用户态与内核态
JDK早期,synchronized 叫做重量级锁(用户态),因为申请锁资源必须通过kernel(内核态), 系统调用
CAS
Compare And Swap (Compare And Exchange) / 自旋 / 自旋锁 / 无锁 (无重量锁)
因为经常配合循环操作,直到完成为止,所以泛指一类操作
cas(v, a, b) ,变量v,期待值a, 修改值b
ABA问题,v解决办法(版本号 AtomicStampedReference),基础类型简单值不需要版本号

Unsafe
最终实现:
cmpxchg = cas修改变量值
assembly lock cmpxchg 指令
硬件:
lock指令在执行后面指令的时候锁定一个北桥信号
(不采用锁总线的方式)
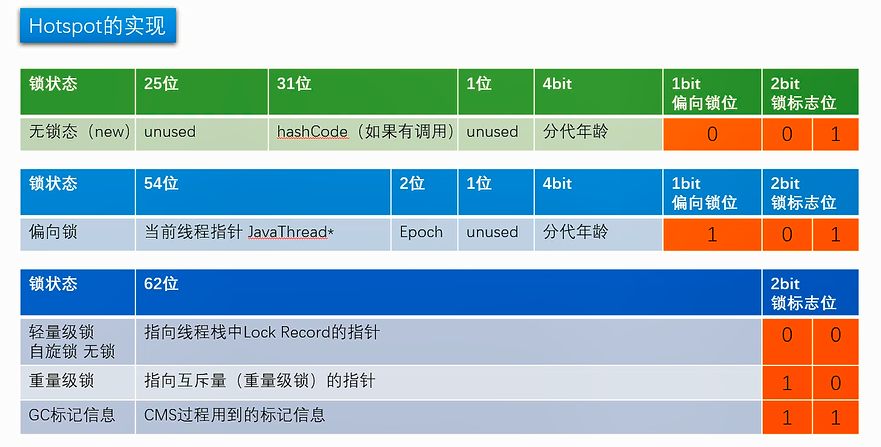
markword 64位
工具:JOL = Java Object Layout
synchronized优化的过程和markword息息相关
用markword中最低的三位代表锁状态 其中1位是偏向锁位 两位是普通锁位
-
Object o = new Object() 锁 = 0 01 无锁态 注意:如果偏向锁打开,默认是匿名偏向状态
-
o.hashCode() 001 + hashcode
java 00000001 10101101 00110100 00110110 01011001 00000000 00000000 00000000
little endian big endian
00000000 00000000 00000000 01011001 00110110 00110100 10101101 00000000
- 默认synchronized(o) 00 -> 轻量级锁 默认情况 偏向锁有个时延,默认是4秒 why? 因为JVM虚拟机自己有一些默认启动的线程,里面有好多sync代码,这些sync代码启动时就知道肯定会有竞争,如果使用偏向锁,就会造成偏向锁不断的进行锁撤销和锁升级的操作,效率较低。
shell -XX:BiasedLockingStartupDelay=0
-
如果设定上述参数 new Object () - > 101 偏向锁 ->线程ID为0 -> Anonymous BiasedLock 打开偏向锁,new出来的对象,默认就是一个可偏向匿名对象101
-
如果有线程上锁 上偏向锁,指的就是,把markword的线程ID改为自己线程ID的过程 偏向锁不可重偏向 批量偏向 批量撤销
-
如果有线程竞争 撤销偏向锁,升级轻量级锁 线程在自己的线程栈生成LockRecord ,用CAS操作将markword设置为指向自己这个线程的LR的指针,设置成功者得到锁
-
如果竞争加剧 竞争加剧:有线程超过10次自旋, -XX:PreBlockSpin, 或者自旋线程数超过CPU核数的一半, 1.6之后,加入自适应自旋 Adapative Self Spinning , JVM自己控制 升级重量级锁:-> 向操作系统申请资源,linux mutex , CPU从3级-0级系统调用,线程挂起,进入等待队列,等待操作系统的调度,然后再映射回用户空间
(以上实验环境是JDK11,打开就是偏向锁,而JDK8默认对象头是无锁)
偏向锁默认是打开的,但是有一个时延,如果要观察到偏向锁,应该设定参数.如果计算过对象的hashCode,则对象无法进入偏向状态!
锁升级
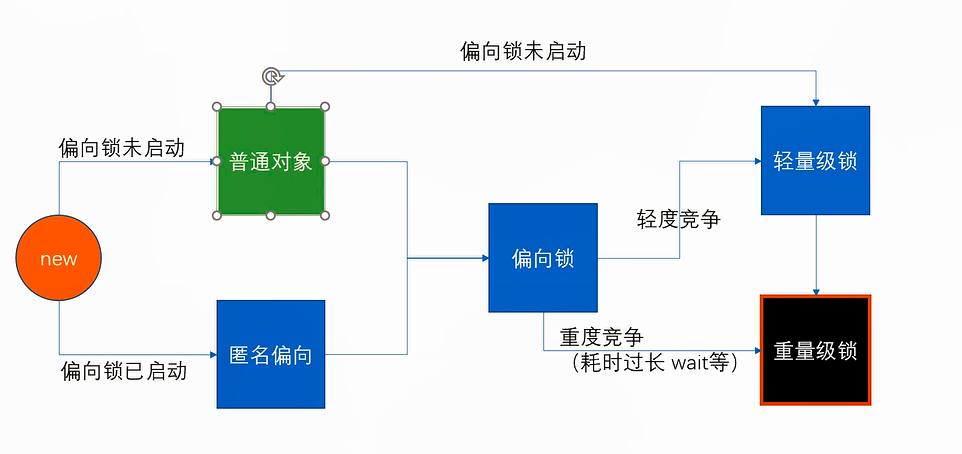
锁升级的过程:new - 偏向锁 - 轻量级锁 (无锁, 自旋锁,自适应自旋)- 重量级锁
JDK较早的版本 OS的资源 互斥量 用户态 -> 内核态的转换 重量级 效率比较低
现代版本进行了优化
无锁 - 偏向锁 -轻量级锁(自旋锁)-重量级锁
偏向锁 - markword 上记录当前线程指针,下次同一个线程加锁的时候,不需要争用,只需要判断线程指针是否同一个,所以,偏向锁,偏向加锁的第一个线程 。hashCode备份在线程栈上 线程销毁,锁降级为无锁
有争用 - 锁升级为轻量级锁 - 每个线程有自己的LockRecord在自己的线程栈上,用CAS去争用markword的LR的指针,指针指向哪个线程的LR,哪个线程就拥有锁
自旋超过10次,升级为重量级锁 - 如果太多线程自旋 CPU消耗过大,不如升级为重量级锁,进入等待队列(不消耗CPU)-XX:PreBlockSpin
自旋锁在 JDK1.4.2 中引入,使用 -XX:+UseSpinning 来开启。JDK 6 中变为默认开启,并且引入了自适应的自旋锁(适应性自旋锁)。
自适应自旋锁意味着自旋的时间(次数)不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。
偏向锁由于有锁撤销的过程revoke,会消耗系统资源,所以,在锁争用特别激烈的时候,用偏向锁未必效率高。还不如直接使用轻量级锁。
锁重入
sychronized是可重入锁
重入次数必须记录,因为要解锁几次必须得对应
偏向锁 自旋锁 -> 线程栈 -> LR + 1
重量级锁 -> ? ObjectMonitor字段上
synchronized最底层实现
public class T { static volatile int i = 0; public static void n() { i++; } public static synchronized void m() {} publics static void main(String[] args) { for(int j=0; j<1000_000; j++) { m(); n(); } } }
java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly T
C1 Compile Level 1 (一级优化)
C2 Compile Level 2 (二级优化)
找到m() n()方法的汇编码,会看到 lock comxchg 指令
synchronized vs Lock (CAS)
在高争用 高耗时的环境下synchronized效率更高 在低争用 低耗时的环境下CAS效率更高 synchronized到重量级之后是等待队列(不消耗CPU) CAS(等待期间消耗CPU)一切以实测为准
锁消除 lock eliminate
public void add(String str1,String str2) { StringBuffer sb = new StringBuffer(); sb.append(str1).append(str2); }
我们都知道 StringBuffer 是线程安全的,因为它的关键方法都是被 synchronized 修饰过的,但我们看上面这段代码,我们会发现,sb 这个引用只会在 add 方法中使用,不可能被其它线程引用(因为是局部变量,栈私有),因此 sb 是不可能共享的资源,JVM 会自动消除 StringBuffer 对象内部的锁。
锁粗化 lock coarsening
public String test(String str) { int i = 0; StringBuffer sb = new StringBuffer(): while(i < 100){ sb.append(str); i++; } return sb.toString():
JVM 会检测到这样一连串的操作都对同一个对象加锁(while 循环内 100 次执行 append,没有锁粗化的就要进行 100 次加锁/解锁),此时 JVM 就会将加锁的范围粗化到这一连串的操作的外部(比如 while 虚幻体外),使得这一连串操作只需要加一次锁即可。
锁降级
只被VMThread访问,降级也就没啥意义了。所以可以简单认为锁降级不存在
FAQ:
自旋锁什么时候升级为重量级锁?
有线程超过10次自旋, -XX:PreBlockSpin, 或者自旋线程数超过CPU核数的一半, 1.6之后,加入自适应自旋 Adapative Self Spinning , JVM自己控制
为什么有自旋锁还需要重量级锁?
自旋是消耗CPU资源的,如果锁的时间长,或者自旋线程多,CPU会被大量消耗,重量级锁有等待队列,所有拿不到锁的进入等待队列,不需要消耗CPU资源
偏向锁是否一定比自旋锁效率高?
不一定,在明确知道会有多线程竞争的情况下,偏向锁肯定会涉及锁撤销,这时候直接使用自旋锁,JVM启动过程,会有很多线程竞争(明确),所以默认情况启动时不打开偏向锁,过一段儿时间再打开.JVM启动过程,会有很多线程竞争(明确),所以默认情况启动时不打开偏向锁,过一段儿时间再打开,默认4秒