汇编中的伪指令(基于汇编编译器MASM讲解)
一丶什么是伪指令,以及作用
首先我们用汇编开发效率低,如何才能开发效率高,甚至开发速度比C语言或这个高级语言快
答案: 伪指令
什么是伪指令
伪指令是汇编编译器提供的,比如昨天我们写的汇编代码,假设调用一个Call我们每次都要手工处理
保存栈底,开辟就变量空间,保存寄存器环境....每次都要做,特别麻烦,所以编译器帮我们提供了伪指令,只要我们
按照汇编编译器的语法去写,那么这些汇编编译器则会自动帮我们补全
比如昨天的代码:
;调用开始,把参数压栈 mov ax,1 push ax mov bx,2 push bx CALL MY_ADD ...... MY_ADD: push bp ;保存栈底 mov bp,sp ;为了让bp去寻址,所以一开始放到栈顶的位置 sub sp,4 ;开辟四个局部变量控件 push cx ;保存一起寄存器的环境,函数内部使用cx,但是函数完成之后需要把以前CX的值回复 ....你的核心代码 pop cx ;恢复寄存器的环境 mov sp,bp ;释放局部变量空间 pop bp ;恢复栈底 retn 4 ;平栈
我们发现这些代码都要我们自己去写,我们可不可以只写我们的核心代码,而这些教给编译器去完成
下面开始汇编子程序(函数)的伪指令的编写
二丶汇编中函数伪指令的详细用法
1.伪指令函数关键字,以及用法
[<prologuearg>]
[USES reglist] [,parameter [:tag]]...
[LOCAL varlist]
statements
label ENDP
1.使用调用方式 distance
MY_Add proc near
函数名 关键字 调用方式
看下汇编代码:
MyData segment db 100 ;数据段 MyData ends MyStack segment stack org 100 ;栈段 MyStack ends MyCode segment ;专门放函数的代码段,代码段同名将合并 MY_ADD proc near ret ;这里是利用了伪指令,主要看这里,我们直接写个ret即可现在的调用方式写的是near
;下面看下反汇编
MY_ADD endp MyCode ends MyCode segment START: ;代码段 mov ax,MyData mov ds,ax mov es,ax mov ax,MyStack mov ss,ax ;分段 MyCode ends end START
反汇编

因为我们是段内调用,默认就是ret了,现在我们改成段间调用,让大家看下是什么效果

所以调用方式应该明白是什么意思了吧,因为ret会自动根据我们给的调用方式去平栈,如果我们有参数,则会平正确的栈. 如果 retf 和 retn 不懂的,请看16位汇编第十讲完结,里面具体分析了怎么平栈,以及他们两个的区别
2.使用调用约定 langtype
使用调用约定,就不得不调用函数了,我们先简单的调用一下函数
看汇编代码:
mov ax,9 push ax ;传递参数,圧栈 mov bx,4 push bx CALL MY_ADD ;调用函数 MY_ADD proc far stdcall ret ;平衡栈 MY_ADD endp
如果我们指定stdcall,那么平栈的时候则会帮我们按照stdcall的形式去平栈
3.使用寄存器 (USES Reglist)
上面我们每次写的时候,都要自己保存寄存器的信息,这样很不方便,我们要做的就是和C语言一样,声明了函数,直接写自己的代码,所以看下列汇编代码的变化
MY_ADD proc far stdcall USES bx cx ;这里我们USES bx cx 代表让编译器自动帮我们保存寄存器的信息 ret ;平衡栈 MY_ADD endp
如果是要保存多个,则在后面继续写寄存器即可
例如:
MY_ADD proc far stdcall USES bx cx dx si .....;如果是多个继续往下下,我们看下反汇编 ret ;平衡栈 MY_ADD endp
反汇编:

他保存了bx,cx的信息,然后弹栈的时候自动弹出,恢复环境
4.使用参数 parameter:tag
我们写代码还有一个不方便的地方就是每次找参数的时候,我们都要去计算,比如bp -8 bp - 10这样去写
以前的代码:
mov ax,[bp -8] ;找到参数二 mov bx,[bp -10] ;找到参数一 .....
现在不用这么麻烦了,我们只需要指定参数名字即可
MY_ADD proc far stdcall USES cx, nn1:WORD ,nn2:WORD ret ;平衡栈 MY_ADD endp
nn1 参数名 : 类型(也就是大小)
注意:
1.我们保存寄存器环境在参数定义的左边,如果要加参数,需要加个逗号隔开
2.定义参数的时候,类型名(大小)一定要大写
使用:
我们以前使用都是bp -xxx ,现在可以直接用这些参数代替了,如果计算一个结果,放到ax当中
汇编代码:
mov ax,9 push ax ;传递参数,圧栈 mov bx,4 push bx CALL MY_ADD ;调用函数 MY_ADD proc near stdcall USES cx, nn1:WORD ,nn2:WORD mov cx,nn1 mov ax,nn2 ;这里只需要写我们自己的代码即可,伪指令对应的汇编都会自动完成 add ax,cx ret ;平衡栈 MY_ADD endp
这里使用了伪指令,所以都会翻译成等价的汇编代码了,我们看下反汇编,看下参数变为什么样子了

它会自动的完成转换
注意:
1.虽然变成了参数,但其实翻译的汇编代码还是 [bp-xxx],还是不能内存直接给内存
比如不能写成这样
mov nn1,nn2
这样汇编代码翻译过来就是
mov [bp-xxx],[bp-xxx]
我们以前说过,想使用内存的值,必须经过中转才可以,(也就是给鸡存器保存一下,或者放到CPU的暂存器中)
5.局部变量的使用,以及注意的问题(重要)
局部变量以及开辟局部变量,以前都是栈顶-xx,(俗称抬栈)
比如汇编代码写成
push bp ;保存栈底 mov bp,sp sub sp,4 ;开辟局部变量控件 push cx ;保存寄存器的环境 .....你的核心代码 pop cx ;恢复寄存器的环境 mov sp,bp ;恢复局部变量空间(销毁) pop bp ;恢复栈底 ret ;平衡栈
但是现在我们直接写一下,看下会出现什么问题
汇编代码:
mov ax,9 push ax ;传递参数,圧栈 mov bx,4 push bx CALL MY_ADD ;调用函数 MY_ADD proc near stdcall USES cx, nn1:WORD ,nn2:WORD sub sp,4 ;开辟局部变量空间 mov cx,nn1 mov ax,nn2 ;我们的核心代码 add ax,cx ret ;平衡栈 MY_ADD endp
反汇编:
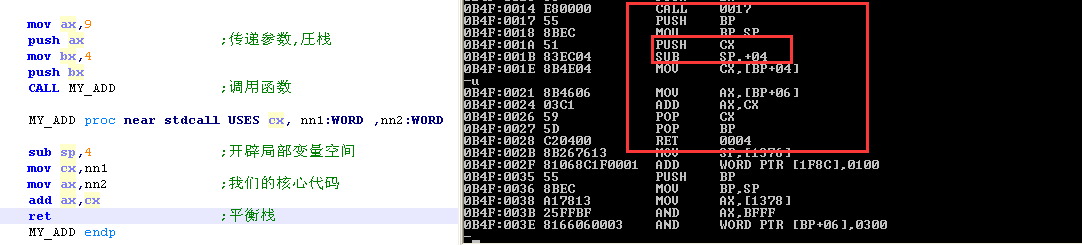
我已经画出来了,大家看下会出现什么清空,这里给个提示
生成函数的步骤
我们发现了,我们应该先抬栈,在保存环境
以前的代码都是这样写的,但是伪指令生成的汇编代码我们没办法改,怎么办,也就意味着,如果开辟局部变量空间
那么就会出错的.
解决方法,用新的伪指令,定义局部变量
LOCAL 变量名字:类型(大小)
请看汇编代码:
mov ax,9 push ax ;传递参数,圧栈 mov bx,4 push bx CALL MY_ADD ;调用函数 MY_ADD proc near stdcall USES cx, nn1:WORD ,nn2:WORD ;sub sp,4 ;开辟局部变量空间 LOCAL MyAAA:WORD ;申请局部变量空间 LOCAL MyBBB:WORD mov cx,nn1 mov ax,nn2 ;我们的核心代码 add ax,cx ret ;平衡栈 MY_ADD endp
看下反汇编:

可以看出,这些正常了,先申请空间,然后保存环境,恢复的时候是先恢复环境,然后释放局部变量空间
这里申请局部变量空间的时候,并没有使用 sup sp,4 而是使用的加法指令 add sp-4 其实是一样的
这里关于函数定义的伪指令调用就结束了,我们只需要写上这些伪指令,那么我们就可以和C语言一样,直接写我们的
核心代码了
6.函数调用的伪指令(定义讲完了,该讲调用了)
我们每次调用的时候,都要先 传入参数,压栈,然后Call
现在提供了一个伪指令,让我们像C语言一样的方式去掉用
Invoke 伪指令

关于这个伪指令文档,课程资料里会带 (文件名字是 masm32.chm)
看上面写的,我们只需要
invoke 函数名 这样是调用空参函数
invoke MY_ADD
invoke 函数名, 传入的参数1,传入的参数2.. 调用带参函数
invoke MY_ADD ,1 ,2
我们的例子修改为这种调用
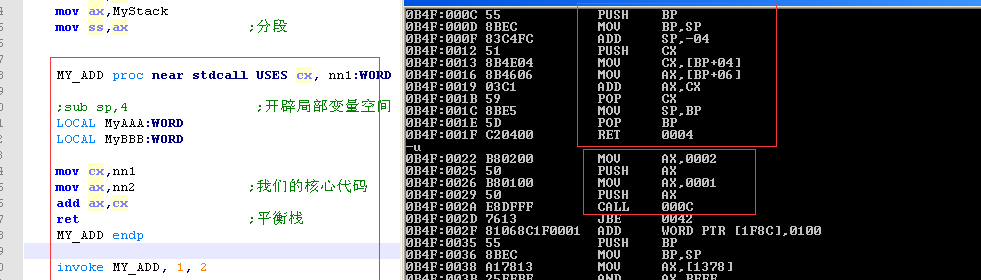
其实还是改为我们上一次调用的那种
注意:
1.使用invoke的时候,函数的定义必须放在前面,否在报错
三丶更多的伪指令 (if if else if else if else while do while for )
这里只说几个,具体的自己查下手册看下使用即可
1.if的使用
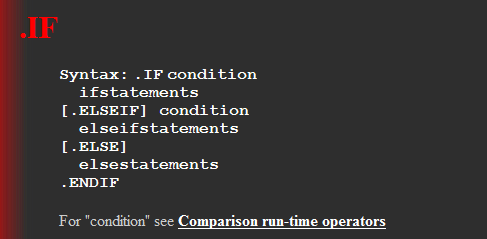
看下语法就知道了
以前我们用汇编写if语句
mov ax,0 cmp ax,0 jnz END ;不等于0,跳到结束 .............;等于0执行我们的代码 END: .....;结束的代码
而现在我们可以用伪指令写成
.if ax == 0 mov ax,3 .endif
如果带有else的则加个else 在.endif, 如果是 elise if 则同理
2.while的伪指令的用法

while ax == 0 ..... endm
这些很简单了,编译出的汇编代码就是前几天的作业,只要写过就知道汇编代码是什么了,不会的可以自己看下反汇编
四丶汇编中的有参宏,和无参宏,以及条件宏
1.条件宏伪指令(和C语言类似)
ifndef HELLO ;如果没有定义HELLO HELLO EQU ;那就定义HELLO EQU是代表定义宏的意思,相当于C语言的#define endif
2.无参宏,无参宏就是EQU(#define)
定义的名字 EQU关键字 替换为 PI EQU 314 ;定义PI 它的值是314
3.带参数的宏(这个比较有意思)
记得我们函数伪指令的时候的ret吗,我们可以吧ret替换为return,和C语言一样的使用
带参宏的伪指令是 macro
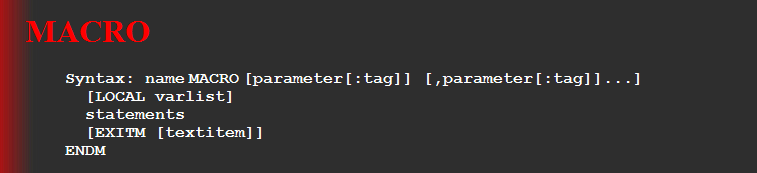
return macro n1ret n1 endm
注意参数的时候后我们不用给类型了,也就是说不能写成下面这样
return macro n1:WORD
可以有多个参数
return macro n1,n2.....

五丶伪指令之汇编中的结构体
我们以前定义数据的时候都是在全局数据区去定义,但是这样不好,如果数据一多就不好整理了,现在伪指令提供了一个struct的关键字,让我们去定义
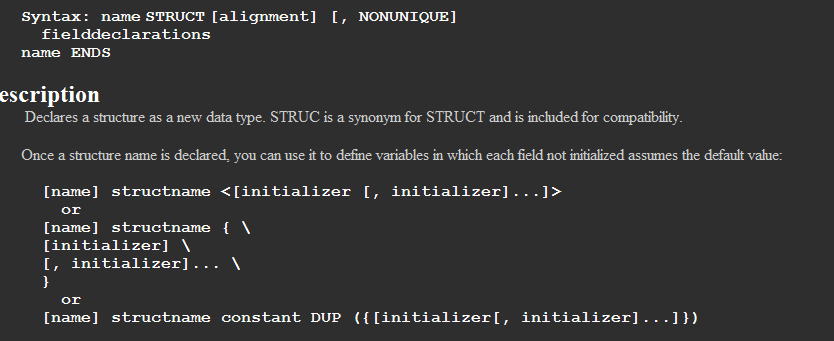
使用:
1.结构体的定义以及使用
结构体的定义是放在全局数据区的外面
定义:
结构体名称 关键字 成员 大小 是否初始化 .......... 结构体名称 结束标志 例子: MyData struct year dw ? ;都是不初始化的 month dw ? day dw ? MyData ends
使用:
使用的时候需要放在全局数据区的段里面
例如:
MyData segment
结构体变量名称 结构体名称 <初始化的值>
g_Data1 MyData<?>
MyData ends
访问结构体的两种方法
1.使用LEA访问
2.使用假设(伪指令 这个伪指令叫做假设)
1.LEA访问
lea bx,g_Data1
mov word ptr[bx+xxx],1 给结构体成员赋值,这样需要自己去算
2.使用假设伪指令

看汇编代码
lea bx,g_Data1 假设关键字 假设的事物 假设成什么 ASSUME bx:ptr MyData ;假设bx 是MyData的结构体的指针 mov [bx].year,1 mov [bx].month,2 ........... ;如果bx还有其他的作用,则取消假设 ;一般是配套使用 ASSUMW bx:nothing ;假设bx什么都不是
2.结构体套结构体的定义以及使用
直接看汇编代码吧:
MyDatas struct year dw ? month dw ? ;定义日期结构体 day dw ? MyDatas ends Student struct sid dw ? sex dw ? ;定义学生 bbb MyDatas<?>;结构体套日期结构体,并且初始化,重要这里必看 Student ends MyData segment db 100 ;数据段 g_Stu Student<1, 2, <2017,2,3> > ;都初始化 MyData ends MyStack segment stack org 100 ;栈段 MyStack ends MyCode segment START: ;代码段 mov ax,MyData mov ds,ax mov es,ax mov ax,MyStack mov ss,ax ;分段 ;使用结构体 lea bx,g_Stu ASSUME bx: ptr Student mov [bx].sid ,1 mov [bx].sex ,2 ;使用的时候都可以通过.访问了 mov [bx].bbb.year ,3
ASSUME bx:nothing MyCode ends end START
反汇编代码:

编译器会自动帮我们寻址去翻译
6.使用假设伪指令 访问全局变量
以前我们访问的时候 都是通过 lea 给基址寄存器,然后在通过内存访问直接修改里面的值,例如
lea bx,g_number mov word ptr[bx],1 ;给它所在的内存复制
现在,我们只需要先把段假设一下,然后可以直接给ax
MyData segment db 100 ;数据段 g_number dw 1 ;给全局变量申请一个直接 MyData ends MyStack segment stack org 100 ;栈段 MyStack ends MyCode segment ASSUME cs:seg MyCode, DS:seg MyData, SS: MyStack ;假设一下 START: ;代码段 mov ax,MyData mov ds,ax mov es,ax mov ax,MyStack mov ss,ax ;分段 ;使用 mov ax,g_number ;直接可以个ax了,不用再通过lea了 mov g_number,1 ;这里注意一下,我们是可以 mov mem,imm 的,以前的时候寻址方式都讲过了
; 不能mov mem,mem ,也说过 内存和内存不能直接交换,必须通过中转
MyCode ends end START
看下反汇编代码:

想当与和我们手写是一样的
如果对你有帮助,请评论或者收藏,谢谢支持,码字不易,写一篇好的博客,最少4个小时,只因为想把最精彩,最有用的干活分享给你
课堂资料下载:
链接:http://pan.baidu.com/s/1i5zhYZj 密码:jbsb