继承
继承的语法
class Animal(object):
def __init__(self,name):
self.__name = name
class Dog(Animal):
kind = "Dog"
def __init__(self,name,age):
super.__init__(self,name)
self.__age = age
可以看出,定义类时后面圆括号里的就是父类(基类),如果有多个父类或者
metaclass时,用逗号隔开。只要子类成员有与父类成员同名,默认覆盖父类成员的,类似Java中的方法重写(@override)。
super详解
说到 super(), 大家可能觉得很简单呀,不就是用来调用父类方法的嘛。如果真的这么简单的话也就不会单独拿出来说了
单继承
在单继承中super()就像大家所想的那样,主要是用来调用父类的方法的
class A:
def __init__(self):
self.n = 2
def add(self, m):
print(f'self is {self} @A.add')
self.n += m
def __str__(self):
return "instance of A"
class B(A):
def __init__(self):
self.n = 3
def __str__(self):
return "instance of B"
def add(self, m):
print(f'self is {self} @B.add')
super().add(m)
self.n += 3
你觉得执行下面代码后, b.n 的值是多少呢?
b = B()
b.add(2)
print(b.n)
执行结果如下:
self is instance of B @B.add
self is instance of B @A.add
8
这个结果说明了两个问题:
super().add(m)确实调用了父类 A 的add方法super().add(m)调用父类方法def add(self, m)时, 此时父类中self并不是父类的实例而是子类的实例, 所以b.add(2)之后的结果是5而不是4
多继承
这次我们再定义一个 class C,一个 class D:
class C(A):
def __init__(self):
self.n = 4
def __str__(self):
return "instance of C"
def add(self, m):
print(f'self is {self} @C.add')
super().add(m)
self.n += 4
class D(B, C):
def __init__(self):
self.n = 5
def __str__(self):
return "instance of D"
def add(self, m):
print(f'self is {self} @D.add')
super().add(m)
self.n += 5
下面的代码又输出啥呢?
d = D()
d.add(2)
print(d.n)
这次的输出如下:
self is instance of D @D.add
self is instance of D @B.add
self is instance of D @C.add
self is instance of D @A.add
19
为什么是这么样的顺序?继续往下看!
super是个类
当我们调用super()的时候,实际上是实例化了一个super类。你没看错, super 是个类,既不是关键字也不是函数等其他数据结构
>>> class A:
pass
>>> s = super(A)
>>> type(s)
<class 'super'>
在大多数情况下, super 包含了两个非常重要的信息: 一个 MRO 以及 MRO 中的一个类
- 当以如下方式调用
super时:
super(a_type, obj)并且isinstance(obj, a_type) = True
MRO 指的是 type(obj) 的 MRO, MRO 中的那个类就是 a_type - 当这样调用时:
super(type1, type2)并且issubclass(type2, type1) = True
MRO 指的是 type2 的 MRO, MRO 中的那个类就是 type1
那么,super(arg1, arg2).func()实际上做了啥呢?简单来说就是:
根据arg2得到MRO列表,然后,查找arg1在MRO列表的位置,假设为pos,然后从pos+1开始查找,找到第一个有func()的类,执行该类的func()
虽然
super无返回值,但可以认为,它返回值类型和arg2同类型
MRO(Method Resolution Order)——方法解析顺序
可以通过类名.mro()方法查找出来当前类的调用顺序,其顺序由C3线性算法来决定,保证每一个类只调用一次,下面举个例子就能看懂了:
MRO的C3算法计算过程——计算G的MRO列表
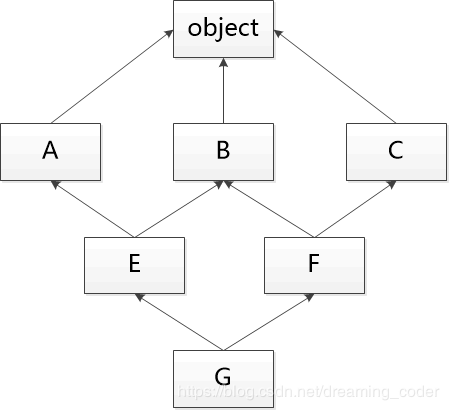
C3算法核心操作是merge,也就是按照类似拓扑排序的方法,把多组mro列表合并。
为简单表示,将object写成O
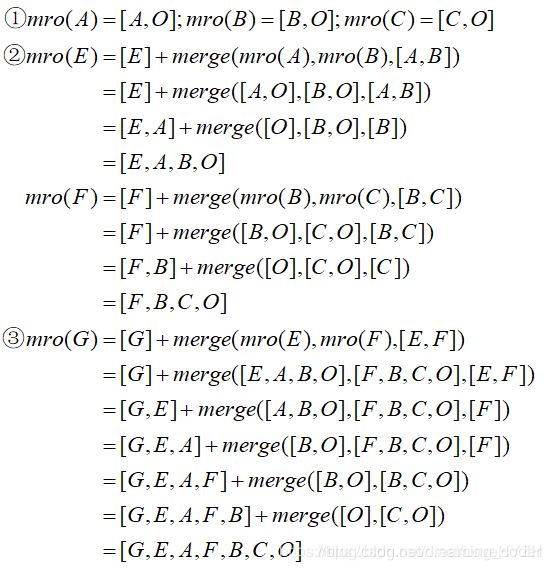
C3线性算法的实现
import abc
def mro(cls) -> list:
if type(cls) == type(object) or type(cls) == type(abc.ABC):
# object是最顶层类,如果传入的是object,那么就是[object]
if issubclass(object,cls):
return [cls]
else:
bases = cls.__bases__
return __merge(cls, *[mro(x) for x in bases], list(bases))
else:
raise TypeError("mro()方法需要一个位置参数cls,类型为class")
def __merge(*args)->list:
result = [args[0]]
operation_list = list(args[1:])
"""
any()函数:
Return True if bool(x) is True for any x in the iterable.
If the iterable is empty, return False.
"""
while any(operation_list):
# 将空的列表删除,因为有可能传进来的是[[],[],['object']]
while [] in operation_list:
operation_list.remove([])
# 拓扑序列中的每个元素(类名列表)
for y in operation_list:
temp = y[0]
need = True
for t in operation_list:
if temp in t and t.index(temp) > 0:
need = False
break
if need:
break;
# 将这个元素添加到结果列表
result.append(temp)
# 拓扑排序的列表中删除这个元素节点
for p in operation_list:
while temp in p:
p.remove(temp)
else:
return result
抽象类
与java一样,python也有抽象类的概念,但是同样需要借助模块实现。
抽象类是一个特殊的类,它的特殊之处在于只能被继承,不能被实例化。如果一个抽象基类要求实现指定的方法,而子类没有实现的话,当试图创建子类或者执行子类代码时会抛出异常。
Python中,定义抽象类需要借助abc模块,abc模块提供了一个使用某个抽象基类声明协议的机制,并且子类一定要提供了一个符合该协议的实现。
from abc import ABC
import abc
# class Animal(metaclass=abc.ABCMeta):
class Animal(ABC):
@abc.abstractmethod
def test(cls):
pass
@abc.abstractmethod
def bark(self):
pass
class Dog(Animal):
# 子类需要实现抽象方法,否则报错
def bark(self):
print("汪汪汪...")
@classmethod
def test(cls):
print("Dog的test")
class Cat(Animal):
def bark(self):
print("喵喵喵...")
def test(self):
print("Cat的test")
# a = Animal() # 抽象类不能实例化
d = Dog()
d.bark()
Dog.test()
c = Cat()
c.bark()
c.test()
- 必须导入
abc模块- 抽象方法用装饰器
@abc.abstractmethod,子类实现时才能确认是实例方法、类方法还是静态方法- 抽象类,要么继承
ABC类;要么不写父类,写metaclass=ABCMeta,由元类ABCMeta创建
枚举类
例如星期、月份这些类型,它们的值是公认的,不会随意更改,所以可以事先将这些值都定义出来,用的时候直接拿过来用,这就是枚举类和枚举类型,最主要的一点是穷尽,枚举类型必须是一个枚举类的所有可能结果。这些枚举类型都是只创建一次对象的,每个人要用都是用一样的对象,是不可变的。
from enum import Enum, unique
# 创建月份的枚举类
# 枚举类中的每个属性值,默认是从1开始递增的整数
# 如果指定了一个属性的值,它后面的属性则会从该值开始递增
# PS:下面这个就是个构造方法,Enum就是个类
Month = Enum('Month',('Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun',
'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'))
# 如果想自定义属性的值可以这么写,继承Enum类
# unique装饰器可以帮助我们检查,保证没有重复值
@unique
class WeekDay(Enum):
Sun = 0 # Sun的value被设定为0
Mon = 1
Tue = 2
Wed = 3
Thu = 4
Fri = 5
Sat = 6
# 访问枚举类型的值
print(WeekDay.Mon) # WeekDay.Mon
print(WeekDay['Tue']) # WeekDay.Tue
print(WeekDay.Wed.name) # Wed
print(WeekDay.Wed.value) # 3
print(WeekDay(4)) # WeekDay.Thu
反射
在程序开发中,常常会遇到这样的需求:在执行对象中的某个方法,或者在调用对象的某个变量,但是由于一些原因,我们无法确定或者并不知道该方法或者变量是否存在,这时我们需要一个特殊的方法或者机制来访问或操作该未知的方法或变量,这种机制就被称之为反射。
反射机制:反射就是通过字符串的形式,导入模块;通过字符串的形式,去模块中寻找指定函数,对其进行操作。也就是利用字符串的形式去对象(模块)中操作(查找or获取or删除or添加)成员,一种基于字符串的事件驱动。
下面介绍反射机制的四个方法:
hasattr()函数
语法:hasattr(object, name)
功能:判断object中是否有属性或者方法name,其中object可以是对象、可以是类、可以是模块名,存在返回True,不存在返回False。getattr()函数
语法:getattr(object, name, default=None)
功能:返回object的name属性(或方法),不存在则看default有没有传,没有就会报错,传了的话返回default值作为属性(或方法)不存在的返回值。setattr()函数
语法:setattr(object,name,value)
功能:动态给属性赋值,如果属性不存在,则先创建属性再赋值,另外,这是运行时修改,不会影响文件代码的内容。delattr()函数
语法:delattr(object,name)
功能:删除object的name属性,,属性不存在则报错。
import functools
class Student(object):
std_no = 1001
def __init__(self,name):
self.name =name
def f(self,string):
print(string)
s = Student("芜情")
print(hasattr(functools,"reduce")) # True
print(hasattr(Student,"std_no")) # True
print(hasattr(Student,"f")) # True
print(hasattr(s,"name")) # True
print(getattr(Student,"name","None")) # None
getattr(Student,"f","None")(s,"WCG") # WCG
setattr(Student,"sex","male")
print(getattr(s,"sex","None")) # male
setattr(Student,"f",functools.reduce)
print(getattr(s,"f")) # <built-in function reduce>
setattr(Student,"sex","male")
print(getattr(s,"sex","None")) # male
setattr(Student,"f",functools.reduce)
print(getattr(s,"f")) # <built-in function reduce>
delattr(Student,"std_no")
print(getattr(Student,"std_no","None")) # None
delattr(Student,"f")
print(getattr(Student,"f","None")) # None
dataclass数据类
dataclass装饰器
语法:
dataclass(*, init = True, repr = True, eq = True, order = False, unsafe_hash = False, frozen = False)
参数含义
- init:默认True,则自动生成__init__()方法
- repr:默认True,则自动生成__repr__()方法,格式为类名和各参数名以及参数值
- eq:默认True,自动生成__eq__()方法,此方法按顺序比较属性的元组
- order:默认False,如果为True,则自动生成__lt__()、__le__()、__g__t()、__ge__()方法
- unsafe_hash:暂且不管,和hash值有关,一般遇不到
- frozen:默认False,如果为True,则禁止更改属性值(类似Java中的final)
示例
首先,要知道下面三种写法是等价的
@dataclass
@dataclass()
@dataclass(init=True, repr=True, eq=True, order=False, unsafe_hash=False, frozen=False)
下面给出具体例子
from dataclass import dataclass
@dataclass(order=True)
class Student(object):
name:str
age:int = 18
s = Student("yee",16)
t = Student("sky")
print(s) # Student(name='yee', age=16)
print(s==t) # False
print(s>t) # True
t.name = "疾风剑豪" # frozen=True时,此方法报错
print(t) # Student(name='疾风剑豪', age=18)
__post_init__
有些操作需要在初始化后进行,如分离浮点数的整数部分和小数部分:
from dataclasses import dataclass,field
import math
@dataclass
class FloatNumber:
val: float = 0.0
def __post_init__(self): # 方法签名固定,不能改
self.decimal, self.integer = math.modf(self.val)
a = FloatNumber(2.2)
print(a) # FloatNumber(val=2.2)
print(a.val) # 2.2
print(a.integer) # 2.0
print(a.decimal) # 0.20000000000000018
field函数
语法:
field(*, default=MISSING, default_factory=MISSING,
init=True,repr=True,hash=None,
compare=True,metadata=None):
MISSING代表类体只有pass语句的类
参数含义
- default:如果提供,这将是此字段的默认值。这是必需的,因为field()调用本身取代了默认值的正常位置
- default_factory:如果提供,它必须是零参数可调用,当此字段需要默认值时将调用该调用,default_factory不能和default同时出现
- init:如果为true(默认值),则此字段作为参数包含在生成的__init__()方法中
- repr:如果为true(默认值),则此字段包含在生成的__repr__()方法返回的字符串中
- hash:一般不用
- compare:如果为真(默认值),则该字段被包括在所产生的==和比较方法
- metadata:这是给第三方的API,我们用不到
示例
from dataclasses import dataclass,field
@dataclass
class Student(object):
Chinese:float
Maths:float
English:float
total:float = field(init=False)
def __post_init__(self):
self.total = self.Chinese + self.Maths + self.English
s = Student(98,99,95)
print(s) # Student(Chinese=98, Maths=99, English=95, total=292)
继承问题
这里继承和一般的继承一样,子类会继承父类的属性和方法,按照MRO列表的顺序,查找所调用的函数和属性,都找不到则报错。