元字符:
-
-
[] [^] . ^ $
-
()分组 |
量词
-
? + *
-
{n} {n,m} {n,}
贪婪:
默认贪婪
非贪婪:.
*?x
二、今日内容
-
re模块
-
findall
#findall
ret = re.findall('d+',"dkfjaklldlja123jdklflaj123")
print(ret) -
search :用来寻找这个字符号中是否有满足条件的内容
#search
ret = re.search('d+','dfdklajddfklaj123jkllsdldljfsd343')
print(ret)
print(ret.group())
print(ret.group(1)) -
split 按照切割
#spilt
s = "dfahkj12fhja45fdasfda"
ret = re.split('d+',s)
print(ret) -
sub :替换方法 返回替换内容
#sub(正则表达式,替换内容,原字符串,替换个数)
ret = re.sub('d+','fd','123jfdks12fjdalks111lll12dfd')
print(ret)
-
subn :返回替换的内容及替换次数
ret = re.subn('d+','fd','123jfdks12fjdalks111lll12dfd')
print(ret) #('fdjfdksfdfjdalksfdlllfddfd', 4) -
match :
-
判断以什么正则开头,通过.group取值,相当于在正则前面添加 ^符号
-
用来规定这个字符号必须是什么样的
# match
ret = re.match('d+','123jfdks12fjdalks111lll12dfd')
print(ret) #<_sre.SRE_Match object; span=(0, 3), match='123'>
print(ret.group()) #123
-
-
compile :重要** 节省时间
-
同一个正则表达式被多次使用,可以使用comile对正则表达式进行解析
ret = re.compile('d+')
res = ret.findall("djfkal12fjdsklld3fdsakj3fjdadl4jfd")
print(res)
res = ret.findall("fhdadkd23fhjkdas212")
print(res)
-
-
finditer : 重要** 节省空间
-
返回的是迭代器
ret = re.finditer('d+','dfdadhdkjd2j3hhcjkdas23jhkjh23h4jk2h')
for r in ret:
print(r) #<_sre.SRE_Match object; span=(10, 11), match='2'>
print(r.group())
-
-
先compile 在 finditer
ret = re.compile('d+')
res = ret.finditer('fjak32j423kj23j432lj42lklj432')
for i in res:
print(i.group()) -
列表的操作:不能用insert和pop
-
-
re模块拾遗
-
分组命名
(?P<rating_num>.*?)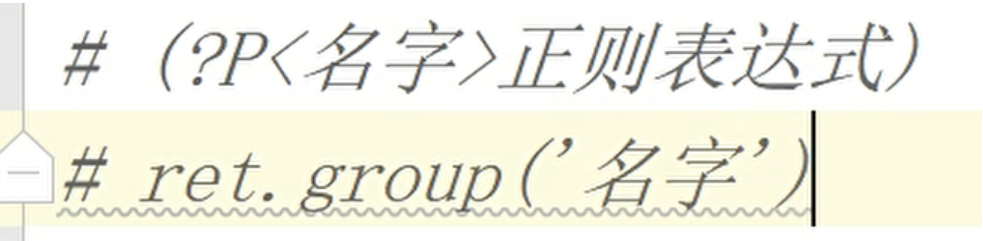
-
分组命名的应用

-
-
带参数的装饰器
import time
def show(path):
def warpper(func):
def inner(*args,**kwargs):
ret = func(*args,**kwargs)
start_time = time.strftime('%Y-%m-%d %H:%M:%S')
with open(path,encoding="utf-8",mode="a") as f1:
res = f'{start_time}:调用了函数名为{path} '
f1.write(res)
return ret
return inner
return warpper
-
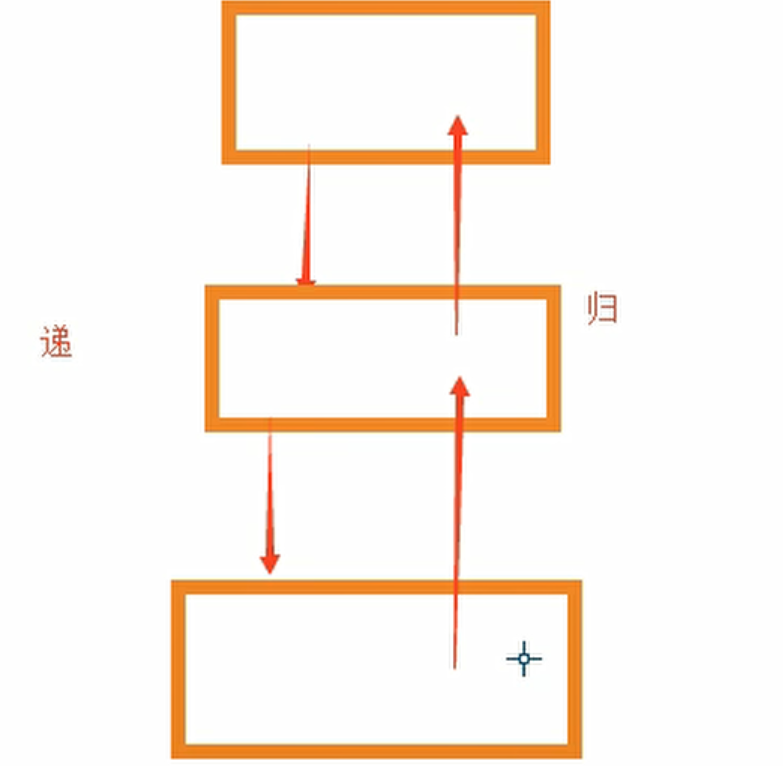
递归函数
-
递归的最大层数是 1000层,节省内存空间
-
递归要尽量控制次数,如果需要很多层递归才能解决问题,不适合用递归
-
循环和递归的关系
-
递归不是万能的
-
递归比起循环来说更占用内存
import sys
sys.setrecursionlimit(1000000)
#修改递归的最大深度
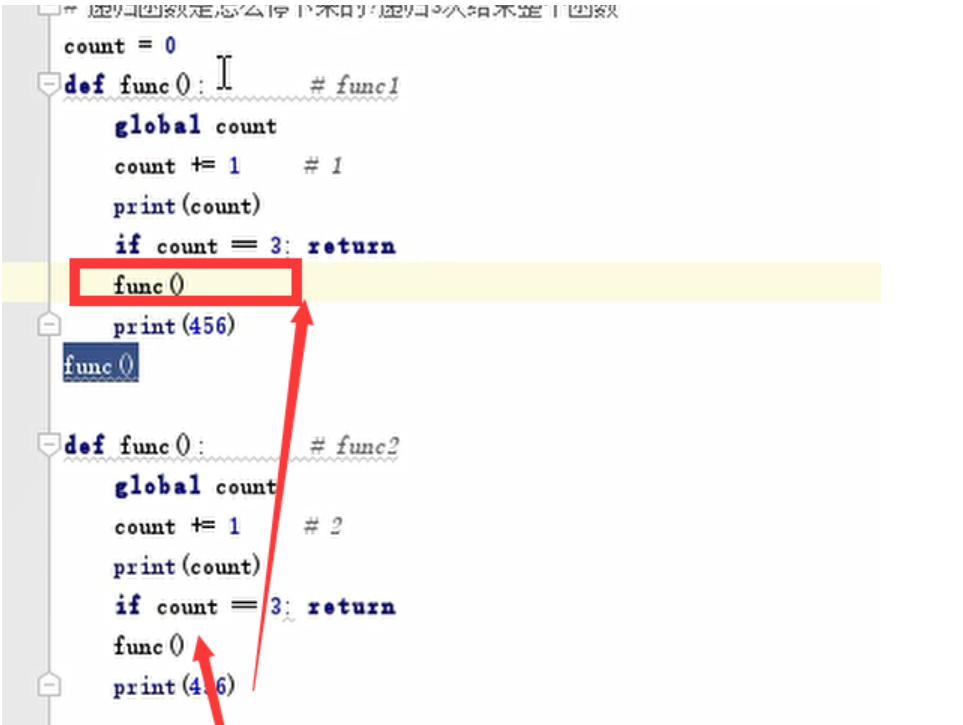
count = 0
def func():
global count
count += 1
print(count)
func()
print(3333)
func()
-
-
递归函数的停止
-
一个递归函数要结束,必须有一个return,且return的条件必须是一个可达到的

-
-