公司项目有一个功能需要用到分布式锁功能,一开始使用redis(redisson)实现分布式锁,后来比较以后使用zookeeper(spring-integration-zookeeper),这边做下总结:
分布式的 CAP 理论告诉我们:任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。
基于 CAP理论,很多系统在设计之初就要对这三者做出取舍。
目前常见的三种分布式锁:
1 基于数据库实现的分布式锁
a 乐观锁:基于表主键唯一做分布式锁
b 悲观锁:基于数据库排他锁做分布式锁,for update,InnoDB 引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。mysql数据库的默认引擎(5.1版本之后)是InnoDB,所以这块要多注意
2 基于缓存的分布式锁
基于 redis的 setnx()、expire() 方法做分布式锁:
setnx:SET if Not Exists,其主要有两个参数 setnx(key, value)。该方法是原子的,如果 key 不存在,则设置当前 key 成功,返回 1;如果当前 key 已经存在,则设置当前 key 失败,返回 0
expire:设置过期时间,要注意的是 setnx 命令不能设置 key 的超时时间,只能通过 expire() 来对 key 设置
基于 REDISSON 做分布式锁:redisson 是 redis 官方的分布式锁组件,里面有封装好的api
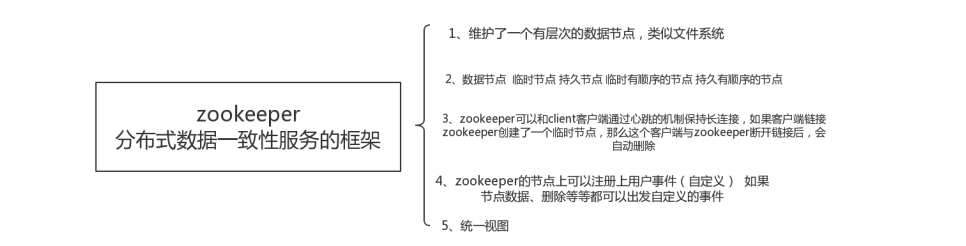
3 基于Zookeeper实现的分布式锁
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名:
a 基于开源库Curator,它是一个ZooKeeper客户端,Curator提供的InterProcessMutex是分布式锁的实现,acquire方法用于获取锁,release方法用于释放锁
b 基于spring-integration-zookeeper
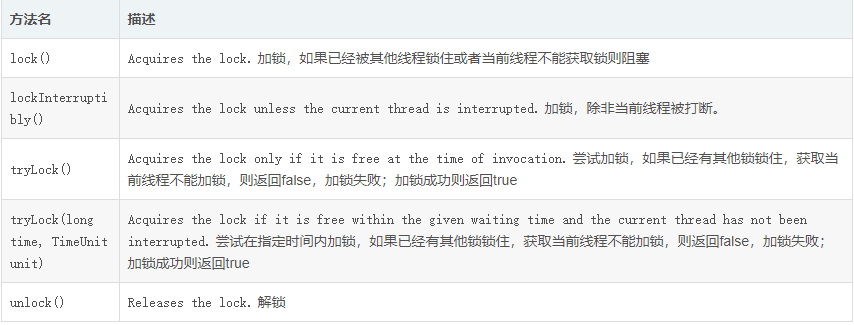
几种方案的比较
从理解的难易程度角度(从低到高)
数据库 > 缓存 > Zookeeper
从实现的复杂性角度(从低到高)
Zookeeper > 缓存 > 数据库
从性能角度(从高到低)
缓存 > Zookeeper >= 数据库
从可靠性角度(从高到低)
Zookeeper > 缓存 > 数据库
4 还有一种基于 Consul 做分布式锁:
出自程序员DD https://blog.didispace.com/spring-cloud-consul-lock-and-semphore/
基于Consul的分布式锁主要利用Key/Value存储API中的acquire和release操作来实现。acquire和release操作是类似Check-And-Set的操作:
- acquire操作只有当锁不存在持有者时才会返回true,并且set设置的Value值,同时执行操作的session会持有对该Key的锁,否则就返回false
- release操作则是使用指定的session来释放某个Key的锁,如果指定的session无效,那么会返回false,否则就会set设置Value值,并返回true
具体实现中主要使用了这几个Key/Value的API:
- create session:https://www.consul.io/api/session.html#session_create
- delete session:https://www.consul.io/api/session.html#delete-session
- KV acquire/release:https://www.consul.io/api/kv.html#create-update-key
项目组综合比较之后倾向于使用Spring Integration 优雅的实现分布式锁,最终使用spring-integration-zookeeper
Spring Integration在基于Spring的应用程序中实现轻量级消息传递,并支持通过声明适配器与外部系统集成。 Spring Integration的主要目标是提供一个简单的模型来构建企业集成解决方案,同时保持关注点的分离,这对于生成可维护,可测试的代码至关重要。我们熟知的 Spring Cloud Stream的底层就是Spring Integration。
Spring Integration提供的全局锁目前为如下存储提供了实现:
- Gemfire
- JDBC
- Redis
- Zookeeper