程序为什么需要内存
程序运行的目的:
- 程序运行是为了得到一定的结果,程序运行其实是在做一系列的数据计算,所以:程序=代码+数据;
- 程序运行的目的不外乎2个:过程、结果; 用函数来类比:函数的形参就相当于代加工的数据,函数的本体是代码,函数的返回值就是结果,函数体的执行过程就是过程。如下列函数:
-
int add(int a, int b) { return a + b; } // 这个函数的执行就是为了得到结果 void add(int a, int b) { int c; c = a + b; printf("c = %d. ", c); } // 这个函数的执行重在过程(重在过程中的printf),返回值不需要 intadd(int a, int b) { int c; c = a + b; printf("c = %d. ", c); return c; } // 这个函数又重结果又重过程
计算机程序运行过程:
- 计算机程序运行的过程其实就是多个函数相继运行的过程,程序由多个函数组成;
- 程序的本质是函数,函数的本质是加工数据的动作;
冯诺依曼结果和哈佛结构:
- 冯诺依曼:代码和数据放在一起;
- 哈佛结构:代码和数据分开存放;
- 代码:函数; 数据:全局变量和局部变量;
- 在S5PV210中运行的linux系统上,运行应用程序时:这时应用程序的代码和数据都在DRAM,所以这种结构是冯诺依曼结构;在单片机中,我们把程序烧写到Flash(NorFlash)中,然后在Flash中原地运行,程序中所涉及到的数据(全局变量、局部变量)不能放在Flash中,必须放在RAM(SRAM)中,这种就叫哈佛结构。
动态内存DRAM和静态内存SRAM:
- SRAM:静态内存 优点:不需要软件初始化,上电就能用;缺点:容量小,价格高;
- DRAM:动态内存 优点:容量大,价格低;缺点:上电不能使用,需要软件初始化;
- 单片机:内存需求量小,而且希望开发尽量简单,适合使用SRAM;
- PC机:内存需求量大,而且软件复杂,不在乎DRAM的初始化开销,适合全部使用DRAM;
- 嵌入式系统:内存需求量大,而且没有NorFlash等启动介质;
总结:为什么需要内存?
- 内存是用来存储数据的,数据在程序中表现为变量(在gcc中,其实常量也是储存在内存中的)。
- 大部分的单片机代码段储存在flash中,数据常量储存在flash中,对我们写程序至关重要,与程序运行有本质关系;
- 内存管理是我们写程序时很重要的话题,我们以前学过的很多编程的关键都是管理内存譬如数据结构(研究数据是如何组织的,数据放在内存中的)和算法(为了更有效更优秀的方法来加工数据,既然跟数据有关就离不开内存)
深入思考:如何管理内存(有OS时,无OS时)
- 有OS时:操作系统管理所有的硬件内存,将内存分为一个一个的页面(就是一块,一般是4KB),然后以页面为单位来管理。页面内用更细小的方式以字节来管理。操作系统为我们提供了内存管理接口,我们只需要用API来管理内存,如C语言中的malloc、free这些接口来管理内存。
- 无OS时:在没有操作系统(其实就是裸机程序)中,程序需要直接操作内存,编程者需要自己计算内存的使用和安排。如果编程者不小心把内存用错了,错误结果需要自己承担。
各种语言管理内存的区别:
- 汇编:直接操作内存(如0xd0020010),非常麻烦;
- C语言:汇编器帮我们管理内存,我们可以通过编译器提供的变量名来访问内存,操作系统下如果需要大块内存,可以通过API接口(malloc、free)来访问系统内存。裸机中需要大块内存需要自己定义数组来解决;
- C++:C++语言对内存的使用进一步封装。我们可以用new来创建对象(其实就是为对象分配内存),然后使用完了用delete来删除对象(其实就是释放内存)。所以C++语言对内存的管理比C要高级一些,容易一些。但是C++中内存的管理还是靠程序员自己来做。如果程序员new了一个对象,但是用完了忘记delete就会造成这个对象占用的内存不能释放,这就是内存泄漏。
- Java/C#等语言:这些语言不直接操作内存,而是通过虚拟机来操作内存。这样虚拟机作为我们程序员的代理,来帮我们处理内存的释放工作。如果我的程序申请了内存,使用完成后忘记释放,则虚拟机会帮我释放掉这些内存。听起来似乎C# java等语言比C/C++有优势,但是其实他这个虚拟机回收内存是需要付出一定代价的,所以说语言没有好坏,只有适应不适应。当我们程序对性能非常在乎的时候(譬如操作系统内核)就会用C/C++语言;当我们对开发程序的速度非常在乎的时候,就会用Java/C#等语言。
位、字节、半字、字和内存字宽
什么是内存:
- 硬件角度:SRAM、DRAM(DRAM分为多代:SDRAM、DDR...)
- 逻辑角度:内存可以随机访问,并可以读写;内存在编程过程中,天然用来定义变量(因为有内存,所以C语言才能定义变量),程序中一个变量,代表内存中一个内存地址;
内存的逻辑抽象图:
- 一个大格子中有许多小格子,每个格子对应一个内存地址;
- 系统位数(32位、64位)与数据总线有关,内存也与数据总线有关,32位系统内存为4G(2^32)
位和字节:
- 内存单元大小单位有4个:位(1bit)、字节(8bit)、半字(一般16bit)、字(一般32bit);
- 所有系统中,位都是1bit,字节都是8bit;
字和位宽:
- 历史上出现过16位、32位、64位操作系统,字的大小与操作系统有关,所以没必要可以记住这些单位的大小;
- 实际工作中在每种平台上,先搞清楚这个平台的定义;
- 编程时,一般是以字为单位,用不到这些概念,区分这个概念主要是因为有些文档中会用到,如果不区分,可能会造成对程序的误解;
- 在linux+ARM这个软硬件平台上,字是32位的;
内存位宽(硬件和逻辑两个角度):
- 硬件角度:硬件本身是有宽度的,硬件宽度可以通过级联的方式进行扩展,如16位内存条可以通过并联,得到32位内存条;
- 逻辑角度:内存的位宽可以是任意位的,我们直接操作即可,但实际操作限制于硬件特性,所以我们的很多实际操作都限制于硬件的特性;
内存编址和寻址、内存对齐
内存的编址方法:
- 计算机中CPU实际只认识内存地址,而不关心这个地址所代表的空间在哪里、怎么分布,因为硬件设计保证了按照这个地址就能找到这个格子,所以内存的单元的2个概念:地址和内存单元的两个方面。
关键:内存编址是以字节为单位的:
- 把内存比喻成一栋楼,那么每个楼里的一个一个房间就好像一个内存格子,这个格子的大小是固定的,就好像这个大楼里面所有的房间户型都是一样的;
内存和数据类型的关系:
- C语言常用的数据类型有:char、short、int、long、float、double;
- 整形int体现他和CPU本身的数据位宽是一样的,比如32位CPU,整形int就是32位的;
- 数据类型和内存的关系在于:数据类型是用来定义变量的,而这些变量需要存储、运算在内存中,所以数据类型必须和内存相匹配才能获得最好的性能,否则可能不工作或者效率低下;
- 32位系统最好用int,因为效率最高,原因在于32位的系统本身配合内存等也是32位,这样的硬件配置天生适合定义32位的int类型变量,效率最高。也能定义8位char类型变量或者16位short类型变量,但实际上访问效率不高;
- 32位环境下,实际定义bool类型变量(实际1bit就够了)都是用int来实现bool的,也就是说我们定义一个bool时,编译器实际帮我们分配了32位的内存来存储这个bool变量。编译器这么做浪费了31位的内存,但是好处是效率高;
- 编程时以省内存为主还是重效率? 内存很小时以省内存为主,但是现在写程序一般以效率为主;
内存对齐:
- 在C程序中:int a;为a分配4个字节,有两种分配方式:
- 第一种:0 1 2 3; 对齐访问
- 第二种:1 2 3 4或 3 4 5 6 非对齐访问;
- 内存对齐访问不是逻辑问题,而是硬件问题,从硬件角度来说,32位的内存“0 1 2 3”四个单元本身逻辑上就有相关性,四个字节组合作为一个int,硬件上就是合适的,所以效率高,非对齐方式和硬件本省不搭,所以访问效率低(一般硬件也支持非对齐访问,但效率很低);
从内存编址看数组的意义:
C语言如何操作内存
C语言对内存地址的封装:
- 用变量名访问内存、数据类型的含义、函数名的含义;如:int a;a=5;a+=4; //a==4;
- 定义一个变量a;编译器把变量和这个地址绑定,将变量的值放到地址空间中;读取内存单元中的值,然后+4,然后再放入地址空间;
- C语言中数据类型的本质含义:表示一个内存格子的长度和解析方法;
- 数据类型决定长度的含义:我们一个内存地址(0x30000000),本来这个地址只代表1个字节的长度,但是实际上我们可以通过给他一个类型(int),让他有了长度(4),这样这个代表内存地址的数字(0x30000000)就能表示从这个数字(0x30000000)开头的连续的n(4)个字节的内存格子了(0x30000000 + x30000001 + 0x30000002 + 0x30000003)。
- 数据类型决定解析方法的含义:譬如我有一个内存地址(0x30000000),我们可以通过给这个内存地址不同的类型来指定这个内存单元格子中二进制数的解析方法。譬如我 (int)0x30000000,含义就是(0x30000000 + 0x30000001 + 0x30000002 + 0x30000003)这4个字节连起来共同存储的是一个int型数据;那么我(float)0x30000000,含义就是(0x30000000 + 0x30000001 + 0x30000002 + 0x30000003)这4个字节连起来共同存储的是一个float型数据;之前讲过一个很重要的概念:内存单元格子的编址单位是字节。
- (int *)0; //表示将0转换成int型指针
- (float *)0;
- (short)0; //表示将数字0转换成short型
- (char)0;
- int a; // int a;时编译器会自动给a分配一个内存地址,譬如说是0x12345678
- (int *)a; // 等价于(int *)0x12345678
- (float *)a;
用指针来间接访问内存:
- 关于指针类型(不管是普通类型int 、float...,还是指针类型 int * 、float * ...)只要记住:类型只是对数字或符号(代表的是内存)所表征的一种长度规定和解析方法的规定;
- 指针变量和普通变量没什么区别,如int a,int *p,都是代表一个地址(譬如是0x20000000),但是内存地址0x20000000的长度和解析方法不同,a是int型所以a的长度是4字节,解析方法是按照int的规定来的;p是int *类型,所以长度是4字节,解析方法是int *的规定来的(0x20000000开头的连续4字节中存储了1个地址,这个地址所代表的内存单元中存放的是一个int类型的数)。
指针类型的含义:
- 指针变量和普通变量没什么区别,如int a,int *p,都是代表一个地址(譬如是0x20000000),但是内存地址0x20000000的长度和解析方法不同,a是int型所以a的长度是4字节,解析方法是按照int的规定来的;p是int *类型,所以长度是4字节,解析方法是int *的规定来的(0x20000000开头的连续4字节中存储了1个地址,这个地址所代表的内存单元中存放的是一个int类型的数)。
用数组来管理内存:
- 数组管理内存和变量没什么本质区别,只是符号的解析方法不同。(普通变量、数组、指针变量其实没什么差别,都是对内存地址的解析,只是解析方法不一样)。
- int a; // 编译器分配4字节长度给a,并且把首地址和符号a绑定起来。
- int b[10]; // 编译器分配40个字节长度给b,并且把首元素首地址和符号b绑定起来。
- 数组中第一个元素(a[0])就称为首元素;每一个元素类型都是int,所以长度都是4,其中第一个字节的地址就称为首地址;首元素a[0]的首地址就称为首元素首地址。
内存管理之结构体
数据结构的意义:
- 研究数组如何组织
最简单的数据结构:数组
- 为什么要有数组?因为程序中有好多个类型相同、意义相关的变量需要管理,这时候如果用单独的变量来做程序看起来比较乱,用数组来管理会更好管理。 譬如 int ages[20];
数组的优势和缺陷:
- 优势:数组简单,使用下标进行随机访问;
- 缺陷:①数组中所有元素的数据类型必须相同;②数据的大小必须在定义时给出,而一旦确定就不能更改;
结构体:
- 结构体的出现是为了解决数据的缺陷①;
- //定义3个学生的年龄
- //方法一:
- int age[3];
- //方法二:
- struct ages {
- int age1;
- int age2;
- int age3;
- };
- //相比之下使用数组更简单;
- //定义1个学生的身高、姓名、年龄
- //就必须使用结构体,因为身高、姓名、年龄不是同一个类型
- struct stu {
- int age;
- float name;
- float height;
- };
- 数组和结构体的本质差异在于对内存的管理方式;(数组是一种特殊的结构体)
题外:结构体内嵌指针实现面向对象:
- 总体来说,C语言是面向过程的,但C语言写出的linux系统是面向对象的,非面向对象的语言同能但写出面向对象的代码,但没有面向对象的语言来的直接;
- 使用C语言写的linux内核代码能实现面向对象,主要是在结构体中内嵌指针来实现的:
- struct stu
- {
- int age; // 普通变量
- void (*pFunc)(void); // 函数指针,指向 void func(void)这类的函数
- };
- 使用这样的结构体就能实现面向对象
- 这种包含函数指针的结构体就类似面向对象中的class,结构体中的变量就类似于class中的成员变量,结构体中的指针就类似于class中的成员方法;
内存管理之栈(stack)
什么是栈:
- 栈是一种数据结构,C语言中使用栈来保存局部变量。栈是用来内存管理的
栈管理内存的特点:
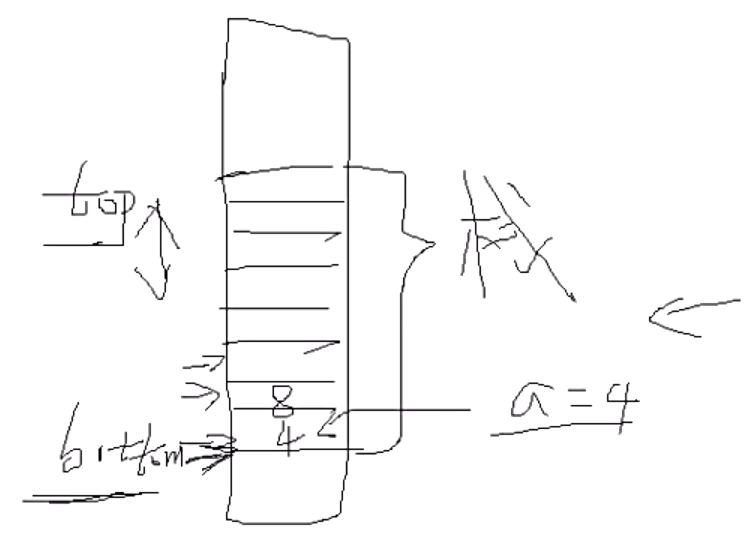
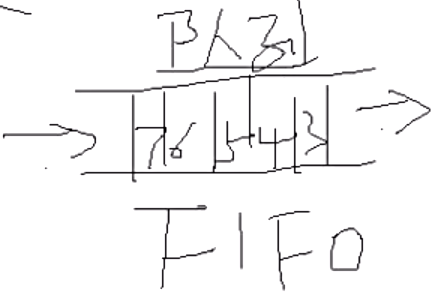
- bottom指针在最低,不能移动,top指针在上层,能自由移动;
- 先进后出FILO (fast in last out) 栈
- 先进先出FIFO (fast in fast out) 队列
- 栈的特点是只有入口即出口,另一个口是堵死的。所以先进去的必须后出来。
- 队列的特点是入口和出口都有,必须从入口进去,从出口出来,所以先进去的必须先出来,否则就堵住后面的。
栈的应用举例:局部变量
- C语言中的局部变量使用栈来实现的;
- 我们在C中定义一个局部变量(int a;)时,编译器会在栈中分配一段空间(4字节)给这个局部变量用(分配时栈顶指针会移动给出空间,给局部变量a用的意思就是,将这4字节的栈内存的内存地址和我们定义的局部变量名a给关联起来),对应栈的操作是入栈。
- 注意:这里栈指针的移动和内存分配是自动的(栈自己完成,不用我们写代码去操作)。
- 然后等我们函数退出的时候,局部变量要灭亡。对应栈的操作是弹栈(出栈)。出栈时也是栈顶指针移动将栈空间中与a关联的那4个字节空间释放。这个动作也是自动的,也不用人写代码干预。
栈的优点:
- 栈管理内存,好处是方便,分配和最后回收都不用程序员操心,C语言自动完成。
- 分析一个细节:C语言中,定义局部变量时如果未初始化,则值是随机的,为什么?
- 定义局部变量,其实就是在栈中通过移动栈指针来给程序提供一个内存空间和这个局部变量名绑定。因为这段内存空间在栈上,而栈内存是反复使用的(脏的,上次用完没清零的),所以说使用栈来实现的局部变量定义时如果不显式初始化,值就是脏的。如果你显式初始化怎么样?
- C语言是通过一个小手段来实现局部变量的初始化的。
- int a = 15; // 局部变量定义时初始化
- C语言编译器会自动把这行转成:
- int a; // 局部变量定义
- a = 15; // 普通的赋值语句
栈的约束:
- 栈是有大小的,所以栈内存大小不好设置。如果太小怕溢出,太大怕浪费内存。(缺点优点像数组);
- 栈的溢出危害很大,一定要避免(C语言本身不会检测栈是否溢出),所以在C语言中定义局部变量时,不能定义太大或者太小,(譬如不能定义局部变量时 int a[10000];使用递归来解决问题时,一定要注意递归收敛);
内存管理之堆:(heap)
什么是堆:
- 堆(heap)是一种内存管理方式。内存管理对操作系统来说是一件非常复杂的事情,因为首先内存容量很大,其次内存需求在时间和大小块上没有规律(操作系统上运行着的几十、几百、几千个进程随时都会申请或者释放内存,申请或者释放的内存块大小随意)。
- 堆这种内存管理方式特点就是自由(随时申请、释放;大小块随意)。堆内存是操作系统划归给堆管理器(操作系统中的一段代码,属于操作系统的内存管理单元)来管理的,然后向使用者(用户进程)提供API(malloc、free)来使用堆内存。
- 我们什么时候使用堆内存? 需要内存容量比较大时;需要反复使用及释放时;很多数据结构(譬如链表)的实现都要使用堆内存。
堆管理内存的特点:
- 容量不限(常规使用的需求容量都能满足);
- 申请及释放都需要手工进行,程序员需写代码明确进行申请malloc及释放free。如果程序员未及时申请内存并使用后释放,这段内存就丢失了,称为内存泄漏。在C/C++语言中,内存泄漏是最严重的程序bug,这也是别人认为Java/C#等语言比C/C++优秀的地方。
C语言操作堆内存的接口:(malloc、free)
- 堆内存释放最简单,直接调用free释放即可。原型为:void free(void *ptr);
- 堆内存申请时,有3个可选择的类似功能的函数:malloc、calloc、realloc;原型分别为:
- void *malloc(size_t size);
- void *calloc(size_t nmemb, size_t size); // nmemb个单元,每个单元size字节
- void *realloc(void *ptr, size_t size); // 改变原来申请的空间的大小的
- 譬如申请10个int元素的内存:
- //使用后者更好,有利于不同平台的程序移植
- malloc(40); (int *)malloc(10*sizeof(int));
- calloc(10,4); (int *)calloc(10,sizeof(int));
- 数组定义时,必须同时给出数组元素个数(数组大小),而且一旦定义再无法修改。在Java等高级语言中,有一些语法技巧可以更改数组大小,但其实这只是一种障眼法。它的工作原理是:先重新创建一个新的数组大小为要更改后的数组,然后将原数组的所有元素复制进新的数组,然后释放掉原数组,最后返回新的数组给用户;
- 堆内存申请时必须给定大小,一旦申请完成大小不能该更,如果要改变,只能调用接口函数 realloc。realloc的实现原理类似于上面说的Java中的可变大小的数组的方式。
堆的优势和劣势;(管理大块内存、灵活、容易内存泄漏)
- 优势:灵活;
- 劣势:需要程序员去处理各种细节,所以容易出错,严重依赖于程序员的水平;
复杂数据结构
链表:
- 嵌入式领域中,链表是最重要的,链表在linux内核中使用非常多,驱动、应用编写很多时候都需要使用链表。所以链表必须掌握。掌握到:会自己定义结构体来实现链表、会写链表的节点插入(前插、后插)、节点删除、节点查找、节点遍历等。(至于像逆序这些很少用,掌握了前面那几个这个也不难)。
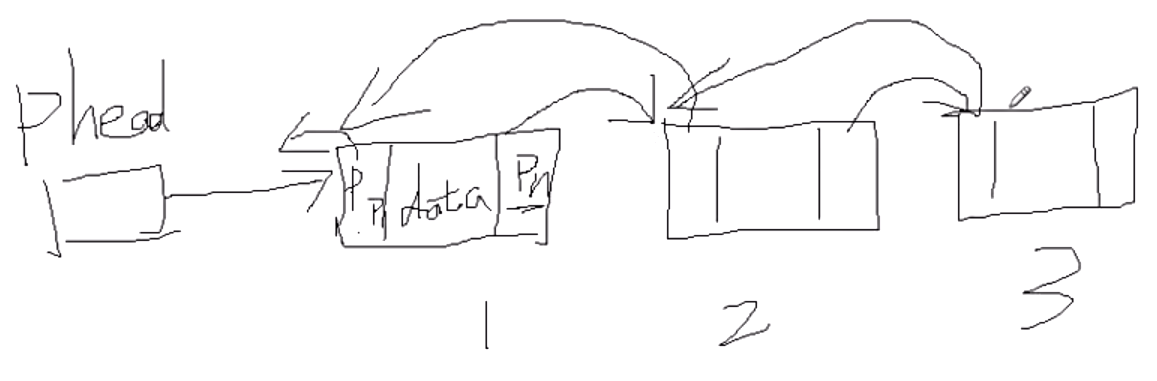
哈希表:
- 哈希表不是很常用,一般不需要自己写实现,而直接使用别人实现的哈希表比较多。对我们来说最重要的是要明白哈希表的原理、从而知道哈希表的特点,从而知道什么时候该用哈希表,当看到别人用了哈希表的时候要明白别人为什么要用哈希表、合适不合适?有没有更好的选择? (哈希表和数组的区别:数组的下标是依次排列的,而哈希表的下标是乱序的,是通过一定的公式计算得到的,可以将其看作是由数组映射得到的。)

二叉树、图等:
- 二叉树、图等。对于这些复杂数据结构,不要太当回事。这些复杂数据结构用到的概率很小(在嵌入式开发中),其实这些数据结构被发明出来就是为了解决特定问题的,你不处理特定问题根本用不到这些,没必要去研究。
为什么需要更复杂的数据结构:
- 因为现实中的实际问题是多种多样的,问题的复杂度不同,所以需要解决问题的算法和数据结构也不同。所以当你处理什么复杂度的问题,就去研究针对性解决的数据结构和算法;当你没有遇到此类问题(或者你工作的领域根本跟这个就没关系)时就不要去管了。
数据结构和算法的关系:
- 数据结构的发明都是为了配合一定的算法;算法是为了处理具体问题,算法的实现依赖于相应的数据结构;
- 当前我们说的算法和纯数学是不同的(算法是基于数学的,大学计算机系研究生博士生很多本科都是数学相关专业的),因为计算机算法要求以数学算法为指导,并且结合计算机本身的特点来改进,最终实现一个在计算机上可以运行的算法(意思就是用代码可以表示的算法)。
应该怎样学习:
- 数据结构和算法是相辅相成的,要一起研究;
- 数据结构和算法对于嵌入式来说不全是重点,不要盲目的去研究这个;
- 一般在实际应用中,实现数据结构与算法的人和使用数据结构与算法的人是分开的。实际中有一部分人的工作就是研究数据结构和算法,并且试图用代码来实现这些算法(表现为库);其他做真正工作的人要做的就是理解、明白这些算法和数据结构的意义、优劣、特征,然后在合适的时候选择合适的数据结构和算法来解决自己碰到的实际问题。
- 举个例子:linux内核在字符设备驱动管理时,使用了哈希表(hash table,散列表)。所以字符设备驱动的很多特点都和哈希表的特点有关。