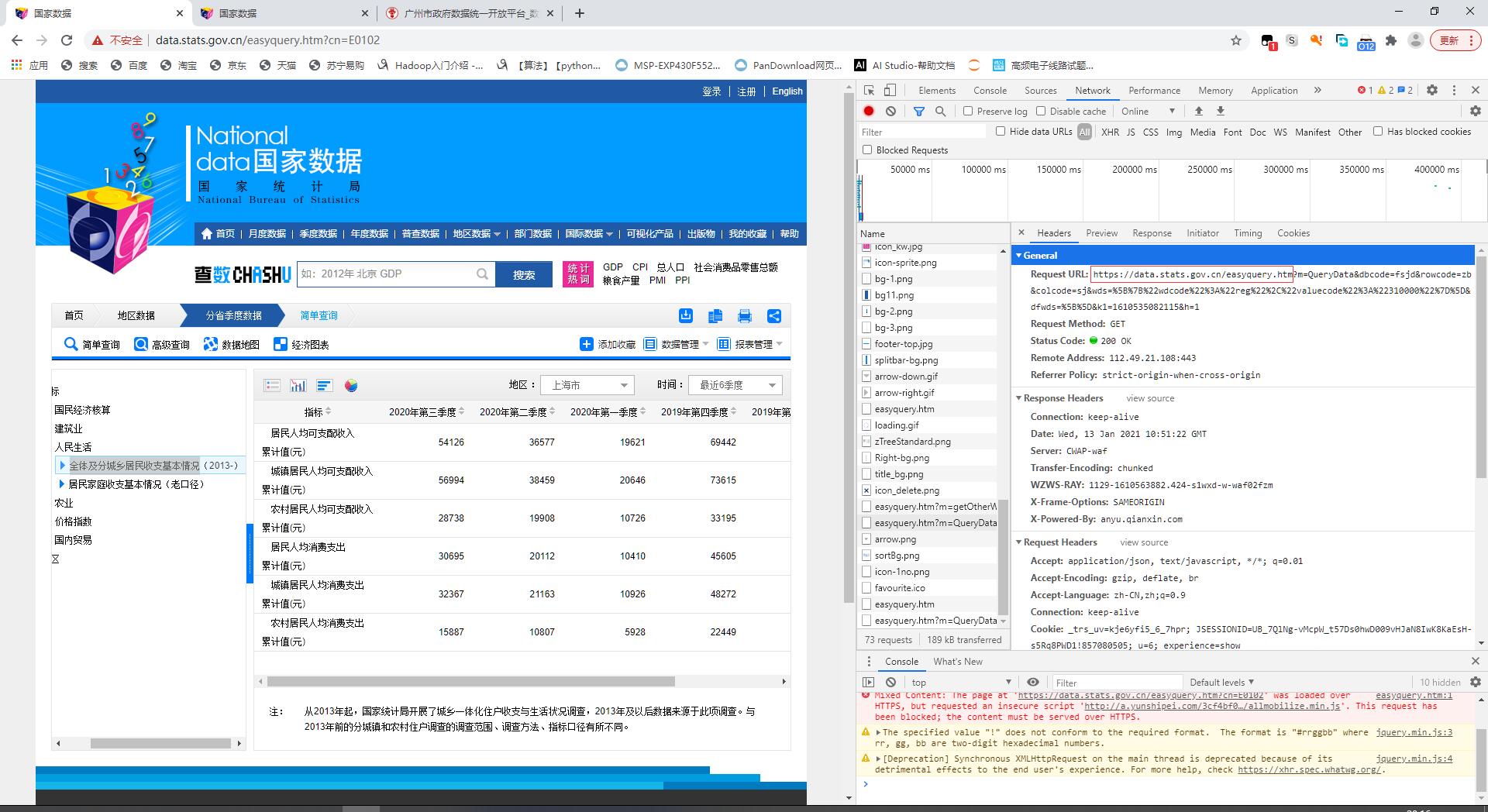
部分参数可以从下图所示位置查看到,有些不显示的为默认,如果需要显示相同页面,需选取选项框中的相应选项

5.数据保存到excel表格
爬虫爬到的数据现以panda.dataframe格式存储,可以利用to_excel()函数,直接保存在excel表格中
# write对象为该Excel工作簿,使用该方法保存多个工作表
write = pd.ExcelWriter('F:/Ivory_Tower/norm/分省季度数据_城乡居民收支.xls') #该路径自己设置即可,没有该文件的话会自行创建一个,存在的话写入会覆盖原内容
df_shanghai.to_excel(write,sheet_name='上海')
#如果爬多个省份的数据,可以写入多个工作表,且必须要加上save()保存
write.save()
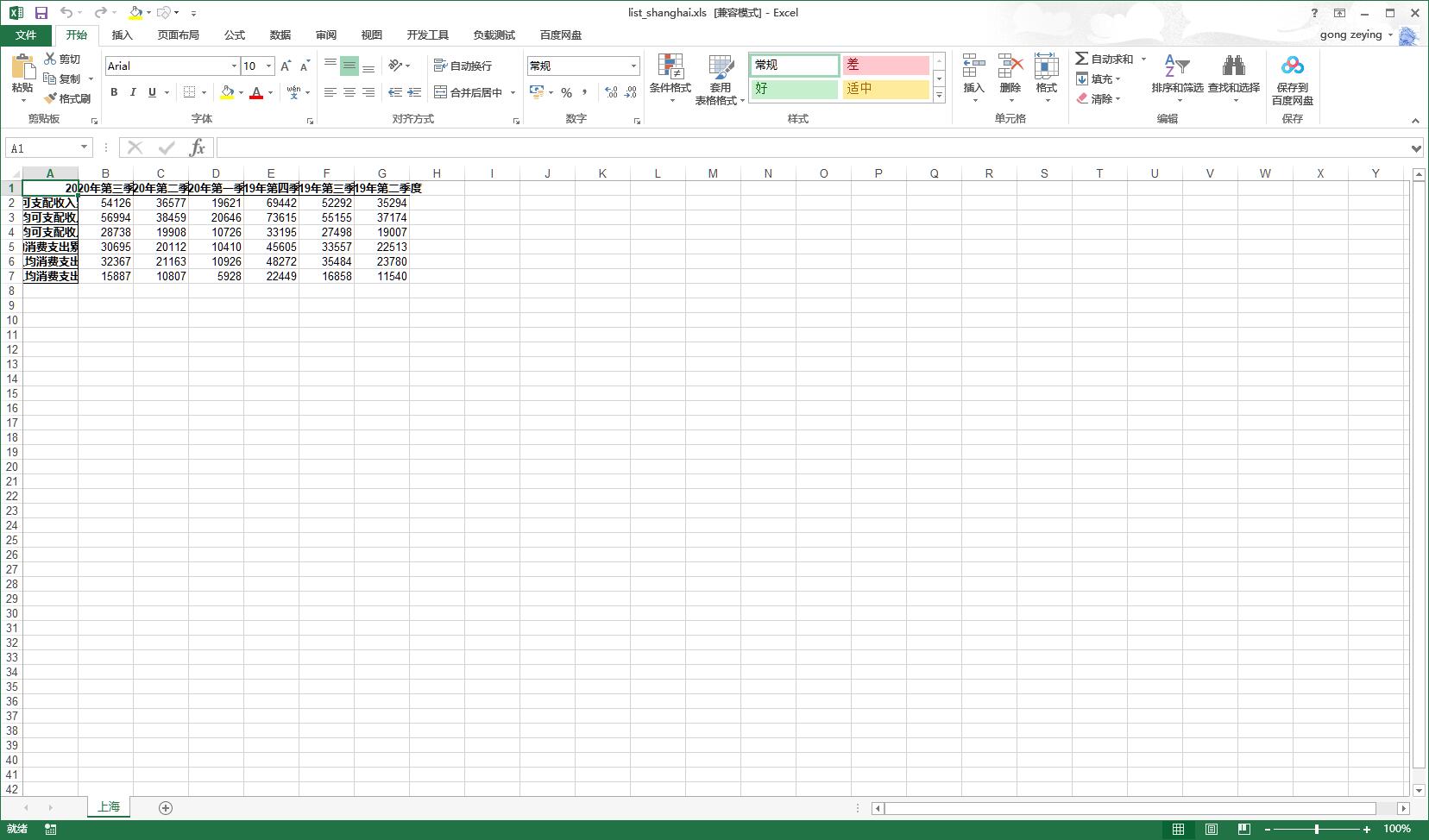
6.表格优化(可选)
可以借助python代码,优化表格格式,如上图所示的结果不尽人意,至少还需要自动调整列宽。
这里本人采用xlwings库,需要先在命令行下载相应的库
pip install xlwings
pip install pywin32
# 使用xlwings库,利用python编辑整理Excel表格
import xlwings as xw
if __name__ == '__main__':
app=xw.App(visible=False,add_book=False) #过程不可见,不添加新工作表
wb=app.books.open(r'F:/Ivory_Tower/norm/分省季度数据_城乡居民收支.xls')
# wb就是新建的工作簿(workbook)
# 对8个工作表,分别进行操作
for i in range(8):
rng=wb.sheets[i].range('A1:H20') # 选中这些单元格
rng.api.HorizontalAlignment = -4108 # 文字水平方向居中
rng.autofit() # 自动调整行高列宽
wb.save()
wb.close()
app.quit()
运行代码,即可得到以下效果 (后续多爬了其他一些省份,在key处修改相应参数即可)

7.参考资料
史上超详细python爬取国家统计局数据:https://blog.csdn.net/qq_41988893/article/details/103017854
如果报其他各种各样莫名其妙的错,可以评论或私信询问哦~