第一周:深度学习及pytorch基础
视频学习
由于之前在跟随老师完成本科毕业设计的时候,已经对相关视频进行过学习,所以就不再单独写这一部分的笔记了,可以直接查看之前的学习笔记:链接
代码练习
螺旋数据分类
(贴一些感觉比较关键的代码部分)
# 得到一组随机数
seed = 12345
random.seed(seed)
torch.manual_seed(seed)
N = 1000 # 每类样本的数量
D = 2 # 每个样本的特征维度
C = 3 # 样本的类别
H = 100 # 神经网络里隐层单元的数量
X = torch.zeros(N * C, D).to(device) # X:样本总数*样本的维度特征(2)
Y = torch.zeros(N * C, dtype=torch.long).to(device) # Y:样本总数
# 将这些随机数据构成螺旋形
for c in range(C):
index = 0
t = torch.linspace(0, 1, N)
inner_var = torch.linspace( (2*math.pi/C)*c, (2*math.pi/C)*(2+c), N) + torch.randn(N) * 0.2
# 将当前的数据分布可视化
# 每个样本的(x,y)坐标(即维度特征D)都保存在 X 里
# Y 里存储的是样本的类别,分别为 [0, 1, 2],图中用不同颜色表示
for ix in range(N * c, N * (c + 1)):
X[ix] = t[index] * torch.FloatTensor((math.sin(inner_var[index]), math.cos(inner_var[index])))
Y[ix] = c
index += 1

线性模型
learning_rate = 1e-3
lambda_l2 = 1e-5
# nn 包用来创建线性模型
# 每一个线性模型都包含 weight 和 bias
# 没有激活函数,直接将输入层与隐含层连接,然后隐含层与输出层相连得到输出
model = nn.Sequential(
nn.Linear(D, H),
nn.Linear(H, C)
)
model.to(device) # 把模型放到GPU上
# nn 包含多种不同的损失函数,这里使用的是交叉熵(cross entropy loss)损失函数
criterion = torch.nn.CrossEntropyLoss()
# 这里使用 optim 包进行随机梯度下降(stochastic gradient descent)优化
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
# 开始训练
for t in range(1000):
# 把数据输入模型,得到预测结果
y_pred = model(X)
# 计算损失和准确率
loss = criterion(y_pred, Y) # Y中包含真实结果值
score, predicted = torch.max(y_pred, 1)
acc = (Y == predicted).sum().float() / len(Y)
print('[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f' % (t, loss.item(), acc))
display.clear_output(wait=True)
# 反向传播前把梯度置 0
# pytorch默认会对梯度进行累加,不过这里每次训练都是相对独立的,不需要上一次的梯度数据
optimizer.zero_grad()
# 反向传播优化,计算当前梯度
loss.backward()
# 更新全部参数
optimizer.step()
# 最后的训练结果保存在y_pred(样本总数*样本的类别数)中,在每一个样本(行)中,包含了属于每一类别(列)的可能性,其中最大的就是最终得到的预测值。
# 由于是一个简单的线性模型,输入输出之间只是简单的线性组合,所以效果较差,可以看到预测结果
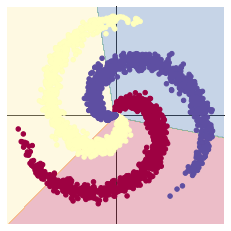
两层神经网络结构
model = nn.Sequential(
nn.Linear(D, H),
nn.ReLU(),
nn.Linear(H, C)
)
# 使用了激活函数,引入非线性函数,由于不是简单的线性组合,通过这种方式,神经网络几乎可以逼近任何函数
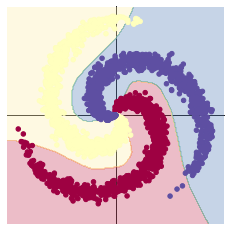
回归分析
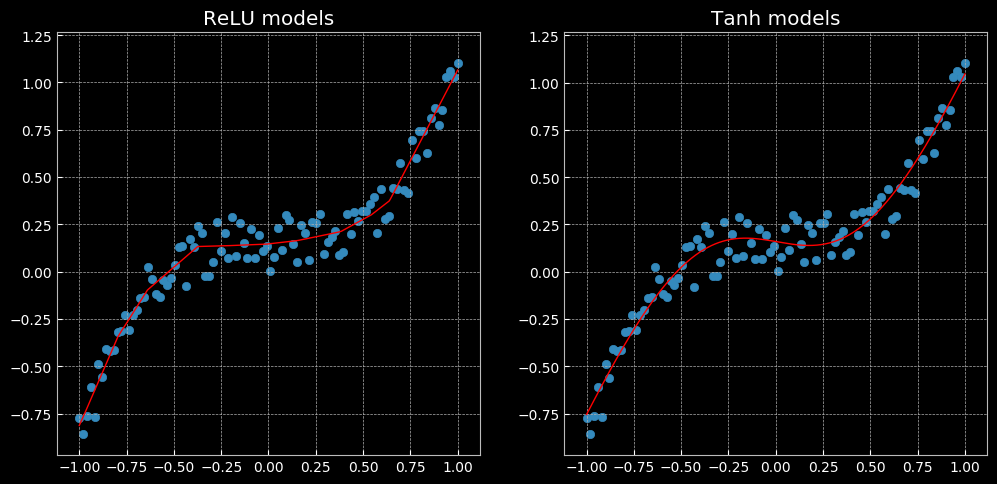
代码给出了使用ReLu激活和Tanh激活的两种模型,而最终得到的结果有很大的不同,其主要原因感觉是因为ReLu激活函数不能很好的处理负数部分,将负数部分直接抛弃,从而导致出现了这样较为曲折的情况。
进阶练习
数据处理部分
这部分为 Kaggle 于 2013 年举办的猫狗大战竞赛,使用在 ImageNet 上预训练的 VGG 网络进行测试。因为原网络的分类结果是1000类,所以这里进行迁移学习,对原网络进行 fine-tune (即固定前面若干层,作为特征提取器,只重新训练最后两层)。
仔细研读AI研习社猫狗大战赛题的要求:https://god.yanxishe.com/41 (目前比赛已经结束,但仍可做为练习赛每天提交测试结果)
下载比赛的测试集(包含2000张图片),利用fine-tune的VGG模型进行测试,按照比赛规定的格式输出,上传结果评测(练习赛每天仅可评测5次)。我已进行测试,VGG模型训练 1 个 epoch 的准确率约为 96.1 %。
在这一部分,老师已经给出了主要的代码框架,所以只需要针对猫狗大战的具体要求进行部分修改即可。
import numpy as np
import matplotlib.pyplot as plt
import os
import torch
import torch.nn as nn
import torchvision
from torchvision import models,transforms,datasets
import time
import json
# 判断是否存在GPU设备,记得打开colab的gpu,不然默认使用cpu跑,特别慢
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('Using gpu: %s ' % torch.cuda.is_available())
下载AI研习社的数据集
! wget https://static.leiphone.com/cat_dog.rar
# 解压rar压缩包,需要安装rarfile库(pip install rarfile)
import rarfile
path = "cat_dog.rar"
path2 = "/content/"
rf = rarfile.RarFile(path) #待解压文件
rf.extractall(path2) #解压指定文件路径
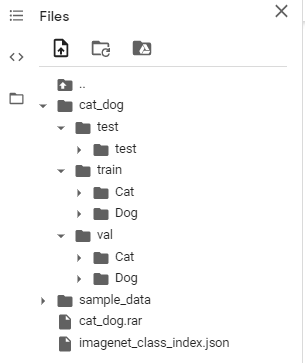
由于下载的该数据集的文件存储结构与pytorch的规范格式不太一样,所以先对数据集进行一些整理操作。
mkdir cat_dog/val/Dog
mkdir cat_dog/val/Cat
mkdir cat_dog/train/Cat
mkdir cat_dog/train/Dog
mkdir cat_dog/test/test
mv cat_dog/val/dog* cat_dog/val/Dog/
mv cat_dog/val/cat* cat_dog/val/Cat/
mv cat_dog/train/cat* cat_dog/train/Cat/
mv cat_dog/train/dog* cat_dog/train/Dog/
mv cat_dog/test/*.jpg cat_dog/test/test
最终得到的文件结构如下:
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
vgg_format_train = transforms.Compose([
transforms.RandomRotation(30),# 随机旋转
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
vgg_format = transforms.Compose([
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
data_dir = './cat_dog/'
# 利用ImageFolder进行分类文件夹加载
# train_sets = torchvision.datasets.ImageFolder('./cat_dog/train',vgg_format)
# 两种加载数据集的方法
dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format)
for x in ['train', 'val']}
tsets = {y: datasets.ImageFolder(os.path.join(data_dir, y), vgg_format)
for y in ['test']}
# tset_sizes = {y: len(tsets[y]) for y in ['test']}
# print('tset_sizes', tset_sizes) =====> tset_sizes {'test': 2000} 两千张测试集
# dset_sizes = {x: len(dsets[x]) for x in ['train', 'val']}
# dset_classes = dsets['train'].classes
# print(dsets['train'].classes) =====> ['Cat', 'Dog']
# print(dsets['train'].class_to_idx) =====> {'Cat': 0, 'Dog': 1}
# print('dset_sizes: ', dset_sizes) =====> dset_sizes: {'train': 20000, 'val': 2000}
loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=64, shuffle=True, num_workers=6)
loader_valid = torch.utils.data.DataLoader(dsets['val'], batch_size=5, shuffle=False, num_workers=6)
loader_test = torch.utils.data.DataLoader(tsets['test'],batch_size=5,shuffle=False,num_workers=6)
'''
valid 数据一共有2000张图,每个batch是5张,因此,下面进行遍历一共会输出到 400
同时,把第一个 batch 保存到 inputs_try, labels_try,分别查看
'''
count = 1
for data in loader_valid:
# print(count, end='
')
if count == 1:
inputs_try,labels_try = data
count +=1
# 显示图片的小程序
def imshow(inp, title=None):
# Imshow for Tensor.
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = np.clip(std * inp + mean, 0,1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# 显示 labels_try 的5张图片,即valid里第一个batch的5张图片
out = torchvision.utils.make_grid(inputs_try)
imshow(out, title=[dset_classes[x] for x in labels_try])

创建VGG Model
torchvision中集成了很多在 ImageNet (120万张训练数据) 上预训练好的通用的CNN模型,可以直接下载使用。
在本课程中,我们直接使用预训练好的 VGG 模型。同时,为了展示 VGG 模型对本数据的预测结果,还下载了 ImageNet 1000 个类的 JSON 文件。
!wget https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
model_vgg = models.vgg16(pretrained=True)
# 得到 ImageNet 1000 个试别类别
with open('./imagenet_class_index.json') as f:
class_dict = json.load(f)
dic_imagenet = [class_dict[str(i)][1] for i in range(len(class_dict))]
inputs_try , labels_try = inputs_try.to(device), labels_try.to(device)
model_vgg = model_vgg.to(device)
outputs_try = model_vgg(inputs_try)
# print(outputs_try.shape) =====》 torch.Size([5, 1000])
'''
可以看到结果为5行(batch大小),1000列(种类)的数据,每一列代表对每一种目标识别的结果。
但是也可以观察到,结果非常奇葩,有负数,有正数,
为了将VGG网络输出的结果转化为对每一类的预测概率,我们把结果输入到 Softmax 函数
'''
m_softm = nn.Softmax(dim=1)
probs = m_softm(outputs_try)
vals_try,pred_try = torch.max(probs,dim=1)
print([dic_imagenet[i] for i in pred_try.data])
imshow(torchvision.utils.make_grid(inputs_try.data.cpu()),
title=[dset_classes[x] for x in labels_try.data.cpu()])
# 能够看出,VGG模型是十分强大的,再识别出猫的基础上,能够对猫的种类也进行识别分类

VGG模型修改
在本次实验中,并不需要VGG原有的1000类的类别识别,所以可以对VGG最后的全连接层进行修改,把最后的 nn.Linear 层由1000类,替换为2类。同时保留前面层网络的参数权重,即将反向传播的过程中,不再更新前面层的权重,仅更新最后一层。
# print(model_vgg) =====> in_features=4096, out_features=1000
model_vgg_new = model_vgg;
for param in model_vgg_new.parameters():
param.requires_grad = False
model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2)
model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1)
model_vgg_new = model_vgg_new.to(device)
# print(model_vgg_new.classifier) =====> in_features=4096, out_features=2
训练并测试网络
'''
第一步:创建损失函数和优化器
损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签.
它不会为我们计算对数概率,适合最后一层是log_softmax()的网络.
'''
criterion = nn.NLLLoss()
# criterion = nn.CrossEntropyLoss()
# 这里的CrossEntropyLoss(交叉熵损失函数)通常用于多分类问题,也可以用作本次实验的二分类,不过感觉实验结果要比NLLLoss(负对数似然损失函数)差
# 学习率
lr = 0.001
# 随机梯度下降
# optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(),lr = lr)
# optimizer_vgg = torch.optim.ASGD(model_vgg_new.classifier[6].parameters(),lr = lr)
optimizer_vgg = torch.optim.Adam(model_vgg_new.classifier[6].parameters(),lr = lr)
# 这里按照老师的提示,尝试了Adam,是能明显看出准确率的提升的
'''
第二步:训练模型
'''
def train_model(model,dataloader,size,epochs=1,optimizer=None):
model.train()
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
optimizer = optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs)
print('Training: No. ', count, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
# 训练网络(train数据集)
train_model(model_vgg_new,loader_train_trans,size=dset_sizes['train'], epochs=1,
optimizer=optimizer_vgg)
def test_model(model,dataloader,size):
model.eval()
predictions = np.zeros(size)
all_classes = np.zeros(size)
all_proba = np.zeros((size,2))
i = 0
running_loss = 0.0
running_corrects = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
predictions[i:i+len(classes)] = preds.to('cpu').numpy()
all_classes[i:i+len(classes)] = classes.to('cpu').numpy()
all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy()
i += len(classes)
print('Testing: No. ', i, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
return predictions, all_proba, all_classes
# 测试网络(valid)
predictions, all_proba, all_classes test_model(model_vgg_new,loader_valid,size=dset_sizes['val'])
实验结果处理
由于研习社要求提交的结果是csv文件,并进行了排序,所以对于实验结果需要进行一定的操作。
import re
# 得到测试图片编号
string = tsets['test'].imgs[0][0]
num = re.sub("D", "", string)
result = []
# 将测试数据集(test)输入到网络中,得到识别结果
for item,lable in loader_test:
item = item.to(device)
ll = model_vgg_new(item)
_,pre = torch.max(ll.data,1)
result += pre
# 结果排序
result_end =list()
cc = 0
for item in result:
string = tsets['test'].imgs[cc][0]
num = re.sub("D", "", string)
result_end.append((num,item.tolist()))
cc += 1
result_sort = sorted(result_end,key=lambda x:int(x[0]))
# 写入文件
import csv
f = open('out_file.csv','w')
writer = csv.writer(f)
for i in result_sort:
writer.writerow(i)
f.close()
总结
通过这一周的学习,更多的是对于代码的掌握,以及一些知识的回顾。对于VGG网络的优化处理并没有想出很好的优化方法,仅通过修改优化器(SGD->Adam)提升了一些准确率,在其他方面并没有什么太大的改动,可能是相关内容接触不多的原因,所以在接下里的学习中,也会更加注重多看多学,能够学以致用。