思维导图参考:
一。requests模块总结:
-requests模块: - UA伪装:反反爬策略 - get请求: requests.get(url,headers,params,proxies) - post请求: requests.post(data) - ajax的get,post请求: - 结论:页面中先关的数据可以是动态加载获取。 - 模拟登录: - 验证码:动态变化 - username,pwd,code - 云打码,打码兔 - cookie:服务器用来使用cookie记录客户端的相关状态。 - 手动处理: 将cookie添加到headers - 自动处理: 使用会话对象(requests.Session()) 会话对象可以向requests模块一样进行请求的发送。 - 代理: - 代理的类型: - http - https - requests.get(proxies={'http':'ip:port'})
二。selenium介绍
selenium:专门用来爬取网页中的动态加载的数据 - 基于浏览器自动化的一个模块 - 使用流程: - pip install selenium - 下载一个浏览器的驱动程序 - 实例化一个浏览器对象 - PhantomJs 无可视化界面的浏览器
三。scrapy 项目框架、
下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
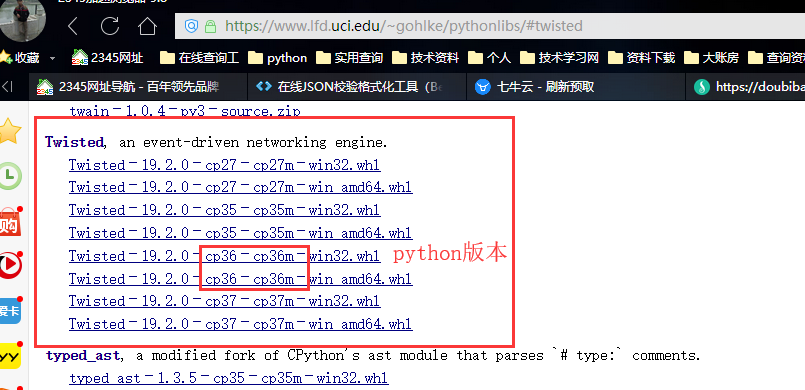
下载对应的版本要在cmd(管理员身份打开):pip3 install 软件文件名.whl
- 框架:项目模板(集成了很多功能,具有很强的通用) - 环境安装: a. pip3 install wheel # Twisted:异步的框架 b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted c. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl d. pip3 install pywin32 e. pip3 install scrapy - 使用: - 创建一个工程:scrapy startproject xxxPro - 创建一个爬虫文件(爬虫文件放置在spiders目录下): - cd xxxPro - scrapy genspider spiderName www.xxx.com - 执行工程: - scrapy crawl spiderName - 持久化存储: - 基于终端指令:scrapy crawl spiderName -o fileName.csv 特性:只可以将parse方法的返回值写入到磁盘文件(固定格式的文件)中。 - 基于管道: - piplelines:涉及持久化存储相关的操作都必须写在管道文件(类)中 - 编码流程: - 在爬虫文件中进行数据解析 - 将解析到的数据封装存储到item类型的对象 - 使用yield将item提交给管道 - 管道类中process_item负责接收item对象,负责将item进行持久化存储 - 在配置文件中开启管道 - 中间件(下载中间件) - 作用:批量拦截scrapy工程中所有的请求和响应 - 拦截请求: - 处理请求的UA - 处理请求的代理IP - process_request:拦截正常的请求对象 - process_response:拦截响应对象 - process_exception:拦截发生异常的请求 - 使用中间件设置请求的UA: - request.headers['User-Agent'] = 'xxx' - 设置代理: - request.meta['proxy'] = 'http://ip:port' - 请求传参: -使用场景:当请求/解析的数据不在同一张页面中的时候 - Request(url,callback,meta={xxx:xxx})meta就会传递给callback指定的方法 - 日志等级: - 在settings中进行如下配置:LOG_LEVEL = 'ERROR' LOG_FILE = './log.txt' - CrawlSpider: - 专门用户全栈数据解析 - 使用流程: - 创建工程 - 创建爬虫文件:scrapy genspider -t crawl SpiderName www.xxx.com - 增量式爬虫: - 检测网站数据更新的情况,只爬取最新更新出来的数据。 - 核心:去重