梯度消失经常出现在:深层网络、采用了不合适的损失函数,比如sigmoid。
梯度爆炸一般出现在:深层网络、权值初始化值太大的情况下。
1、深层网络角度解释梯度消失、梯度爆炸的原因:
对激活函数进行求导,如果求导的每个部分部分小于1,那么随着层数增多,求出的梯度更新信息将会以指数形式衰减,即发生了梯度消失。
如果此部分大于1,那么层数增多的时候,最终的求出的梯度更新将以指数形式增加,即发生梯度爆炸。

图中的曲线表示权值更新的速度,从深层网络角度来讲,不同的层学习的速度差异很大,表现为网络中靠近输出的层学习的情况很好,靠近输入的层学习的很慢,有时甚至训练了很久,前几层的权值和刚开始随机初始化的值差不多。因此,梯度消失、爆炸,其根本原因在于反向传播训练法则,属于先天不足。
2、激活函数角度解释梯度消失、梯度爆炸的原因:
如果激活函数选择不合适,比如使用sigmoid,梯度消失就会很明显了,原因看下图,左图是sigmoid的损失函数图,右边是其导数的图像,如果使用sigmoid作为损失函数,其梯度是不可能超过0.25的,这样经过链式求导之后,很容易发生梯度消失。
sigmoid函数数学表达式为: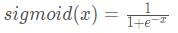
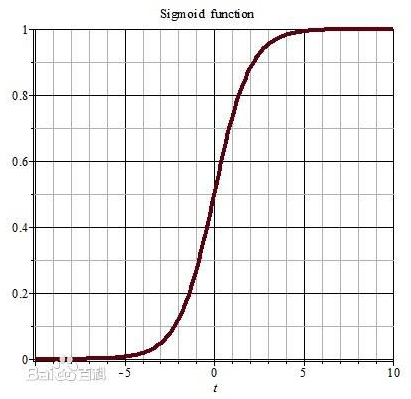
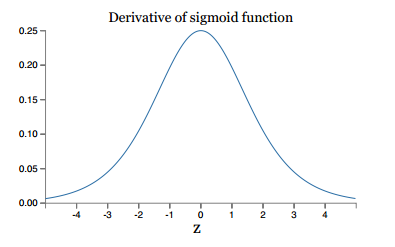
同理,tanh作为激活函数,它的导数图如下,可以看出,tanh比sigmoid要好一些,但是它的导数仍然是小于1的。tanh数学表达为: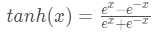

3、解决方案:
- 用ReLU、Leaky-ReLU、P-ReLU、R-ReLU、Maxout等替代sigmoid函数。
- 用Batch Normalization。
- LSTM的结构设计可以改善RNN中的梯度消失问题。
- 动态地改变学习率,当梯度过小时,增大学习率,当过大时,减小学习率。
- 神经网络的权重标准初始化
(1)用ReLU、Leaky-ReLU、P-ReLU、R-ReLU、Maxout等替代sigmoid函数。
ReLU
Relu思想很简单,如果激活函数的导数为1,那么就不存在梯度消失爆炸的问题了,每层的网络都可以得到相同的更新速度,relu就这样应运而生。先看一下relu的数学表达式:
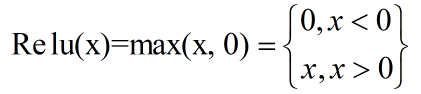
其函数图像:
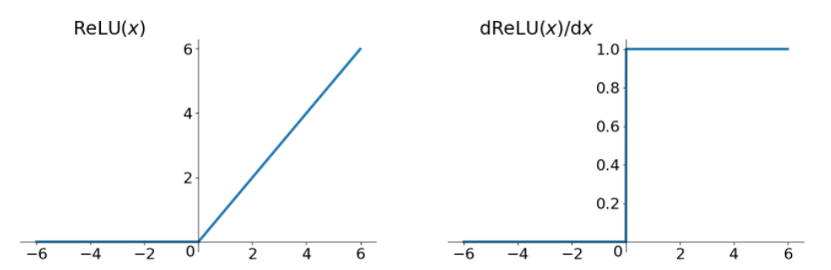
从上图中,我们可以很容易看出,relu函数的导数在正数部分是恒等于1的,因此在深层网络中使用relu激活函数就不会导致梯度消失和爆炸的问题。
relu的主要优点:
-- 解决了梯度消失、爆炸的问题
-- 计算方便,计算速度快
-- 加速了网络的训练
relu的主要缺点:
-- 由于负数部分恒为0,会导致一些神经元无法激活(可通过设置小学习率部分解决)
-- 输出不是以0为中心的
leakrelu
leakrelu就是为了解决relu的0区间带来的影响,其数学表达为: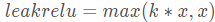 ,其中k是leak系数,一般选择0.01或者0.02,或者通过学习而来。
,其中k是leak系数,一般选择0.01或者0.02,或者通过学习而来。
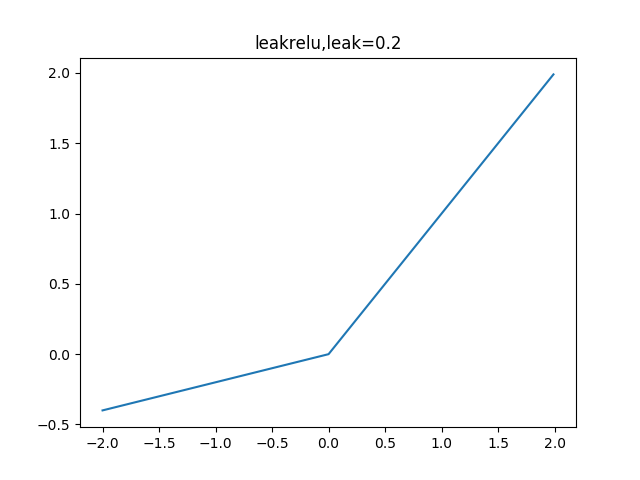
其函数及其导数数学形式为: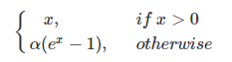
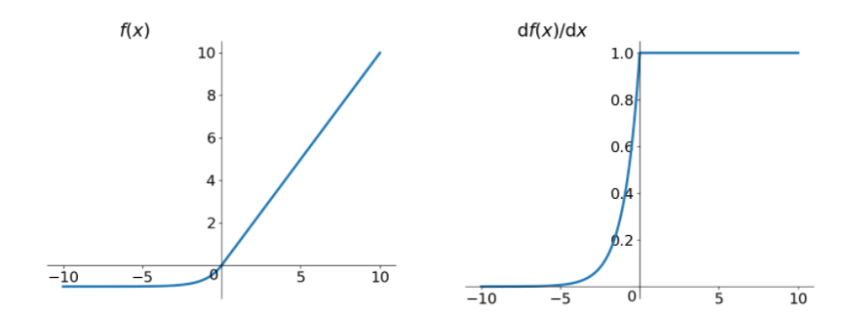
leakrelu解决了0区间带来的影响,而且包含了relu的所有优点,但是elu相对于leakrelu来说,计算要更耗时间一些。
参考:https://blog.csdn.net/qq_25737169/article/details/79048516