信息熵:
生活中的所见所闻,都接触到许许多多的信息,有的信息对我们有用,有的无用。如 “地球是自转的”,这条信息对我们没什么用,因为我们都知道,而且是确确实实是这样的。香农用信息熵的概念来描述信源的不确定度,变量的不确定性越大,熵也就越大。
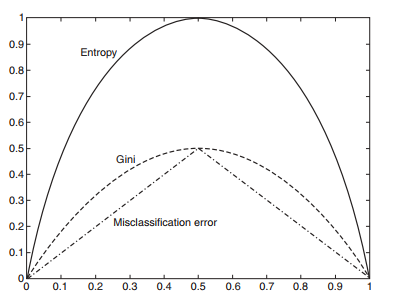
在某个事件中,如果不发生的概率为0,那么可以确定信息熵为0,当发生的概率为1时,属于确定性事件,同样信息熵为0。只有当发生的概率为0.5 时,不确定程度则越大,熵也就越大。(如下图,x轴为发生的概率,y轴为熵)
计算信息熵公式:(通常以2为对数底数)
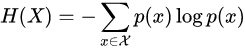
其中 p(xi) 代表随机事件X为 xi 的概率。
条件熵:在满足某个条件下,随机变量的不确定性。

信息增益:信息增益是特征选择的一个重要指标,表示在某个条件下,信息不确定性的减少程度。
简单来说:信息增益 = 信息熵 - 条件熵
决策树的构建,是基于 ID3算法 或 C4.5算法。
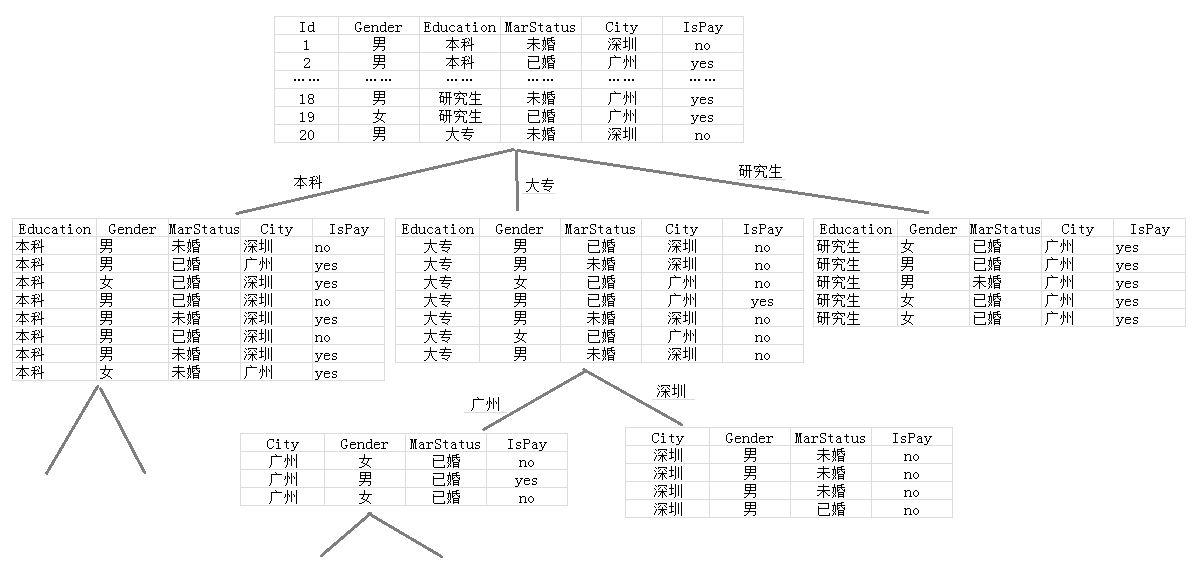
示例: 通过信息增益构建分类决策树
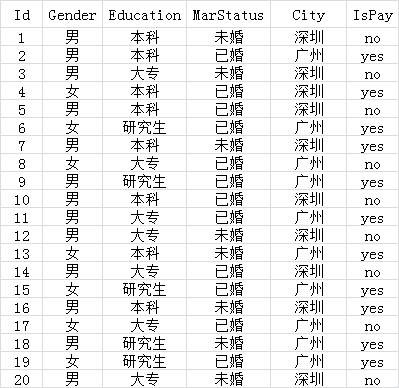
其中,Gender,Education,MarStatus,City 为分类特征,IsPay 为结果。IsPay 中, “no” 个数为9,“yes” 个数为11。
即概率 p(Ispay = no) = 9 / 20 , p(Ispay = yes) = 11 / 20, 套用信息熵公式,计算 IsPay 的信息熵。
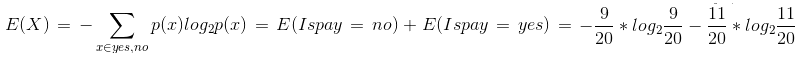
结果为:E(IsPay) = 0.992774453987808
现在以性别为例,计算信息熵和信息增益:
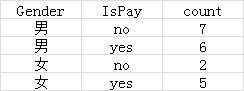
男性的信息熵为:0.995727899051793
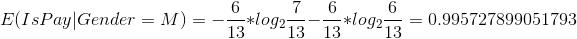
女性的信息熵为:0.863121148140382
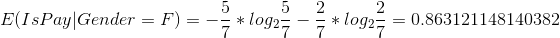
该性别平均熵为:0.949315536232799
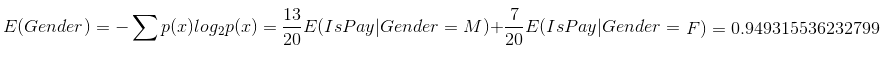
信息增益为:0.043458917755009

同样方法,将 Education,MarStatus,City 都计算出来,结果如下:
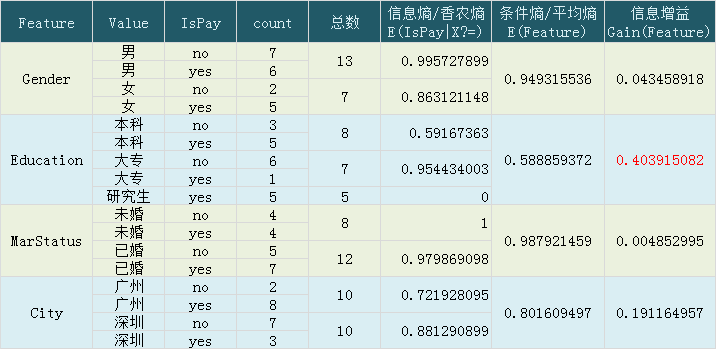
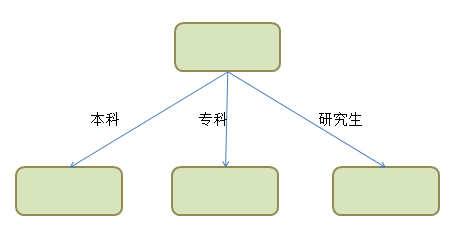
可以看到,学历 Education 的信息增益是最大的,数据集将以 Education 为条件,划分到三个子集。树型结构如下:
数据集如下:
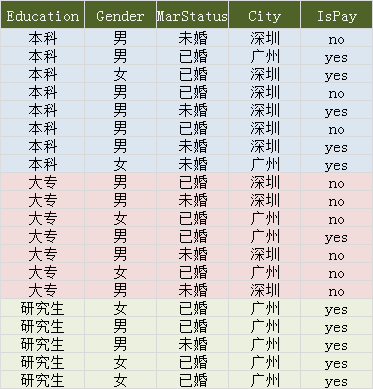
可以看到 学历为 “研究生” 的节点, Ispay 都为 “yes” ,纯度很高,不需要再划分了。即当学历为研究生时,Ispay=‘yes’ 的概率为1。
数的第一层确定了,现在构建第二层,已学历为大专为例。计算结果如下:
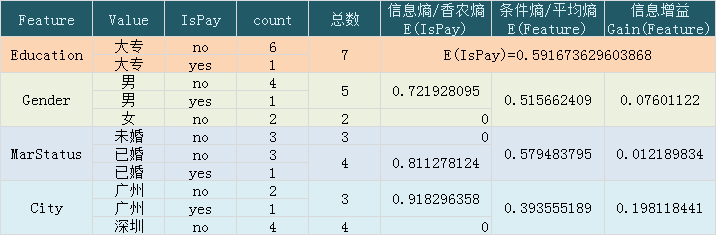
在这个层级节点中, City 的信息增益最大,接下来将以城市来划分节点。
决策树构建结果如下:
更多参考:
信息熵:https://www.zhihu.com/question/22178202