如对Linux用户态驱动程序开发有兴趣,请阅读本文,否则请飘过。
User-Space Device Drivers in Linux: A First Look | 初识Linux用户态设备驱动程序
User-Space Device Drivers in Linux: A First Look Mats Liljegren Senior Software Architect Device drivers in Linux are traditionally run in kernel space, but can
also be run in user space. This paper will take a look at running
drivers in user space, trying to answer the questions in what degree
the driver can run in user space and what can be gained from this?
Linux设备驱动通常运行在内核空间,但是也可以运行在用户空间。本文将介绍运行在用户空间中的设备驱动程序,试图回答以下两个问题:驱动程序在用户空间中运行的程度,以及从中获得的好处。
In the '90s, user-space drivers in Linux were much about how to make graphics run faster[1] by avoiding calling the kernel. These drivers where commonly used by the X-windows server. User-space driver has become ever more important, as a blog post by Tedd Hoff[2] illustrates. In his case the kernel is seen as the problem when trying to achieve high server connection capacity. Network interface hardware companies like Intel, Texas Instruments and Freescale have picked up on this and are now providing software solutions for user-space drivers supporting their hardware.
在上世纪90年代,在Linux中的用户空间驱动程序集中于如何使图形运行得更快,通过避免内核调用。这些驱动程序通常在X-windows服务器上使用。用户空间驱动程序变得越来越重要, 在Tedd Hoff发表的博客中有所论述。在他论述的例子中,内核被认为是问题之所在,当试图提供高并发连接服务器能力(注:c10k问题)的时候。诸如英特尔、德州仪器公司和飞思卡尔这样的网络接口硬件公司已经开始研究这一问题,现在他们正在为支持他们的硬件的用户空间驱动程序提供软件解决方案。
1. Problems with kernel-space drivers 内核空间驱动程序存在的问题
Device drivers normally run in kernel space, since handling interrupts and mapping hardware resources require privileges that only the kernel space is allowed to have. However, it is not without drawbacks.
设备驱动程序通常在内核空间中运行,因为中断处理和硬件资源映射需要特权,对应的特权只有内核空间才允许拥有。然而,它也并非没有缺点。
1.1 System call overhead 系统调用的开销
Each call to the kernel must perform a switch from user mode to supervisor mode, and then back again. This takes time, which can become a performance bottleneck if the calls are frequent. Furthermore, the overhead is very much non-predictable, which has a negative performance impact on real-time applications.
对内核的每一个调用必须从用户模式切换到超级管理(内核)模式,然后再返回。这显然需要时间,如果调用频繁的话,就会成为性能瓶颈。此外,开销很大程度上是不可预测的,这对实时应用程序将产生负面的性能影响。
1.2 Steep learning curve 学习曲线陡峭
The kernel-space API is different. For example, malloc() needs to be replaced by one of the several types of memory allocations that the kernel can offer, such as kmalloc(), vmalloc(), alloc_pages() or get_zeroed_page(). There is a lot to learn before becoming productive.
跟用户空间API相比,内核空间API有所不同。例如,如取代malloc()的话,内核就提供了几种不同类型的内存分配API,比如kmalloc(), vmalloc(), alloc_pages()或get_zeroed_page()。想在内核编程方面卓有成效,需要学习的东西很多。
1.3 Interface stability 接口稳定性
The kernel-space API is less stable than user-space APIs, making maintenance a challenge.
与用户空间的API比较而言, 内核空间API更不稳定,这无疑给代码维护带来了很大的挑战。
1.4 Harder to debug 调试更困难
Debugging is very different in kernel space. Some tools often used by user-space applications can be used for the kernel. However, they represent exceptions rather than rule, where LTTNG[3] is an example of the exception. To compensate for this, the kernel has a lot of debug, tracing and profiling code that can be enabled at compile time.
在内核空间中,调试有所不同,而且非常不同于用户空间调试。在用户空间应用程序调试中经常使用的一些工具可以用于内核调试。然而,他们代表着异常而非常态, 例如LTTNG[3]就是一个例外。为了弥补这一点,内核存在着许多调试、跟踪和分析代码,这些代码可以在编译的时候被启用。
1.5 Bugs more fatal 错误更加致命
A crashing or misbehaving kernel tends to have a more severe impact on the system than a crashing or misbehaving application, which can affect robustness as well as how easy it is to debug.
内核崩溃或行为不正确对系统的影响比应用程序崩溃或不正确对系统的影响更大,这影响到系统的健壮性以及调试的容易程度。
1.6 Restrictive language choice 编程语言选择严格受限
The kernel space is a very different programming environment than user space. It is more restricted, for example only C language is supported. This rules out any script based prototyping.
内核空间与用户空间的编程环境非常不一样。它受到的限制更多,例如只支持C语言。这就将任何基于脚本的原型设计排除在外了。
2. User-space drivers 用户空间驱动
If there are so many problems with having device drivers in kernel space, is it time to have all drivers in user space instead? As always, everything has its drawbacks, user-space drivers are no exception. Most of the issues with kernel-space drivers are solved by having the driver in user space, but the issue with interface stability is only true for very simple user-space drivers. For more advanced user-space drivers, many of the interfaces available for kernel-space drivers need to be re-implemented for user-space drivers. This means that interface stability will still be an issue.
既然在内核空间中的设备驱动程序存在着很多问题,那么是否应该将所有驱动程序都放在用户空间中呢?一如既往地,任何解决方案都有缺点,用户空间驱动程序也不例外。内核空间驱动程序存在的大部分问题都可以通过用户空间驱动程序给解决掉,但接口稳定性的问题是只适用于那些很简单的用户空间驱动程序。对于更高级的用户空间设备驱动,许多在内核空间才可用的接口需要为用户空间驱动重新实现一下,这意味着接口的稳定性仍然是一个问题。
3. Challenges with user-space drivers 用户态设备驱动面临的挑战
There is a fear in the Linux kernel community that user-space drivers are used as a tool to avoid the kernel's GPLv2 license. This would undermine the idea with free open source software ideas that GPLv2 has. However, this is outside the scope of this paper.
在Linux内核社区,有这样一个恐惧,那就是用户态驱动程序被当做一个工具来避免了内核GPLv2许可。这无疑将破坏GPLv2一贯主张的开源软件理念。然而,这一点超出了本文讨论的范围。
Apart from this there are technical challenges for user-space drivers.
除此之外,用户态设备驱动还存在技术上的诸多挑战。
3.1 Interrupt handling 中断处理
Without question, interrupt handling is the biggest challenge for a user-space driver. The function handling an interrupt is called in privileged execution mode, often called supervisor mode. User-space drivers have no permission to execute in privileged execution mode, making it impossible for user-space drivers to implement an interrupt handler.
毫无疑问,中断处理是用户态设备驱动面临的最大的挑战。中断处理函数在特权执行模式(又叫做超级管理模式)下才能被调用。用户态设备驱动程序不允许在特权模式下执行,这使得在用户态设备驱动里实现一个中断处理程序是不可能的。
There are two ways to deal with this problem: Either you do not use interrupts, which means that you have to poll instead. Or have a small kernel-space driver handling only the interrupt. In the latter case you can inform the user-space driver of an interrupt either by a blocking call, which unblocks when an interrupt occurs, or using POSIX signal to preempt the user-space driver.
解决这个问题有两种办法:要么不使用中断,要么有一个内核空间的驱动来专门处理中断。在前一种办法中,不使用中断意味着必须使用轮询。在后一种办法中,你可以通过阻塞调用来通知用户态设备驱动程序,在中断发生时打开阻塞调用,或者使用POSIX信号来抢占用户态设备驱动。
Polling is beneficial if interrupts are frequent, since there is considerable overhead associated with each interrupt, due to the switch from user mode to supervisor mode and back that it causes. Each poll attempt on the other hand is usually only a check for a value on a specific memory address.
如果中断频繁发生的话,那么轮询就是有益的,因为每次中断都有相当大的开销,这些开销来源于从用户模式切换到内核模式,然后再从内核模式返回到用户模式。另一方面,每一次轮询通常只是对位于特定内存地址的值进行检查而已(,所以轮询有好处,能减少系统开销)。
When interrupts become scarcer, polling will instead do a lot of work just to determine that there was no work to do. This is bad for power saving.
当中断变得稀少时,轮询将会做大量的工作来确定没有什么工作可以做,这不利于节省能源消耗。
To get power saving when using user-space drivers with polling, you can change the CPU clock frequency, or the number of CPUs used, depending on work load. Both alternatives will introduce ramp-up latency when there is a work load spike.
在用户态设备驱动程序中使用轮询的时候,如果要省电的话,可以根据工作负载来修改CPU的时钟频率,或者更改在用的CPU的个数。当遇到工作负载峰值的时候,这两种方法都将引入急剧的延迟。
3.2 DMA 直接内存访问
Many drivers use hardware dedicated to copying memory areas managed by the CPU to or from memory areas managed by hardware devices. Such dedicated hardware is called direct memory access, or DMA. DMA relieves the CPU of such memory copying.
许多驱动程序使用专门的硬件来做内存拷贝,从CPU管理的内存区域到硬件管理的内存区域,或相反。这种专门的硬件叫做DMA(直接内存访问)。有了DMA,CPU得以从繁重的内存拷贝工作中解放出来。
There are some restrictions on the memory area used for DMA. These restrictions are unique for each DMA device. Common restrictions are that only a certain physical memory range can be used, and that the physical memory range must be consecutive.
给DMA使用的内存区域存在着一些限制。这些限制对于每一个DMA设备来说都是独一无二的。通常的限制是只能使用一定的物理内存范围,而且物理内存范围必须是连续的。
Allocating memory that can be used for DMA transfers is non-trivial for user-space drivers. However, since DMA memory can be reused, you only need to allocate a pool of memory to be used for DMA transfers at start-up. This means that the kernel could help with providing such memory when the user-space driver starts, but after that no further kernel interactions would be needed.
分配可用于DMA传输的内存,对于用户态设备驱动程序来说是十分重要的。然而,由于用于DMA传输的内存是可以重用的,所以只需要分配一个内存池,以便在DMA传输启动时被使用。这就意味着,当于用户态设备驱动程序启动时,内核空间可以提供这样一段内存,但是在那之后,不再需要进一步的内核交互。
3.3 Device interdependencies 设备的相互依赖关系
Devices are often structured in a hierarchy. For example the clock might be propagated in a tree-like fashion using different dividers for different devices and offer the possibility to power off the clock signal to save power.
通常用层次结构来列举设备。比如,时钟可以用树形方式繁殖,通过对不同的设备使用不同的分频器。时钟提供了对时钟信号提供断电的可能性以达到省电的目的。
There can be devices acting as a bridge, for example a PCI host bridge. In this case you need to setup the bridge in order to have access to any device connected on the other side of the bridge.
有设备可以用来做网桥,例如PCI主机网桥。在这种情况下,需要设置一个网桥,以便访问连接在桥上的另一侧的任何设备。
In kernel space there are frameworks helping a device driver programmer to solve these problems, but those frameworks are not available in user space.
在内核空间中,有帮助驱动程序开发人员解决这些问题的框架。但是,这些框架在用户空间却不可用。
Since it is usually only the startup and shutdown phases that affect other devices, the device interdependencies can be solved by a kernel-space driver, while the user-space driver can handle the actual operation of the device.
通常情况下,只有在启动阶段和关机阶段才会影响到其他设备,因此,设备之间的相互依赖关系可以为内核态设备驱动程序所解决。而用户态设备驱动可以对设备做实际的操作。
3.4 Kernel services 内核服务
Network device drivers normally interfaces the kernel network stack, just like block device drivers normally interfaces the kernel file system framework.
网络设备驱动程序通常与内核网络栈打交道,就像块设备驱动通常与内核文件系统框架打交道一样。
User-space drivers have no direct access to such kernel services, and must re-implement them.
用户态设备驱动不能够直接访问这样的内核服务,因此必须重新实现。
3.5 Client interface 客户端接口
The kernel has mechanisms for handling multiple clients accessing the same resource, and for blocking threads waiting for events or data from the device. These mechanisms are available using standard interfaces like file descriptors, sockets, or pipes.
内核有处理多个客户端访问相同的系统资源的机制,也有阻塞线程等待某个设备事件到达或者设备数据到达的机制。这些机制可以使用标准的接口来使用,例如文件描述符,套接口或管道。
To avoid using the kernel, the user-space driver needs to invent its own interface.
为了避免使用内核,用户态设备驱动需要发明自己的接口。
4. Implementing user-space drivers | 用户态设备驱动实现

The picture above shows how a user-space driver might be designed. The application interfaces the user-space part of the driver. The user-space part handles the hardware, but uses its kernel-space part for startup, shutdown, and receiving interrupts.
上面的图片显示了用户态设备驱动可能的设计。设备驱动的用户空间部分扮演了应用程序的接口。设备驱动的用户空间部分负责硬件处理,但是其内核空间部分则负责启动、关闭和接收中断。
There are several frameworks and software solutions available to help designing a user-space driver.
设计一个用户态设备驱动,可用的框架和软件解决方案不止一个。
4.1 UIO | Userspace I/O : 用户空间I/O
There is a framework in the kernel called UIO [5][4] which facilitate writing a kernel-space part of the user-space driver. UIO has mechanisms for providing memory mapped I/O accessible for the user-space part of the driver.
在内核中有一个称之为UIO(Userspace I/O)的框架,它可以用来帮助开发用户态设备驱动程序的内核空间部分。 UIO提供一种机制为设备驱动的用户空间部分提供可访问的的内存映射I/O。
The allocated memory regions are presented using a device file, typically called /dev/uioX, where X is a sequence number for the device. The user-space part will then open the file and perform mmap() on it. After that, the user-space part has direct access to its device.
分配的内存区域用一个设备文件来表示, 典型的设备文件叫做/dev/uioX, 其中X是设备的序列号。 设备驱动的用户空间部分将打开那个文件并在对应的文件描述符上做mmap()操作。接下来,设备驱动的用户空间部分就可以直接访问/dev/uioX文件对应的设备。
By reading from the same file being opened for mmap(), the user-space part will block until an interrupt occurs. The content read will be the number of interrupts that has occurred. You can use select() on the opened file to wait for other events as well.
在读取已经为mmap()打开的同一文件时,设备驱动的用户空间部分将阻塞直到有中断发生,读取的内容将是已经发生的中断数。也可以在已经打开的文件上使用select()来等待其他事件发生。
For user-space network drivers there are specialized solutions specific for certain hardware.
对于用户空间的网卡驱动来说,针对特定的硬件有专门的解决方案。(有关UIO的详细信息, 请阅读 uio-howto 和 Userspace I/O drivers in a realtime context.)
4.2 DPDK | 数据平面开发套件
Data Plane Development Kit, DPDK[6], is a solution from Intel for user-space network drivers using Intel (x86) hardware. DPDK defines an execution environment which contains user-space network drivers. This execution environment defines a thread for each CPU, called lcore in DPDK. For maximum throughput you should not have any other thread running on that CPU.
DPDK(数据平面开发套件)是英特尔公司为其x86硬件开发的用户态网卡驱动解决方案。DPDK定义了一套运行环境,该环境包括了用户态网卡驱动。这套运行环境还为每一个CPU都定义了一个线程,在DPDK中称之为lcore。为了保证吞吐量能够最大化,在已经运行lcore线程的CPU上就不要再运行任何其他线程。
While this package of libraries focuses on forwarding applications, you can implement server applications as well. For server DPDK applications you need to implement your own network stack and accept a DPDK specific interface for accessing the network.
虽然DPDK库侧重于实现转发应用,但是也可以用来实现服务端应用。如果要实现DPDK服务端应用,需要自己实现网络栈,而且能够在用于访问网络的特定的DPDK接口上进行accept操作。
Much effort has been put in memory handling, since this is often critical for reaching the best possible performance. There are special allocation and deallocation functions that try to minimize TLB[10] misses, use the most local memory for NUMA[11] systems and ensure even spread on multi-channel memory architectures [12].
大量的投入放在内存处理上,因为这往往是达到最佳性能的关键。 DPDK有专门的内存分配/释放函数来做这样的事情,试图将TLB(Translation Lookaside Buffer:地址变换高速缓存)命不中最小化,在NUMA系统中尽可能地使用特定CPU的本地内存,甚至确保在多通道的内存体系结构中能够平衡扩频。
4.3 USDPAA | 用户态数据平面加速架构
User-space Data Plane Acceleration Architecture, USDPAA[7], is a solution from Freescale for the same use case as DPDK but designed for their QorIQ architecture (PowerPC and ARM). The big difference is that QorIQ uses hardware for allocating, de-allocating and queuing network packet buffers. This makes memory management easier for the application.
USDPAA(用户态数据平面加速架构)是Freescale(飞思卡尔)公司提出的与Intel的DPDK类似的解决方案,专门针对其QorIQ架构(PowerPC和ARM)而设计。与DPDK不同的是,QorIQ使用硬件来分配/取消分配和排队网络数据包缓冲区。这对应用程序来说,内存管理就容易多了。
4.4 TransportNetLib
TransportNetLib[8] is a solution from Texas Instruments. It is similar to USDPAA but for the Keystone architecture (ARM).
TransportNetLib是德州仪器的解决方案。该方案与USDPAA类似,只不过只针对Keystone架构(ARM)。
4.5 Open DataPlane
Open DataPlane, ODP[9], is a solution initiated by Linaro to do the same as DPDK, USDPAA and TransportNetLib, but with vendor generic interfaces.
(ODP)开放数据平面是由Linaro发起的跟DPDK, USDPAA和TransportNetLib类似的解决方案,但是提供与特定的硬件供应商无关的通用接口。
4.6 Trying out DPDK | DPDK尝尝鲜
To get the feeling for the potential performance gain from having a user mode network device driver, a DPDK benchmark application was designed and executed.

为了真切感受一下在使用了用户态网卡驱动之后的性能提升,这里设计并执行了一个DPDK基准测试。
The design of the application can be seen in the picture above. It executes as four instances each running on its own CPU, or lcore, as DPDK calls them.
应用设计见上图。该设计运行4个实例,每个实例运行在它自己的CPU(在DPDK中称之为lcore)上。
Each instance is dedicated to its own Ethernet device sending and receiving network packets. The packets sent has a magic word used for validating the packets and a timestamp used for measuring transport latency.
每一个实例都专注于在它自己的以太网设备上发送和接收网络数据包。发送的数据包包含了一个魔幻单词和一个时间戳,其中,魔幻单词用于验证数据包的有效性,时间戳则用于测量传输延迟。
The instances are then paired using loopback cables. To be able to compare user-space driver with kernel-space driver, one pair accesses the hardware directly using the driver available in DPDK, and the other pair uses the pcap[13] interface. All four Ethernet devices are on the same PCI network card.
两个实例通过背靠背连接在一起作为实例对儿使用。为了能够对用户态设备驱动与内核态设备驱动做出对比,一组实例对儿通过DPDK的驱动直接访问硬件,另一组实例对儿则使用pcap接口访问硬件。所有(4个)的以太网设备都连接在同一个PCI网卡上。
There is a fifth lcore (not shown in the picture above) which periodically collects statistics and displays it to the screen.
第5个lcore(未在图上显示出来)负责周期性地收集统计数据并输出到屏幕上。
The hardware used was as follows:
o Supermicro A1SAi-2750F mother board using Intel Atom
C2750 CPU. This CPU has 8 cores with no hyperthreading.
o 16GB of memory.
o Intel Ethernet server adapter i350-T4, 1000 Mbps.
使用的硬件如下:
- 超微A1SAi-2750F主板,英特尔安腾C2750处理器,8核心,但不支持超线程。
- 16GB内存。
- 英特尔(应用于服务器的)千兆以太网卡i350-T4。
The table below shows the throughput and latency for user-space driver compared to kernel-space driver.

用户态驱动和内核态驱动的吞吐量与延迟对比。
A graph showing the throughput:

吞吐量对比图。
A graph showing the latency:
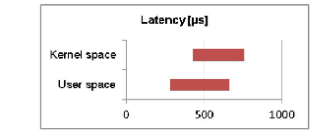
延迟对比图。
The theoretical throughput maximum is the sum of the send and receives speed for the network interface. In this case this is 1000 Mbps in each direction, giving a theoretical maximum of 2000 Mbps. The throughput includes packet headers and padding.
理论上的吞吐量最大值是发送和接收速度的总和。在这个例子中,发送/接受速度都是1000Mbps, 所以理论上的吞吐量最大值为2000Mbps。吞吐量包括数据包头和数据包填充。
User-space driver achieved a throughput boost of about four times over kernel-space driver.
从吞吐量上看,用户态设备驱动性能非常好,相当于内核态驱动的4倍。
Latency was calculated by comparing the timestamp value found in the network packet with the current clock when packet was received. The latency for user-space driver was slightly less than for kernel-space driver.
通过比较网络数据包中的时间戳和收到数据包的那一刻的系统时钟,就能计算出延迟。用户态设备驱动的延迟略小于内核态设备驱动的延迟。
Four threads, each continuously running netperf TCP streaming test against loop-back interface, were used as a stress while running the DPDK benchmark application. This had no noticeable impact on the measurements.
在跑DPDK基准应用的时候,有4个线程作为压力测试在同时运行,每一个线程在loop-back接口上连续地运行netperf TCP流量测试。这些压力测试对测量结果没有什么明显的影响。
5. Conclusion | 总结陈词
Implementing a user-space driver requires some work and knowledge. The major challenges are interrupts versus polling, power management and designing interface towards driver clients.
实现用户态设备驱动需要做更多工作和掌握更多的知识。主要的挑战就是中断v.s.轮询,电源管理和面向设备驱动客户端设计接口。
Support for user-space network drivers is a lot more developed than for other kinds of user-space drivers, especially for doing data plane forwarding type of applications.
在支持用户态网卡驱动开发方面,比支持其他类型的用户态设备驱动要多得多,尤其是针对数据平面转发类应用所做的开发。
A user-space driver can do everything a kernel-space driver can, except for implementing an interrupt handler.
除了无法实现中断处理程序之外,只要内核态设备驱动能做的事情,用户态设备驱动都能。
Comparing a user-space network driver with a kernel-space network driver showed about four times better throughput for the user space driver. Latency did not show a significant difference.
我们比较了内核态网卡驱动和用户态网卡驱动,发现在吞吐量方面,用户态网卡驱动性能表现比较突出,大约是内核态网卡驱动的4倍。但是在延迟方面,二者没有什么大的区别。
The real-time characteristics should be good for user-space drivers since they do not invoke the kernel. This was not verified in this paper, though.
虽然本文没有进行验证,但是用户态设备驱动的实时性应该会表现不错,因为不涉及到内核调用。