一、指数加权平均算法介绍
引言
在了解指数加权平均之前,首先我们需要回顾一下求平均数的相关概念,从而进行进一步理解与引导。
如何求平均数
平均数求法数学公式:
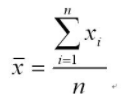
现在举例说明:比如我们现在有100天的温度值,要求这100天的平均温度值(24,25,24,26,34,28,33,33,34,35..........32),我们可以直接用公式进行运算。
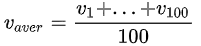 ,通过此公式就可以直接求出10天的平均值。而我们要介绍的指数加权平均本质上就是一种近似求平均的方法。
,通过此公式就可以直接求出10天的平均值。而我们要介绍的指数加权平均本质上就是一种近似求平均的方法。
指数加权平均介绍
公式:
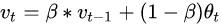
参数说明:
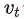 |
第t天的平均温度值 |
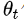 |
第t天的温度值 |
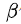 |
可调节的超参数值 |
假如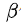 =0.9,我们可以得到指数平均公式下的平均值求法如下:
=0.9,我们可以得到指数平均公式下的平均值求法如下:
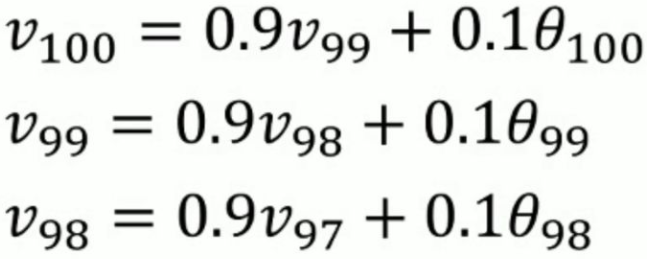
通过上面表达式,我们可以看到,V100等于每一个时刻天数的温度值再乘以一个权值。指数加权平均的结果是由当天温度值乘以指数衰减函数值,然后类和求得!
本质就是以指数式递减加权的移动平均。各数值的加权而随时间而指数式递减,越近期的数据加权越重,但较旧的数据也给予一定的加权。
而在我们上面提到的普通平均数求法,它的每一项的权值都是一样的,如果有n项,权值都为1/n。
指数加权平均优势
推导过程如下:
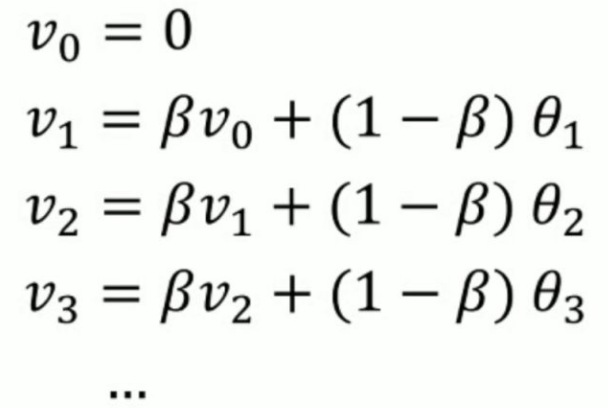
我们可以看到指数加权平均的求解过程实际上是一个递推的过程,那么这样就会有一个非常大的好处,每当我要求从0到某一时刻(n)的平均值的时候,我并不需要像普通求解平均值的作为,保留所有的时刻值,类和然后除以n。而是只需要保留0-(n-1)时刻的平均值和n时刻的温度值即可。也就是每次只需要保留常数值,然后进行运算即可,这对于深度学习中的海量数据来说,是一个很好的减少内存和空间的做法。
二、指数加权平均算法偏差修正
我们首先来看一个图:
 假设β=0.98时,指数加权平均结果如上图绿色曲线所示。但是实际上,真实曲线如紫色曲线所示,修正这种问题的方法是进行偏移校正(bias correction)。即在每次计算完Vt后,对Vt进行下式处理:
假设β=0.98时,指数加权平均结果如上图绿色曲线所示。但是实际上,真实曲线如紫色曲线所示,修正这种问题的方法是进行偏移校正(bias correction)。即在每次计算完Vt后,对Vt进行下式处理:

在刚开始的时候,t比较小,(1−βt)<1(1−βt)<1,这样就将VtVt修正得更大一些,效果是把紫色曲线开始部分向上提升一些,与绿色曲线接近重合。随着t增大,(1−βt)≈1(1−βt)≈1,Vt基本不变,紫色曲线与绿色曲线依然重合。这样就实现了简单的偏移校正,得到我们希望的绿色曲线。
值得一提的是,机器学习中,偏移校正并不是必须的。因为,在迭代一次次数后(t较大),Vt受初始值影响微乎其微,紫色曲线与绿色曲线基本重合。所以,一般可以忽略初始迭代过程,等到一定迭代之后再取值,这样就不需要进行偏移校正了。
参考:https://zhuanlan.zhihu.com/p/29895933