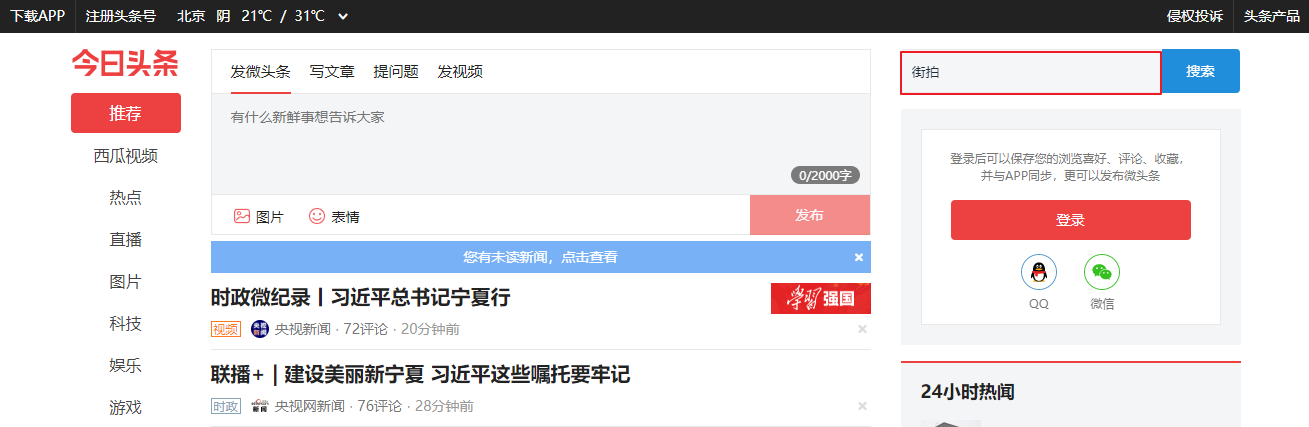
在页面中单击鼠标右键(或者用快捷键),选择检查元素:
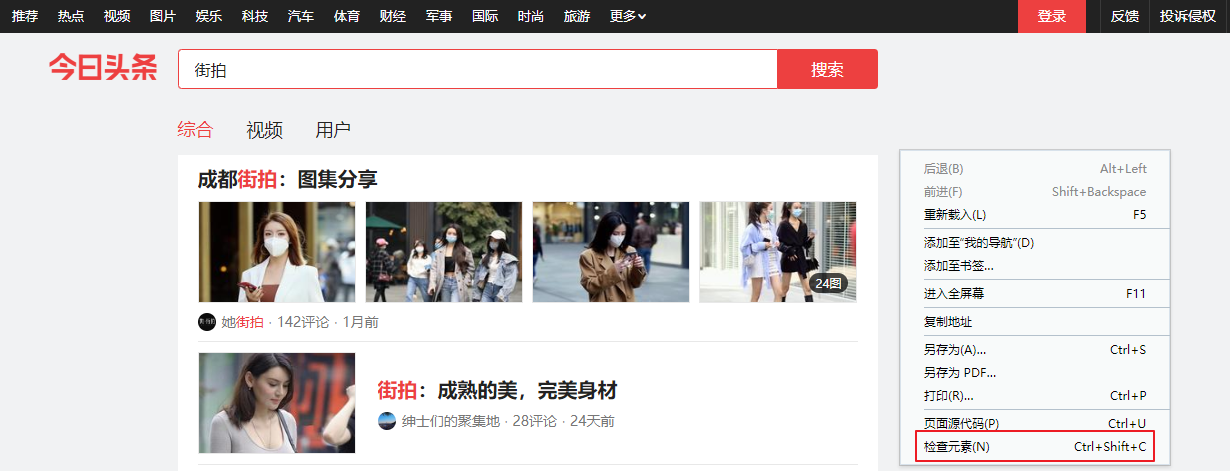
切换到Network选项卡,不断向下滚动页面,即可看到如下请求:

该请求的响应数据中就包含我们想要的图片地址。

如上图所示,请求方法是GET,请求URL还包含了一些参数:
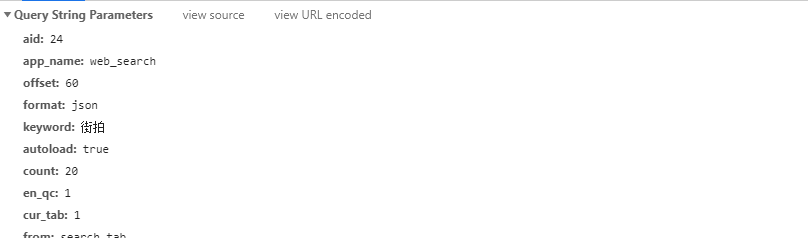
分析到这儿就差不多了,开始Coding吧!
代码如下:
`package com.andy;
import com.google.gson.JsonArray;
import com.google.gson.JsonElement;
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import java.io.*;
import java.net.URL;
import java.util.*;
public class TouTiao {
private final String baseUrl = "https://www.toutiao.com/api/search/content/?offset=%d&autoload=true&from=search_tab&count=20&format=json&keyword=%s×tamp=";
private String keyword;
private String folderPath;
private Map<String, String> header = new HashMap<>();
public TouTiao(String keyword, String folderPath) {
this.keyword = keyword;
this.folderPath = folderPath;
}
public void setHeader() {
header.put(":authority", "www.toutiao.com");
header.put("referer", String.format("https://www.toutiao.com/search/?keyword=%s", keyword));
header.put("user-agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36 OPR/68.0.3618.63");
}
private List<String> parseImageUrl(int offset) throws IOException {
List<String> list = new ArrayList<>();
Connection connection = Jsoup.connect(String.format(baseUrl, offset, keyword) + System.currentTimeMillis()).headers(header);
Connection.Response response = connection.ignoreContentType(true).execute();
String body = response.body();
JsonObject jsonObject = new JsonParser().parse(body).getAsJsonObject();
if (jsonObject != null && jsonObject.get("data") != null) {
try {
JsonArray jsonArray = jsonObject.getAsJsonArray("data");
for (JsonElement jsonElement : jsonArray) {
JsonElement imageUrl = jsonElement.getAsJsonObject().get("large_image_url");
if (imageUrl != null) {
String src = imageUrl.getAsString();
if (src != null && src.trim().length() != 0) {
list.add(src);
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
return list;
}
public void crawl(int from, int to) throws IOException {
for (int i = from; i < to; i++) {
List<String> list = parseImageUrl(i * 20);
for (String url : list) {
downloadImageFromURL(url);
}
}
}
private void downloadImageFromURL(String src) throws IOException {
int lastIndex = src.lastIndexOf("/");
String name = src.substring(lastIndex + 1);
if (!name.endsWith(".png") || !name.endsWith(".jpg") || !name.endsWith(".gif") || !name.endsWith(".jpeg")) {
name = name + ".png";
}
System.out.println("Image name : " + name);
URL url = new URL(src);
InputStream inputStream = url.openStream();
OutputStream outputStream = new BufferedOutputStream(new FileOutputStream(folderPath + name));
System.out.println("Saved path: " + (folderPath + name));
for (int b; (b = inputStream.read()) != -1; ) {
outputStream.write(b);
}
outputStream.close();
inputStream.close();
}
public static void main(String[] args) {
try {
new TouTiao("街拍", "./Images/Toutiao/").crawl(1, 6);
} catch (IOException e) {
e.printStackTrace();
}
}}`
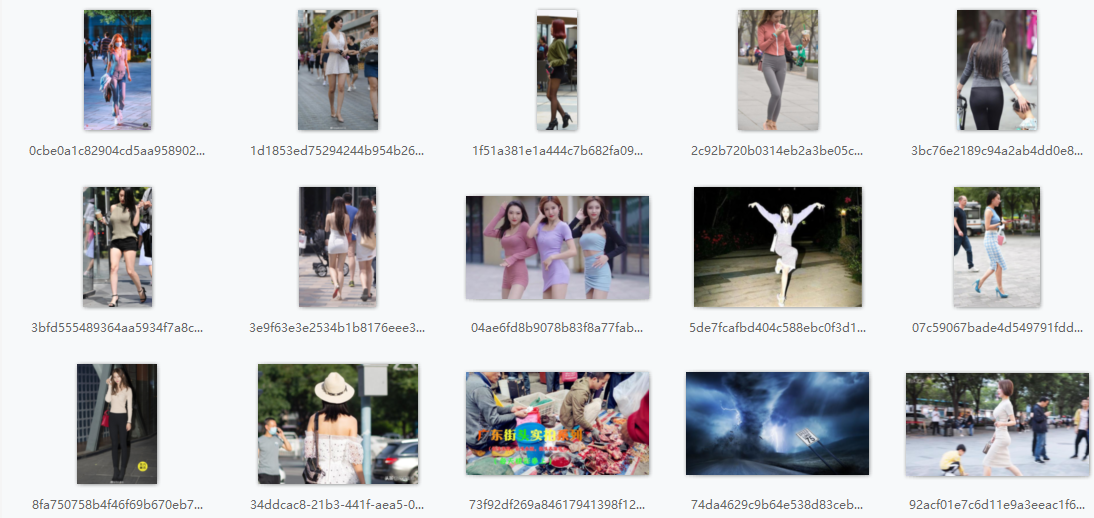
运行结果如下:
记得在项目的pom.xml文件中添加如下依赖:
`<!-- https://mvnrepository.com/art... -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.5</version></dependency>
<!-- https://mvnrepository.com/art... -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version></dependency>`