2017-07-25 10:38:30
response = requests.get(url, params=None, **kwargs)
- url : 拟获取页面的url链接∙ params : url中的额外参数,字典或字节流格式,可选
- params参数是字典或字节序列,作为参数增加到url中
kv = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.request('GET', 'http://python123.io/ws', params=kv)
>>> print(r.url)
http://python123.io/ws?key1=value1&key2=value2
- **kwargs: 12个控制访问的参数

headers:字典,HTTP定制头
hd = {'user‐agent': 'Chrome/10'}
r = requests.request('POST', 'http://python123.io/ws', headers=hd)
timeout : 设定超时时间,秒为单位
r = requests.request('GET', 'http://www.baidu.com', timeout=10)
proxies : 字典类型,设定访问代理服务器,可以增加登录认证
>>> pxs = { 'http': 'http://user:pass@10.10.10.1:1234'
'https': 'https://10.10.10.1:4321' }
>>> r = requests.request('GET', 'http://www.baidu.com', proxies=pxs)
使用举例:
import requests # r:response 右侧get: requests r = requests.get('http://jwc.seu.edu.cn/')
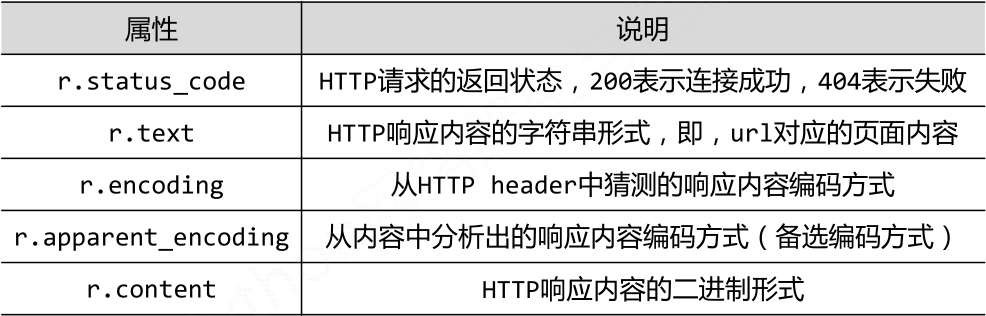
一、返回值Response对象的属性


二、爬取网页的通用代码框架
import requests def gethtml(url): # 打开网页有风险,需要使用try-except语句进行风险控制 try: r = requests.get(url) r.raise_for_status() # 如果打开失败,则会抛出一个HttpError异常 # encoding是从header中分析出来的编码方式,apparent_encoding是 从内容分析出的编码方式 r.encoding=r.apparent_encoding return r.text except: print("打开失败")
三、requests库的方法和HTTP协议
- HTTP协议:超文本传输协议
HTTP是一个基于“请求与响应”模式的、无状态的应用层协议。
HTTP协议采用URL作为定位网络资源的标识,URL格式如下:http://host[:port][path]
HTTP协议对资源的操作方法:

其中get,head方法是从服务器取回数据,post,put,patch,delete方法是向服务器写入或者修改数据。
patch 和 put 的区别:patch 是局部更新,而put 是全部更新。patch节省网络带宽,是HTTP协议改良后的新增指令。
HTTP的指令和requests 的方法一一对应。
- Requests 的七个主要方法
