Hive是数据仓库,主要用来对历史数据做分析
Hive 的产生是为了帮助非java程序员做MR分析
Hive是以hdfs为基础的,所有的数据存储在hdfs上,hive的所有操作都是hdfs和MR操作
Hive的搭建主要是mysql服务的配置信息,hdfs存储数据的路径
Hive分区是为了提高查询的效率,将不同的数据文件存放到不同的目录,查询时可以查询部分目录,分区设计要跟业务相结合
下面要实现个功能
统计fof.txx中的字母个数
进入hive模式
|
数据fof.txt |
tom hello hadoop cat world hadoop hello hive cat tom hive mr hive hello hive cat hadoop world hello mr hadoop tom hive world |
|
建输入表 |
create table wc( word String ); |
|
加载数据 |
load data local inpath '/usr/local/software/fof.txt' into table wc; |
|
建输出表 |
create table wc_result( word String, ct int ); |
|
MR |
from ( select explode(split(word,' ')) word from wc) t1 insert into table wc_result select t1.word,count(t1.word) group by t1.word; |
|
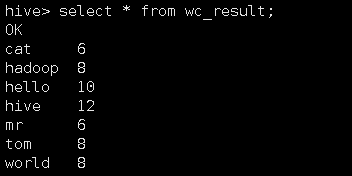
查询结果 |
Select * from wc_result; |
相关知识
hive单用户模式安装 https://www.cnblogs.com/hzcjd/p/13735795.html