kafka基本概念:
-
Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。无论是kafka集群,还是consumer都依赖于zookeeper集群保存一些meta信息,来保证系统高可用性。
-
batch机制和request机制解决频繁网络通信带来的性能低下问题;
-
ACK应答机制解决消息一定能够被消费到,就算传输过程中出现故障,只要消息到达了kafka,就会被保存到offset中,方便恢复数据;
-
每个主题topic可以有多个分区;kafka将分区均匀地分配到整个集群中,提高吞吐量;
-
顺序读写:kafka是个可持久化的日志服务,它将数据以数据日志的形式进行追加,最后持久化在磁盘中。利用了磁盘的顺序读写,来提高读写效率。时间复杂度为O(1)。
kafka的缺点:
-
部署集群的话,至少需要6台服务器,3台zookeeper(kafka的topic和consumer依赖于zookeeper);
-
复杂性:Kafka依赖Zookeeper进行元数据管理,Topic一般需要人工创建,部署和维护比一般MQ成本更高;
-
消息乱序。Kafka某一个固定的Partition内部的消息是保证有序的,如果一个Topic有多个Partition,partition之间的消息送达不保证有序。
-
监控不完善,需要安装插件;(rabbitmq自带可视化监控web界面,能够清晰的看到各种参数.)
kafka和其它消息中间件的优缺点见链接: https://www.cnblogs.com/mengchunchen/p/9999774.html
kafka性能基准测试见链接:http://www.cnblogs.com/xiaodf/p/6023531.html
kafka安装及配置:
kafka安装及配置见链接: https://www.cnblogs.com/RUReady/p/6479464.html
kafka实战demo:导入pom依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>0.11.0.0</version>
</dependency>
-
创建生产者:
package com.byavs.kafka.produce;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class CustomProducer {
public static void main(String[] args) {
Properties props = new Properties();
// Kafka服务端的主机名和端口号
props.put("bootstrap.servers", "47.98.63.22:9092");
// 等待所有副本节点的应答
props.put("acks", "all");
// 消息发送最大尝试次数
props.put("retries", 0);
// 一批消息处理大小
props.put("batch.size", 16384);
// 请求延时
props.put("linger.ms", 1);
// 发送缓存区内存大小
props.put("buffer.memory", 33554432);
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 50; i++) {
producer.send(new ProducerRecord<String, String>("first", Integer.toString(i), "hello world-" + i))
}
producer.close();
}
}-
创建消费者:
-
package com.byavs.kafka.consume;
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class CustomNewConsumer {
public static void main(String[] args) {
Properties props = new Properties();
// 定义kakfa 服务的地址,不需要将所有broker指定上
props.put("bootstrap.servers", "47.98.63.22:9092");
// 制定consumer group
props.put("group.id", "test");
// 是否自动确认offset
props.put("enable.auto.commit", "true");
// 自动确认offset的时间间隔
props.put("auto.commit.interval.ms", "1000");
// key的序列化类
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// value的序列化类
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 定义consumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 消费者订阅的topic, 可同时订阅多个
consumer.subscribe(Arrays.asList("first", "second","third"));
while (true) {
// 读取数据,读取超时时间为100ms
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
spring也提供了一套对kafka操作的API,更加方便.
-
导入pom依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
-
application.yml配置
spring
主配置类加注解@EnableKafka
3. 生产者消费者代码:
消息队列内部实现原理:

kafka架构:
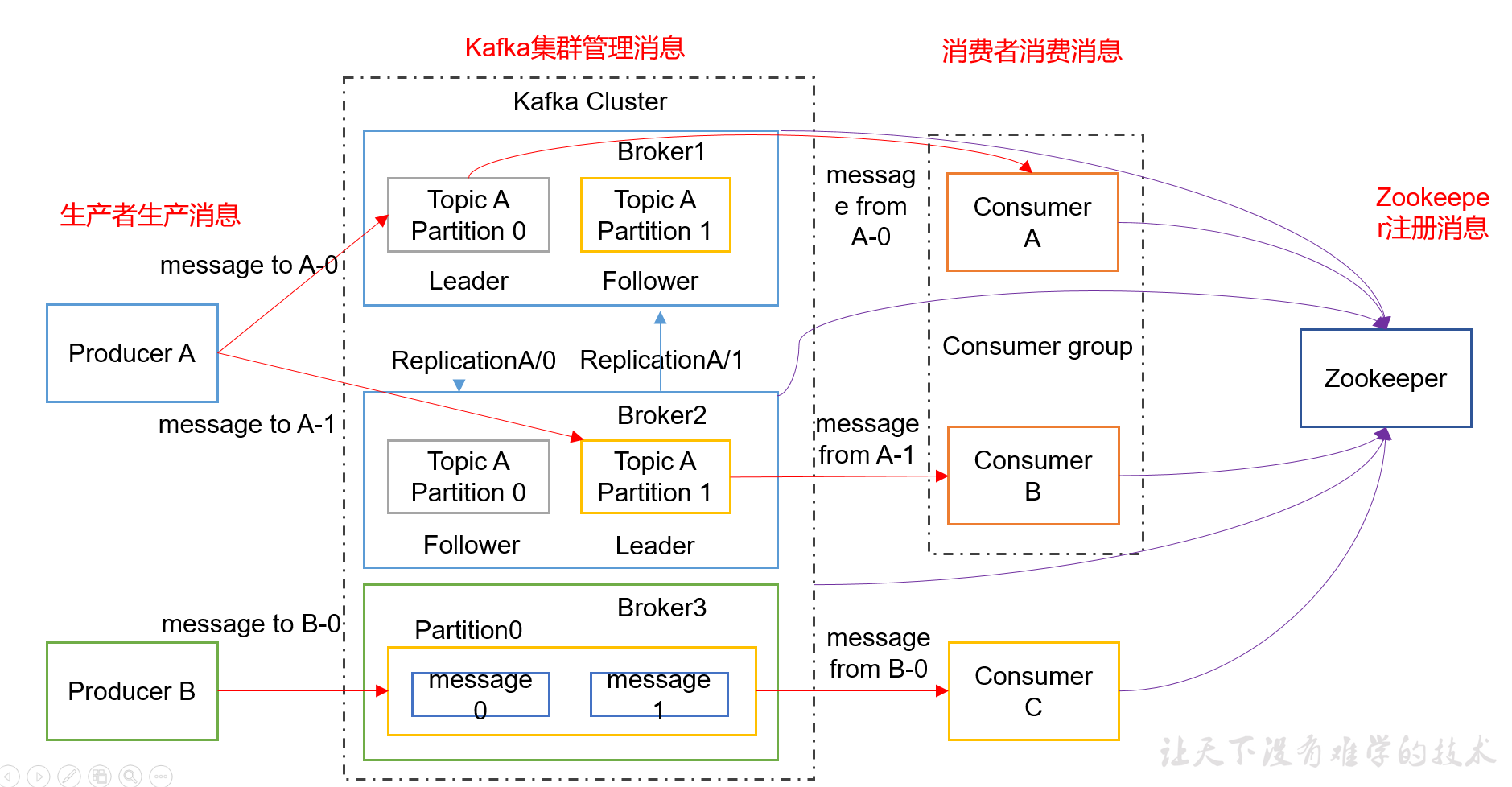
各名词解释:
1)Producer :消息生产者,就是向kafka broker发消息的客户端;
2)Consumer :消息消费者,向kafka broker取消息的客户端;
3)Topic :可以理解为一个队列;
4) Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic;
5)Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic;
6)Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序;