SENet&语义分割相关知识学习
对上一次学习的 HybridSN 高光谱分类网络进行优化改进;SENet网络学习和实现;学习视频北京大学李夏的《语义分割中的自注意力机制和低秩重重建》 , 南开大学程明明教授的《图像语义分割前沿进展》
HybridSN 高光谱分类网络的优化改进
关于DropOut使用
- 在上一次的实验代码中,因为使用了DropOut,所以需要对应使用net.train()和net.eval()函数
- model.train() 让model变成训练模式,此时 dropout和batch normalization的操作在训练过程中发挥作用,防止网络过拟合的问题
- net.eval(): 把BN和DropOut固定住,不会取平均,而是用训练好的值
- 这样的话,在测试过程中,由于网络参数都已经固定,所以每次的测试结果也都会保持一致
- 准确率在95.5%左右
模型改进——先使用二位卷积,在使用三位卷积
# 模型改进——先使用二位卷积,在使用三位卷积
class_num = 16
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
# 二维卷积:原始输入(30, 25, 25) 64个 3x3x30 的卷积核,得到 (64, 23, 23)
self.conv4_2d = nn.Sequential(
nn.Conv2d(30,64,(3,3)),
nn.BatchNorm2d(64),
nn.ReLU()
)
# 三个三维卷积
# conv1:(1, 64, 23, 23), 8个 7x3x3 的卷积核 ==> (8, 58, 21, 21)
self.conv1_3d = nn.Sequential(
nn.Conv3d(1,8,(7,3,3)),
nn.BatchNorm3d(8),
nn.ReLU()
)
# conv2:(8, 58, 21, 21), 16个 5x3x3 的卷积核 ==> (16, 54, 19, 19)
self.conv2_3d = nn.Sequential(
nn.Conv3d(8,16,(5,3,3)),
nn.BatchNorm3d(16),
nn.ReLU()
)
# conv3:(16, 54, 19, 19), 32个 5x3x3 的卷积核 ==> (32, 52, 17, 17)
self.conv3_3d = nn.Sequential(
nn.Conv3d(16,32,(3,3,3)),
nn.BatchNorm3d(32),
nn.ReLU()
)
self.fn1 = nn.Linear(480896,256)# 32*52*17*17,这里可以运行一下,print一下out.size()
self.fn2 = nn.Linear(256,128)
self.fn_out = nn.Linear(128,class_num)
self.drop = nn.Dropout(p = 0.4)
# emm我在这里使用了softmax之后,网络在训练过程中loss就不再下降了,不知道具体是为啥,很奇怪,,
# self.soft = nn.Softmax(dim = 1)
def forward(self, x):
# 先降到二维
out = x.view(x.shape[0],x.shape[2],x.shape[3],x.shape[4])
out = self.conv4_2d(out)
# 升维(64, 23, 23)-->(1,64, 23, 23)
out = out.view(out.shape[0],1,out.shape[1],out.shape[2],out.shape[3])
out = self.conv1_3d(out)
out = self.conv2_3d(out)
out = self.conv3_3d(out)
# 进行重组,以b行,d列的形式存放(d自动计算)
out = out.view(out.shape[0],-1)
out = self.fn1(out)
out = self.drop(out)
out = self.fn2(out)
out = self.drop(out)
out = self.fn_out(out)
return out
# 随机输入,测试网络结构是否通
x = torch.randn(1,1, 30, 25, 25)
net = HybridSN()
y = net(x)
print(y.shape)
print(y)
- 由于先使用二维卷积,原始输入(30, 25, 25) 经过64个 3x3x30 的卷积核,得到 (64, 23, 23),在进行三维卷积,可以明显看到参数量的增加,所以整个网络模型的训练时间也会相应变长,不过也是可以看到准确率的提升
- 准确率在97.3%左右
引入注意力机制
# 引入注意力机制
class_num = 16
class Attention_Block(nn.Module):
def __init__(self, planes, size):
super(Attention_Block, self).__init__()
self.globalAvgPool = nn.AvgPool2d(size, stride=1)
self.fc1 = nn.Linear(planes, round(planes / 16))
self.relu = nn.ReLU()
self.fc2 = nn.Linear(round(planes / 16), planes)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
residual = x
out = self.globalAvgPool(x)
out = out.view(out.shape[0], out.shape[1])
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
out = self.sigmoid(out)
out = out.view(out.shape[0], out.shape[1], 1, 1)
out = out * residual
return out
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
# 3个3D卷积
# conv1:(1, 30, 25, 25), 8个 7x3x3 的卷积核 ==> (8, 24, 23, 23)
self.conv1_3d = nn.Sequential(
nn.Conv3d(1,8,(7,3,3)),
nn.BatchNorm3d(8),
nn.ReLU()
)
# conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21)
self.conv2_3d = nn.Sequential(
nn.Conv3d(8,16,(5,3,3)),
nn.BatchNorm3d(16),
nn.ReLU()
)
# conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19)
self.conv3_3d = nn.Sequential(
nn.Conv3d(16,32,(3,3,3)),
nn.BatchNorm3d(32),
nn.ReLU()
)
# 二维卷积:(576, 19, 19) 64个 3x3 的卷积核,得到 (64, 17, 17)
self.conv4_2d = nn.Sequential(
nn.Conv2d(576,64,(3,3)),
nn.BatchNorm2d(64),
nn.ReLU()
)
# 注意力机制部分
self.layer1 = self.make_layer(Attention_Block,planes = 576, size = 19)
self.layer2 = self.make_layer(Attention_Block,planes = 64, size = 17)
# 接下来依次为256,128节点的全连接层,都使用比例为0.1的 Dropout
self.fn1 = nn.Linear(18496,256)
self.fn2 = nn.Linear(256,128)
self.fn_out = nn.Linear(128,class_num)
self.drop = nn.Dropout(p = 0.1)
# emm我在这里使用了softmax之后,网络在训练过程中loss就不再下降了,不知道具体是为啥,很奇怪,,
# self.soft = nn.Softmax(dim = 1)
def make_layer(self, block, planes, size):
layers = []
layers.append(block(planes, size))
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1_3d(x)
out = self.conv2_3d(out)
out = self.conv3_3d(out)
# 进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19)
out = out.view(out.shape[0],out.shape[1]*out.shape[2],out.shape[3],out.shape[4])
# 在二维卷积部分引入注意力机制
out = self.layer1(out)
out = self.conv4_2d(out)
out = self.layer2(out)
# 接下来是一个 flatten 操作,变为 18496 维的向量
# 进行重组,以b行,d列的形式存放(d自动计算)
out = out.view(out.shape[0],-1)
out = self.fn1(out)
out = self.drop(out)
out = self.fn2(out)
out = self.drop(out)
out = self.fn_out(out)
# out = self.soft(out)
return out
# 随机输入,测试网络结构是否通
x = torch.randn(1, 1, 30, 25, 25)
net = HybridSN()
y = net(x)
print(y.shape)
print(y)
- 可以明显感觉到网络在训练过程中能够很快的收敛,并且整个网络的训练过程也十分稳定,最终测试结果可以达到99%左右

SENet
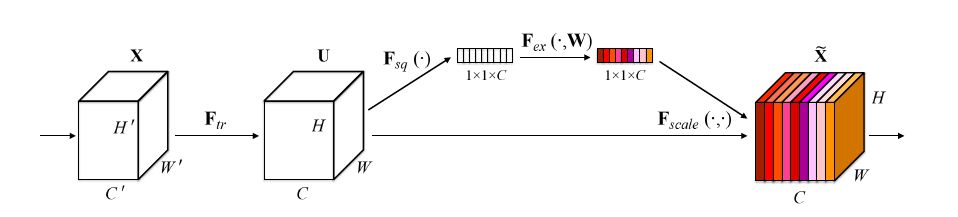
其中心思想:对当前的输入特征图的每一个channel,进行一个 Squeeze 操作得到一个权重值,然后将这个权重值与对应channel进行乘积操作,对每个channel进行加权操作,从而得到新的特征图
!
网络结构
- (X--> U)
- (F_{tr})是传统的卷积操作
- (U--> widetilde X)
- Squeeze --(F_{sq}(·))
- 先对U中的每一个channel做一个 Global Average Pooling 操作,然后可以得到一个1x1xC的数据
- 将整个通道上的值进行平均化操作,便能够基于通道的整体信息来计算scale
- 因为这里作者是想要得到各channel之间的分布关联,所以这里虽然屏蔽了每个channel中空间分布中的相关性,但无关大雅
- 用来表明该层C个feature map的数值分布情况
- 先对U中的每一个channel做一个 Global Average Pooling 操作,然后可以得到一个1x1xC的数据
- Excitation --(F_{ex}(·,W))
- (s = F_{es}(z,W) = sigma(g(z,W)) = sigma(W_2delta(W_1z) ))
- 将得到的1x1xC数据先进行一个全连接层操作, 其中(W_1)的维度是C * C/r
- 这个r是一个缩放参数,在文中取的是16,这个参数的目的是为了减少channel个数从而降低计算量
- 这里使用全连接层是为了充分利用通道间的相关性来得到需要的一个权重参数
- 然后经过一个ReLU层
- 接着在经过一个全连接层操作,其中(W_2)的维度是C/r * C
- 最后通过sigmoid 将最终权重限制到[0,1]的范围
- 最后将这个值s作为scale乘到U的每个channel上
- Squeeze --(F_{sq}(·))
- 通过控制scale的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强
- 作者还给出了两种实际应用的例子
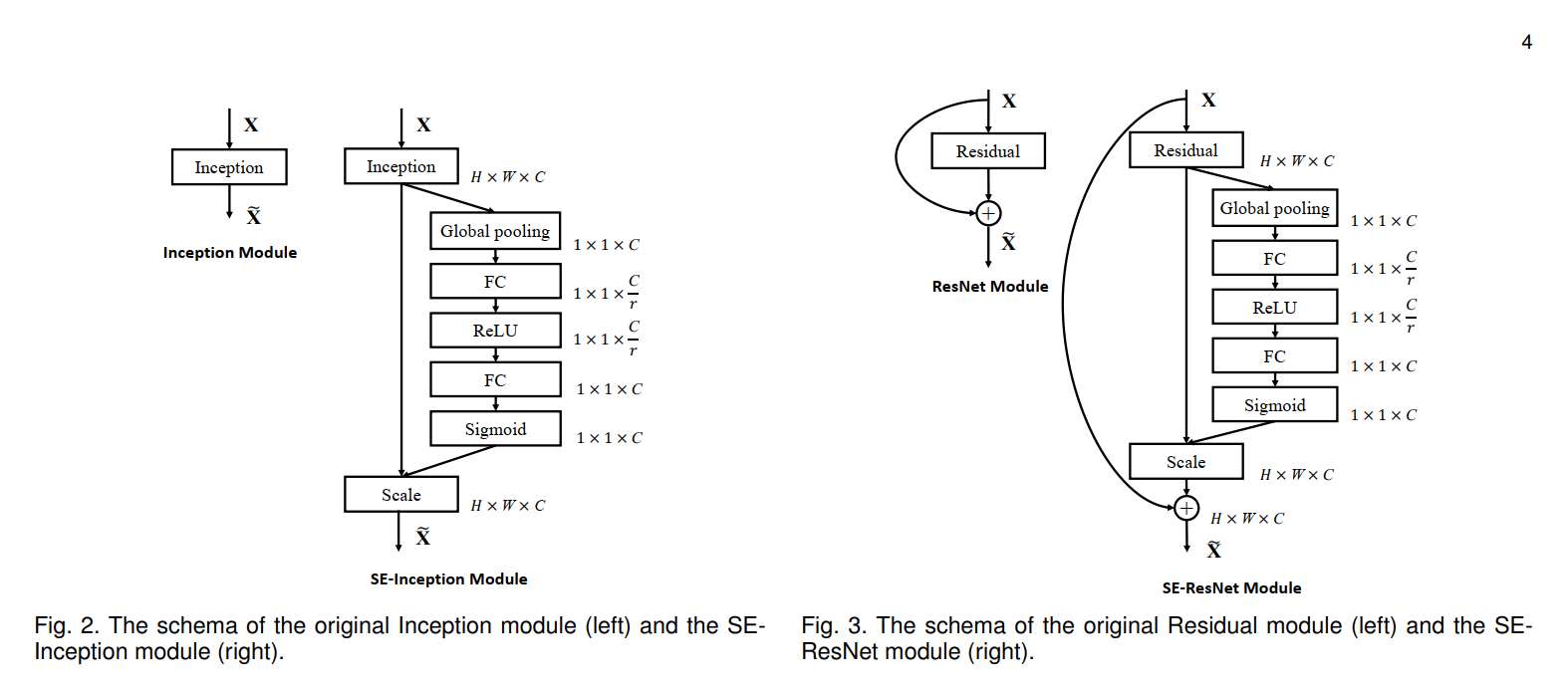
代码实现
其实现代码来自链接
import torch.nn as nn
import math
import torch.utils.model_zoo as model_zoo
__all__ = ['SENet', 'se_resnet_18', 'se_resnet_34', 'se_resnet_50', 'se_resnet_101',
'se_resnet_152']
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
if planes == 64:
self.globalAvgPool = nn.AvgPool2d(56, stride=1)
elif planes == 128:
self.globalAvgPool = nn.AvgPool2d(28, stride=1)
elif planes == 256:
self.globalAvgPool = nn.AvgPool2d(14, stride=1)
elif planes == 512:
self.globalAvgPool = nn.AvgPool2d(7, stride=1)
self.fc1 = nn.Linear(in_features=planes, out_features=round(planes / 16))
self.fc2 = nn.Linear(in_features=round(planes / 16), out_features=planes)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
original_out = out
out = self.globalAvgPool(out)
out = out.view(out.size(0), -1)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
out = self.sigmoid(out)
out = out.view(out.size(0), out.size(1), 1, 1)
out = out * original_out
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
if planes == 64:
self.globalAvgPool = nn.AvgPool2d(56, stride=1)
elif planes == 128:
self.globalAvgPool = nn.AvgPool2d(28, stride=1)
elif planes == 256:
self.globalAvgPool = nn.AvgPool2d(14, stride=1)
elif planes == 512:
self.globalAvgPool = nn.AvgPool2d(7, stride=1)
self.fc1 = nn.Linear(in_features=planes * 4, out_features=round(planes / 4))
self.fc2 = nn.Linear(in_features=round(planes / 4), out_features=planes * 4)
self.sigmoid = nn.Sigmoid()
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
original_out = out
out = self.globalAvgPool(out)
out = out.view(out.size(0), -1)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
out = self.sigmoid(out)
out = out.view(out.size(0),out.size(1),1,1)
out = out * original_out
out += residual
out = self.relu(out)
return out
class SENet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(SENet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def se_resnet_18(pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = SENet(BasicBlock, [2, 2, 2, 2], **kwargs)
return model
def se_resnet_34(pretrained=False, **kwargs):
"""Constructs a ResNet-34 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = SENet(BasicBlock, [3, 4, 6, 3], **kwargs)
return model
def se_resnet_50(pretrained=False, **kwargs):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = SENet(Bottleneck, [3, 4, 6, 3], **kwargs)
return model
def se_resnet_101(pretrained=False, **kwargs):
"""Constructs a ResNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = SENet(Bottleneck, [3, 4, 23, 3], **kwargs)
return model
def se_resnet_152(pretrained=False, **kwargs):
"""Constructs a ResNet-152 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = SENet(Bottleneck, [3, 8, 36, 3], **kwargs)
return model
语义分割中的自注意力机制和低秩重重建
语义分割
!
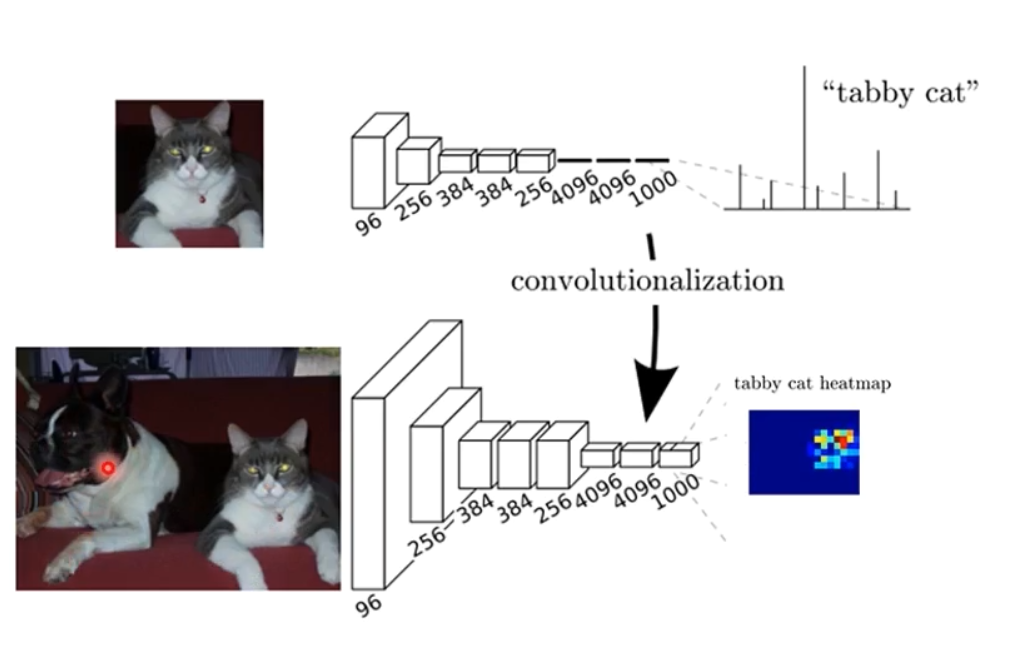
- 原始的网络主要进行图像分类,通过卷积层+全连接层得到最后的一个分类结果
- 当网络的最后几层,依旧采用卷积层,再通过上采样输出一个nxn的结果输出
- 全卷积网络,无论卷积核多大,总是收到感受野大小的限制
- 而进行语义分割,需要更大的感受野范围
Nonlocal Networks
-
对于卷积神经网络的感受野,其大小就是卷积核的大小,只考虑局部区域,因此是local的,而 non-local指的就是感受野可以很大,而不是一个局部领域 (全连接层就是non-local的)
-
预测一个物体的信息,需要尽可能多的采集整个图像中各个位置的信息,考虑当前像素点和其他像素点的关联信息
- 即利用两个点的相似性对每个位置的特征做加权
- $y_i = frac1{C(x)} sum_{ forall j}f(x_i,x_j)g(x_j) $
- (f(x_,x_j) = e^{ heta(x_i)^T phi(x_j)}) 表示 (x_i) 和 (x_j) 的相关度计算,C(x)表示一个归一化操作,(g(x_j))表示参考像素的变换
-
实现原理如图:
-
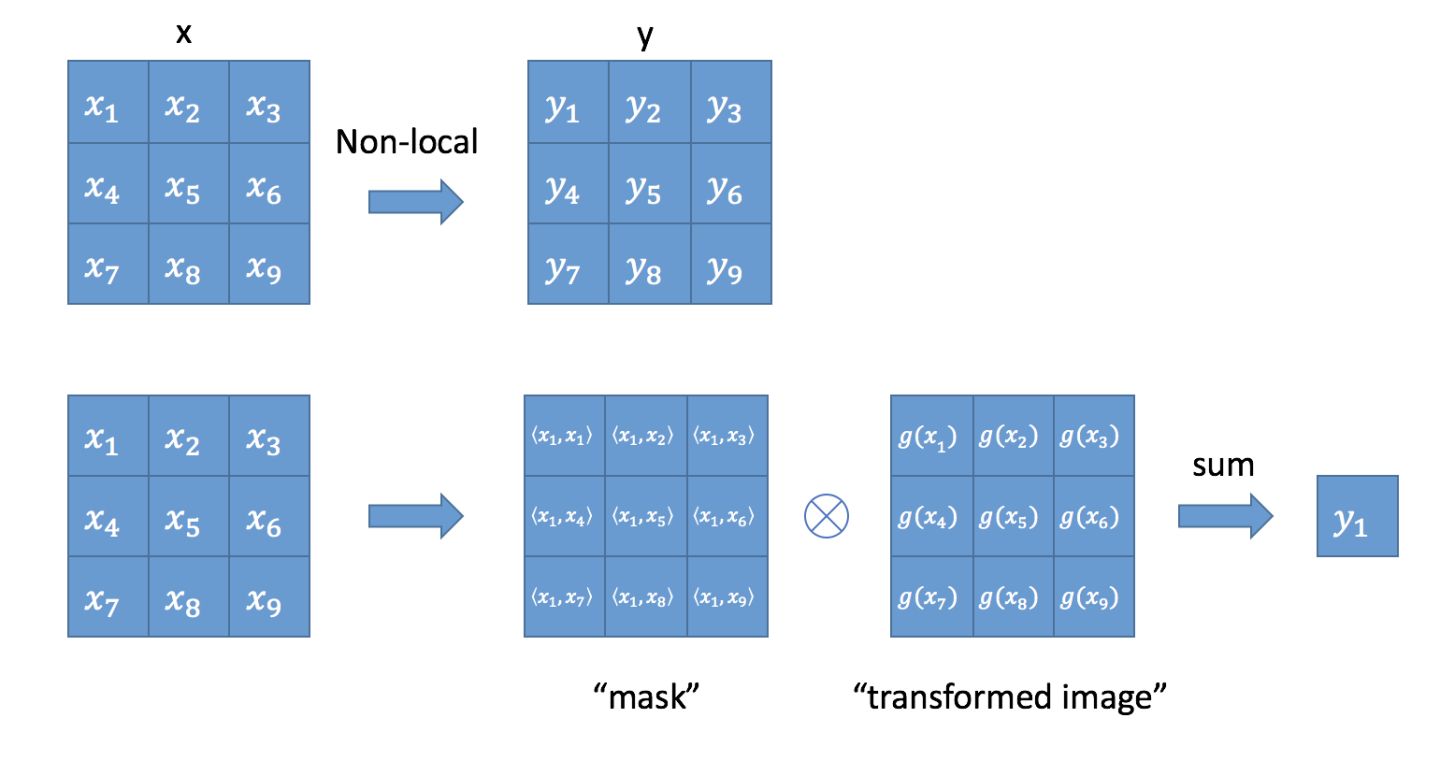
-
其相似度的计算有多种方法,不过差异不大,选了一个好操作的
-
其中Embedding的实现方式,以图像为例,在文章中都采用1*1的卷积 ,即 ( heta) 和(phi) 都是1x1卷积操作。
-
- (z_i = W_zy_i + x_i)
- 构成一个残差模型
- 这样也成了一个block组件,可以直接插入到神经网络中
- 实验也证明了这些结构其存在的必要性和有效性
- 与全连接层的关联
- 当两个点之间不再根据位置信息计算相似性,而是直接运算
- (g(x_j) = x_j)
- 归一化系数为1
- 那么就成了全连接层,可以将全连接层理解为non-local的一个特例
-
其具体实现如下:
-
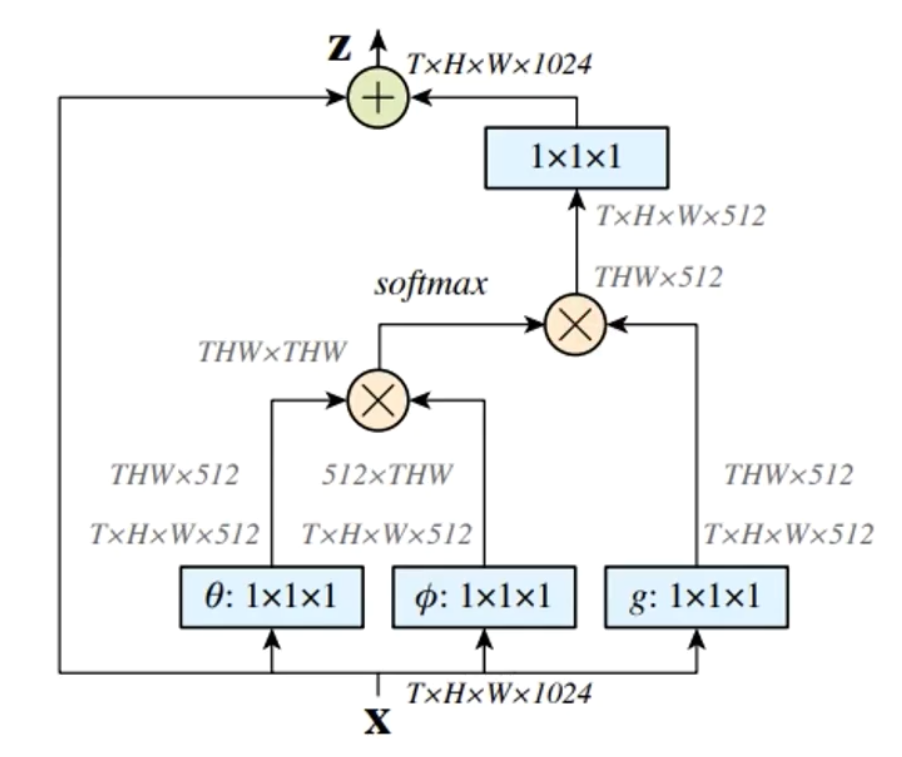
- 不过当输入feature map的尺寸很大时,其non-local的计算量会很庞大,因此只在比较深的网络层(高阶语义层)上使用
图像语义分割前沿进展
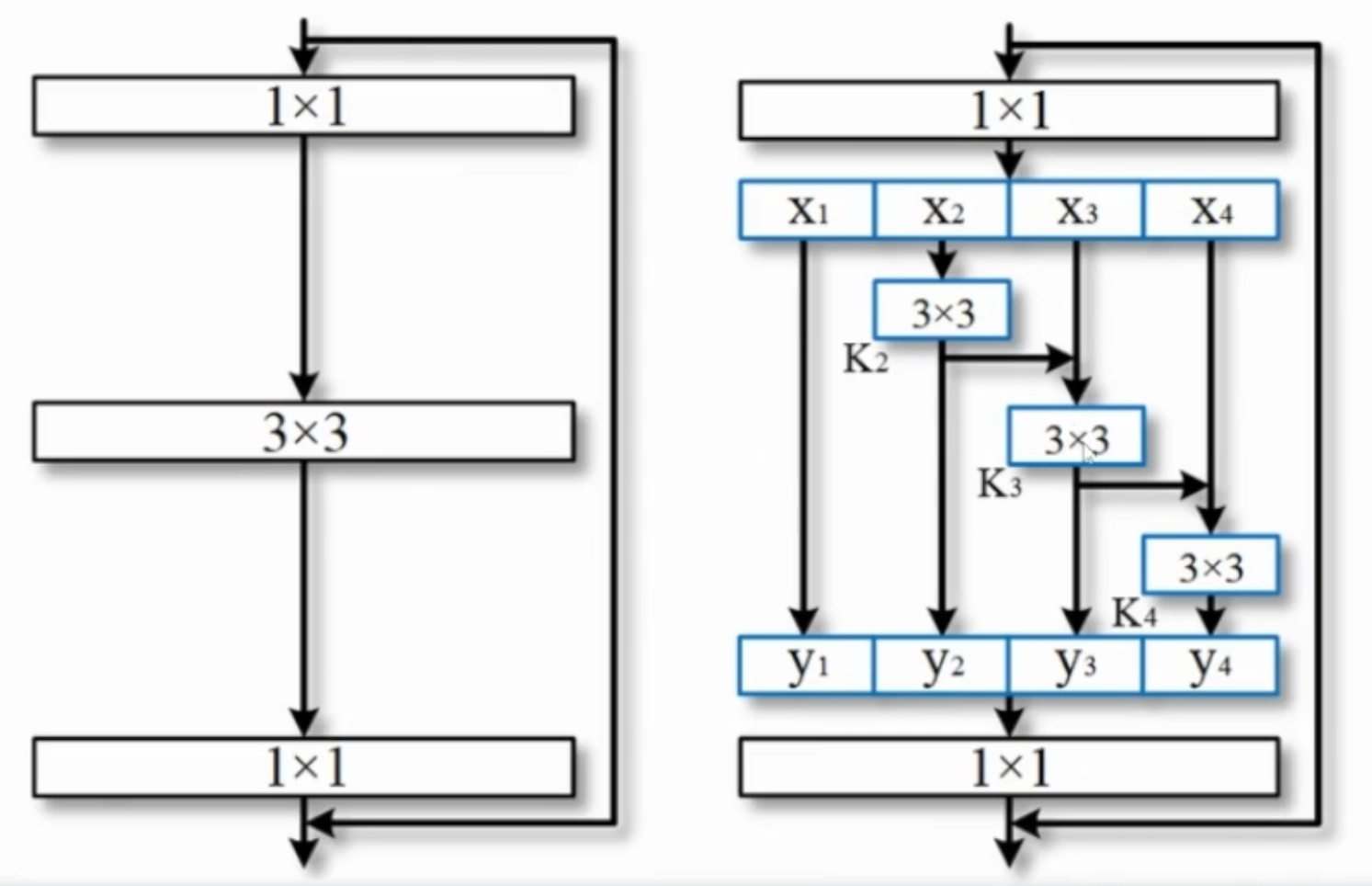
Res2Net
- 为了更好的利用多尺度信息,在一个ResNet block中,再次进行多尺度信息的分割,从而充分利用尺度信息
Strip Pooling
- 带状池化
- 传统的标准pooling多是方形,而实际场景中会有一些物体是长条形,因此希望尽可能捕获一个long-range的特征
- 把标准的spatial pooling的kernel的宽或高置为1,然后每次取所有水平元素或垂直元素相加求平均
- SP模块
-
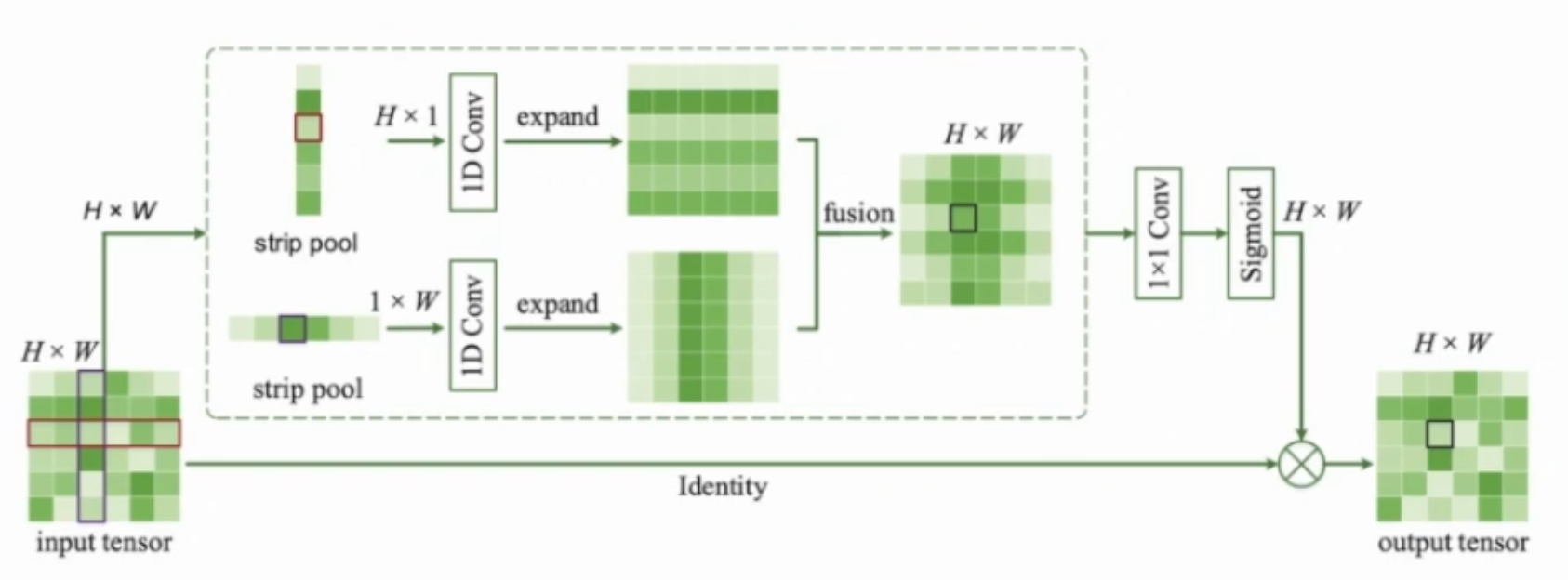
- 对于一个输入x(HxW), 用两个pathway 分别处理水平和垂直的strip pooling,然后再expand到输入的原尺寸 (HxW)
- 然后将两个pathway的结果相加进行融合 ,再用1x1卷积进行降维,最后使用sigmoid激活
- 不过感觉上面的处理部分像是计算得到了一个权重矩阵,得到了每个像素位置的权重分布情况,这样理解起来,有点像SENet的注意力机制。。
-
同时其中任意两个像素点之间的信息也可以通过这种类似桥接的方式得到连接,从而获得更多的全局信息
-