1.Terminology
- Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
- Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处).
Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。
- Partition
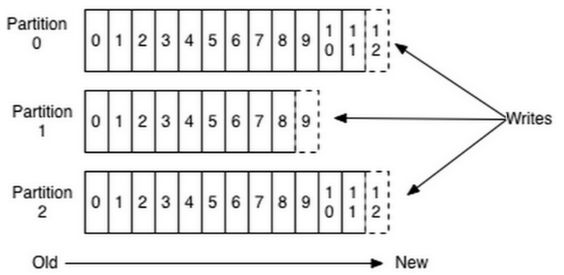
Parition是物理上的概念,为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。
消息文件都是一个log entrie序列,每个log entrie包含一个4字节整型数值(值为N+5),1个字节的"magic value",4个字节的CRC校验码,其后跟N个字节的消息体。每条消息都有一个当前Partition下唯一的64字节的offset,它指明了这条消息的起始位置。
这个log entries并非由一个文件构成,而是分成多个segment,每个segment以该segment第一条消息的offset命名并以“.kafka”为后缀。另外会有一个索引文件,它标明了每个segment下包含的log entry的offset范围,如下图所示。
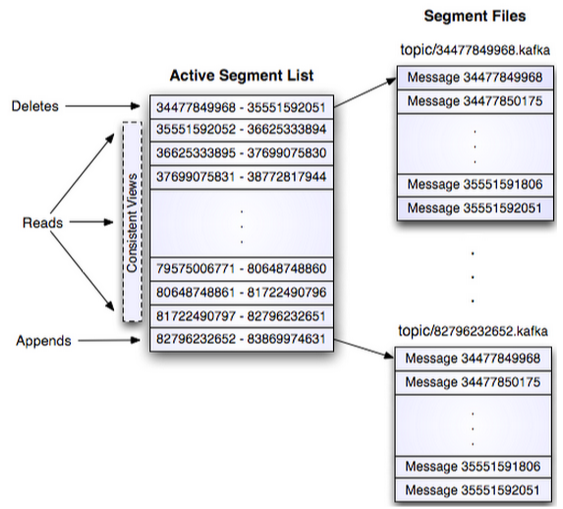
因为每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。
- Producer
负责发布消息到Kafka broker
- Consumer
消息消费者,向Kafka broker读取消息的客户端。
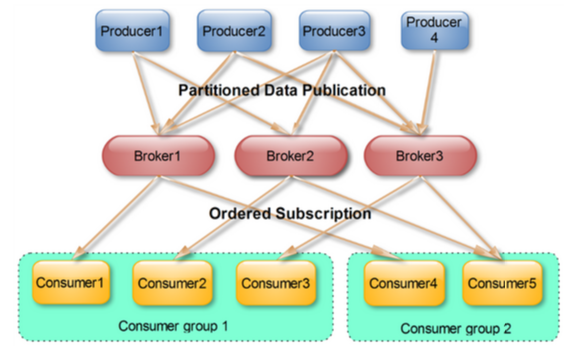
- Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
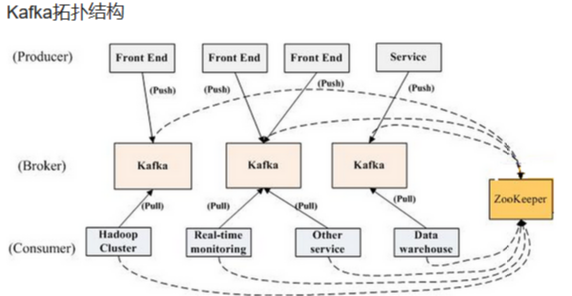
2. Kafka拓扑结构