先前的示例讲过了如何自动在百度搜索并提取结果. 现在基于上次的脚本添加翻页的功能:
上次的脚本:
public void Run() { Default.Navigate("http://www.baidu.com"); Default.Ready(); Default.SelectSingleNode("#kw").Attr("value", "hello world!"); Default.SelectSingleNode("#su").Click(); Default.Reset(); Default.Ready(); var titles = Default.SelectNodes("h3.t"); foreach(var t in titles) { Logger.Log(t.Text()); } }
首先在页面选定"下一页"元素:
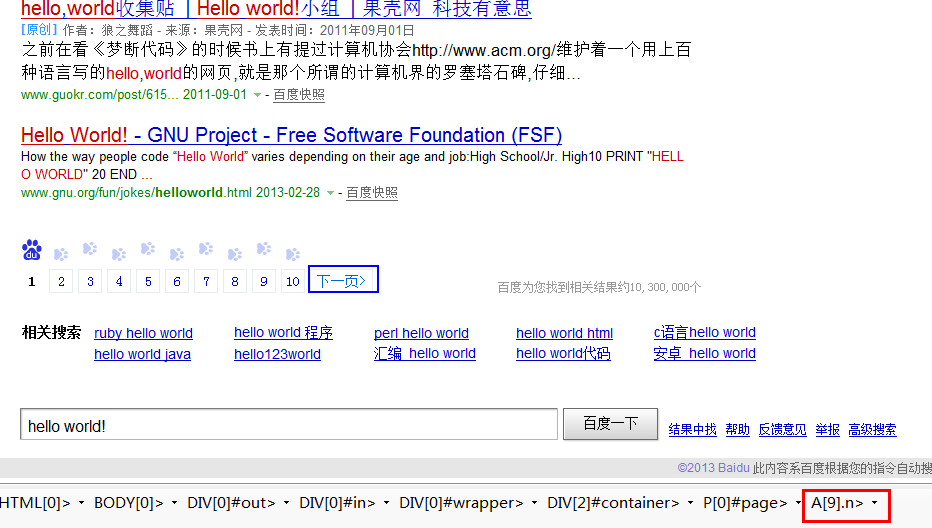
利用JQuery有多种方法获取这个节点:
Default.SelectSingleNode("#page a:last");
或者
Default.SelectSingleNode("a:contains("下一页")");
个人觉得第二种方式最可靠, 因为到最后一页时:last是能够匹配到节点的, 而contains("下一页")是匹配不到的, 因此更加能够反映正确情况.
现在来改写原有逻辑:
var titles = Default.SelectNodes("h3.t"); foreach(var t in titles) { Logger.Log(t.Text()); }
改为一个不停翻页的循环处理:
while(Default.Available) { var titles = Default.SelectNodes("h3.t"); foreach(var t in titles) { Logger.Log(t.Text()); } var next = Default.SelectSingleNode("a:contains("下一页")"); if(next.IsEmpty()) return; //如果没有下一页就退出 next.Click(); Default.Reset(); Default.Ready(); }
运行起来测试一下... 等... ok, 成功了, 从第一页开始一直翻到最后一页了, 所有搜索结果都正确提取出来了:

下面是完整的代码:
public void Run() { Default.Navigate("http://www.baidu.com"); Default.Ready(); Default.SelectSingleNode("#kw").Attr("value", "hello world!"); Default.SelectSingleNode("#su").Click(); Default.Reset(); Default.Ready(); while(Default.Available) { var titles = Default.SelectNodes("h3.t"); foreach(var t in titles) { Logger.Log(t.Text()); } var next = Default.SelectSingleNode("a:contains("下一页")"); if(next.IsEmpty()) return; //如果没有下一页就退出 next.Click(); Default.Reset(); Default.Ready(); } }