【机器学习】《机器学习》周志华西瓜书 笔记/习题答案 总目录
——————————————————————————————————————————————————————
习题

回顾一下性质:(《机器学习》周志华西瓜书学习笔记(九):聚类)
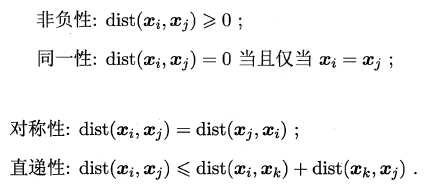
非负性、同一性、对称性很显然都是符合的,关键是直递性了,关于直递性就是闵可夫斯基不等式的证明,具体参考:闵可夫斯基不等式。



- 非负性:,所以 。若 ,则两个都大于0, 时最后结果大于0,否则小于0, 时最后结果还是大于0;
- 同一性: 假设 ,其他的样本都完全相同时,那么对于 都有 使得 ,而对于 ,由于没有相同的样本,所以 ,当且仅当相等时成立;
- 对称性:;
- 直递性:暂时不会。。。。。。
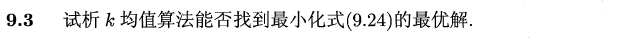

不能,因为 k 均值本身是 NP 问题,而且 9.24 是非凸的(具体证明不太懂),容易陷入局部最优,所以在使用 k 均值时常常多次随机初始化中心点,然后在中心点附近挑选结果最好的一个,即局部最优解,无法找到全局最优解。

代码如下:
import numpy as np
import matplotlib.pyplot as plt
from scipy.spatial import ConvexHull
class KMeans(object):
def __init__(self, k):
self.k = k
def fit(self, X, initial_centroid_index=None, max_iters=10, seed=16, plt_process=False):
m, n = X.shape
# 没有指定中心点时,随机初始化中心点
if initial_centroid_index is None:
np.random.seed(seed)
initial_centroid_index = np.random.randint(0, m, self.k)
centroid = X[initial_centroid_index, :]
idx = None
# 打开交互模式
plt.ion()
for i in range(max_iters):
# 按照中心点给样本分类
idx = self.find_closest_centroids(X, centroid)
if plt_process:
self.plot_converge(X, idx, initial_centroid_index)
# 重新计算中心点
centroid = self.compute_centroids(X, idx)
# 关闭交互模式
plt.ioff()
plt.show()
return centroid, idx
def find_closest_centroids(self, X, centroid):
# 这种方式利用 numpy 的广播机制,直接计算样本到各中心的距离,不用循环,速度比较快,但是在样本比较大时,更消耗内存
distance = np.sum((X[:, np.newaxis, :] - centroid) ** 2, axis=2)
idx = distance.argmin(axis=1)
return idx
def compute_centroids(self, X, idx):
centroids = np.zeros((self.k, X.shape[1]))
for i in range(self.k):
centroids[i, :] = np.mean(X[idx == i], axis=0)
return centroids
def plot_converge(self, X, idx, initial_idx):
plt.cla() # 清除原有图像
plt.title("k-meas converge process")
plt.xlabel('density')
plt.ylabel('sugar content')
plt.scatter(X[:, 0], X[:, 1], c='lightcoral')
# 标记初始化中心点
plt.scatter(X[initial_idx, 0], X[initial_idx, 1], label='initial center', c='k')
# 画出每个簇的凸包
for i in range(self.k):
X_i = X[idx == i]
# 获取当前簇的凸包索引
hull = ConvexHull(X_i).vertices.tolist()
hull.append(hull[0])
plt.plot(X_i[hull, 0], X_i[hull, 1], 'c--')
plt.legend()
plt.pause(0.5)
if __name__ == '__main__':
data = np.loadtxt('..datawatermelon4_0_Ch.txt', delimiter=', ')
centroid, idx = KMeans(3).fit(data, plt_process=True, seed=24)


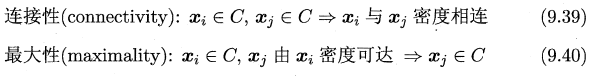
证明如下:
连接性: 由于任意 都由 密度可达,于是任意 都可通过 密度相连;
最大性: 由 密度可达,又 由 密度可达 由 密度可达 。

最小距离由两个簇的最近样本决定,最大距离由两个簇的最远样本决定。具体区别如下:
-
最大距离,可以认为是所有类别首先生成一个能包围所有类内样本的最小圆,然后所有圆同时慢慢扩大相同的半径,直到某个类圆能完全包围另一个类的所有点就停止,并合并这两个类。由于此时的圆已经包含另一个类的全部样本,所以称为全连接。
-
最小距离,可以认为是扩大时遇到第一个非自己类的点就停止,并合并这两个类。由于此时的圆只包含另一个类的一个点,所以称为单连接。

- 原型聚类:输出线性分类边界的聚类算法显然都是凸聚类,这样的算法有:K均值,LVQ;而曲线分类边界的也显然是非凸聚类,高斯混合聚类,在簇间方差不同时,其决策边界为弧线,所以高混合聚类为非凸聚类;
- 密度聚类:DBSCAN是非凸聚类;
- 层次聚类:AGENS是凸聚类。
暂无待补
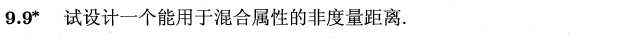
样本 的距离为: ,其中当 缺失时, ,其他情况为1;
- 当前属性 为数值类型时, ;
- 当前属性 为类别型或二元型时, 时, ,否则为 0 ;
- 当前属性 为序数型时,即 ,先将其归一化, ,然后将 作为数值属性来处理。
这里的计算其实很简单,就是把连续属性归一化;而离散属性有序时则归一化,再按照连续属性处理,无序时则相等为 1 ,不等为 0。
参考:《数据挖掘概念与技术》韩家炜,2.4节

《X-meas: Extending K-means with Efficient Estimation of the Number of Clusters》给出了一个自动确定 k 值的方法。