一. 环境
准备4台linux虚拟机搭服务,1台pc机
三. 高可用分布式集群安装HDFS 50070
3.0部署图

|
NN-1 |
NN-2 |
DN |
ZK |
ZKFC |
JNN |
IP地址 |
|
|
Node01 |
* |
* |
* |
192.168.21.148 |
|||
|
Node02 |
* |
* |
* |
* |
* |
192.168.21.147 |
|
|
Node03 |
* |
* |
* |
192.168.21.143 |
|||
|
Node04 |
* |
* |
192.168.21.146 |
||||
3.1 hosts与profile配置
|
配置node01 |
配置node02 |
配置node03 |
配置node04 |
|
vim /etc/hosts |
|||
3.2 四台机器免登陆设置
|
配置node01 |
配置node02 |
配置node03 |
配置node04 |
||
|
ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 700 ~/.ssh chmod 600 ~/.ssh/authorized_keys |
|||||
|
ssh-copy-id root@node02 ssh-copy-id root@node03 ssh-copy-id root@node04 |
ssh-copy-id root@node01 ssh-copy-id root@node03 ssh-copy-id root@node04 |
ssh-copy-id root@node01 ssh-copy-id root@node02 ssh-copy-id root@node04 |
ssh-copy-id root@node01 ssh-copy-id root@node02 ssh-copy-id root@node03 |
||
报错
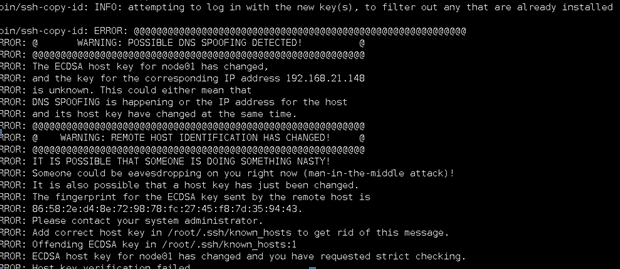
解决:

3.3解压
node01:
|
cd
/usr/local/software |
3.4配置修改
node01:
hadoop-env.sh
|
cd
/usr/local/hadoop-3.2.0-ha/etc/hadoop export HDFS_ZKFC_USER=root export HDFS_JOURNALNODE_USER=root |
core-site.xml
|
cd /usr/local/hadoop-3.2.0-ha/etc/hadoop <property> <name>fs.defaultFS</name> <value>hdfs://mycluster </value> </property> <property> <name>hadoop.tmp.dir</name> <value>/var/sxt/hadoop/ha</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>node02:2181,node03:2181,node04:2181</value> </property> |
hdfs-site.xml
|
cd
/usr/local/hadoop-3.2.0-ha/etc/hadoop <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>node01:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>node02:8020</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>node01:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>node02:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/var/sxt/hadoop/ha/jn</value> </property> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_dsa</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> |
workers
|
cd /usr/local/hadoop-3.2.0-ha/etc/hadoop vim workers node02 node03 node04 |
分发
|
cd /usr/local scp -r hadoop-3.2.0-ha jdk node02:`pwd` scp -r hadoop-3.2.0-ha jdk node03:`pwd` scp -r hadoop-3.2.0-ha jdk node04:`pwd` cd /etc scp profile node02:`pwd` scp profile node03:`pwd` scp profile node04:`pwd` source /etc/profile 所有机器均执行 |
3.5 NameNode同步穿透
1>Node01格式化
|
Node01 |
Node02 |
Node03 |
|
cd /usr/local/hadoop-3.2.0-ha/bin ./hdfs --daemon start journalnode |
||
|
cd /usr/local/hadoop-3.2.0-ha/bin ./hdfs namenode -format |
||
2>查看Nod01版本
cd /var/sxt/hadoop/ha/dfs/name/current
cat V*

3>同步
启动node01的NameNode
|
Node01: ./hadoop-daemon.sh start namenode |
Nod02同步
|
Node02: ./hdfs namenode -bootstrapStandby |
2>查看Nod02版本
cd /var/sxt/hadoop/ha/dfs/name/current
cat V*

3.6 zk格式化
node02,node03,node04机器上安装zookeeper集群,并启动。略
|
cd /usr/local/zookeeper/bin ./zkServer.sh start |
Node01机器zk格式化
|
Node01: cd /usr/local/hadoop-3.2.0-ha/bin ./hdfs zkfc -formatZK |
3.7启动
|
Node01: cd /usr/local/hadoop-3.2.0-ha/sbin ./start-dfs.sh |
3.8登录验证
一台standby 一台active说明开启成功
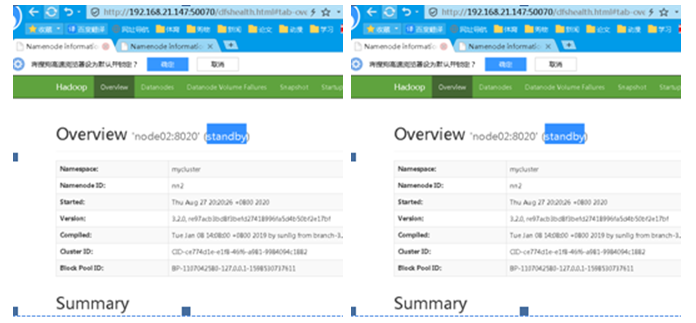
进入zk客户端,注册节点位置如下图

3.9开机自启
|
Node01 |
Node02 |
Node03 |
Node04 |
|
vim /etc/rc.local cd /usr/local/hadoop-3.2.0-ha/sbin ./start-dfs.sh :wq source /etc/rc.local chmod +x /etc/rc.local |
vim /etc/rc.local cd /usr/local/zookeeper/bin ./zkServer.sh start :wq source /etc/rc.local chmod +x /etc/rc.local |
||
四. 高可用分布式安装Yarn 8088
4.0部署图
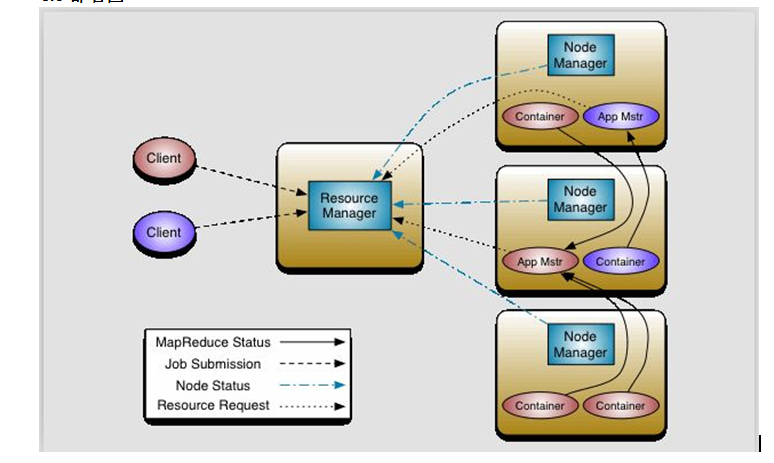
|
NN-1 |
NN-2 |
DN |
ZK |
ZKFC |
JNN |
RS |
NM |
IP地址 |
|
|
Node01 |
* |
* |
* |
192.168.21.148 |
|||||
|
Node02 |
* |
* |
* |
* |
* |
* |
192.168.21.147 |
||
|
Node03 |
* |
* |
* |
* |
* |
192.168.21.143 |
|||
|
Node04 |
* |
* |
* |
* |
192.168.21.146 |
4.1配置修改
hadoop-env.sh
|
cd /usr/local/hadoop-3.2.0-ha/etc/hadoop export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export HDFS_ZKFC_USER=root export HDFS_JOURNALNODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root |
mapred-site.xml
|
cd /usr/local/hadoop-3.2.0-ha/etc/hadoop/mapred-site.xml vim mapred-site.xml configuration中录入 <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value> /usr/local/hadoop-3.2.0-ha/etc/hadoop, /usr/local/hadoop-3.2.0-ha/share/hadoop/common/*, /usr/local/hadoop-3.2.0-ha/share/hadoop/common/lib/*, /usr/local/hadoop-3.2.0-ha/share/hadoop/hdfs/*, /usr/local/hadoop-3.2.0-ha/share/hadoop/hdfs/lib/*, /usr/local/hadoop-3.2.0-ha/share/hadoop/mapreduce/*, /usr/local/hadoop-3.2.0-ha/share/hadoop/mapreduce/lib/*, /usr/local/hadoop-3.2.0-ha/share/hadoop/yarn/*, /usr/local/hadoop-3.2.0-ha/share/hadoop/yarn/lib/* </value> </property> |
yarn-site.xml
|
cd /usr/local/hadoop-3.2.0-ha/etc/hadoop/ vim yarn-site.xml configuration中录入 <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_HOME</value> </property> <!--启用ResourceManager的高可用--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--指代ResourceManager HA的两台RM的逻辑名称 --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>rmhacluster1</value> </property> <!--指定该高可用ResourceManager下的两台ResourceManager的逻辑名称--> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!--指定第一台ResourceManager服务器所在的主机名称 --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>node03</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>node04</value> </property> <!--指定resourcemanager的web服务器的主机名和端口号--> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>node03:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>node04:8088</value> </property> <!--做ResourceManager HA故障切换用到的zookeeper集群地址 --> <property> <name>yarn.resourcemanager.zk-address</name> <value>node02:2181,node03:2181,node04:2181</value> </property> |
分发
|
cd /usr/local/hadoop-3.2.0-ha/etc/hadoop/ scp -r yarn-site.xml mapred-site.xml hadoop-env.sh node02:`pwd`scp -r yarn-site.xml mapred-site.xml hadoop-env.sh node03:`pwd`scp -r yarn-site.xml mapred-site.xml hadoop-env.sh node04:`pwd` |
4.2启动
|
Node01: cd /usr/local/hadoop-3.2.0-ha/sbin ./start-yarn.sh |
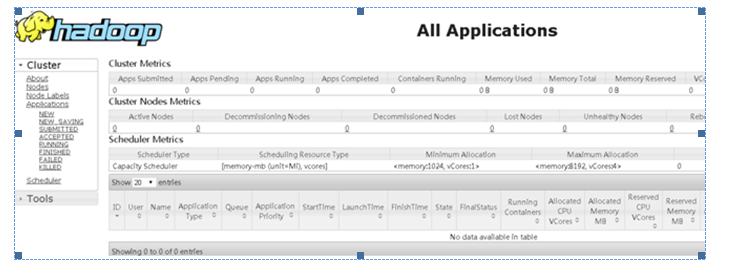
4.3登录验证
http:192.168.143.8088
工具下载