2019-10-09 19:54:42
问题描述:谈谈对Transformer的理解。
问题求解:
- Transformer 整体架构
Transformer 是典型的Seq2Seq架构的模型,其核心的骨架依然是encoder-decoder两个模块,和传统的S2S问题不同的地方在于Transformer提出了Self-Attension机制, 并且通过实验发现使用Self-Attension可以很好的替代RNN/LSTM,并且取得STOA的效果。
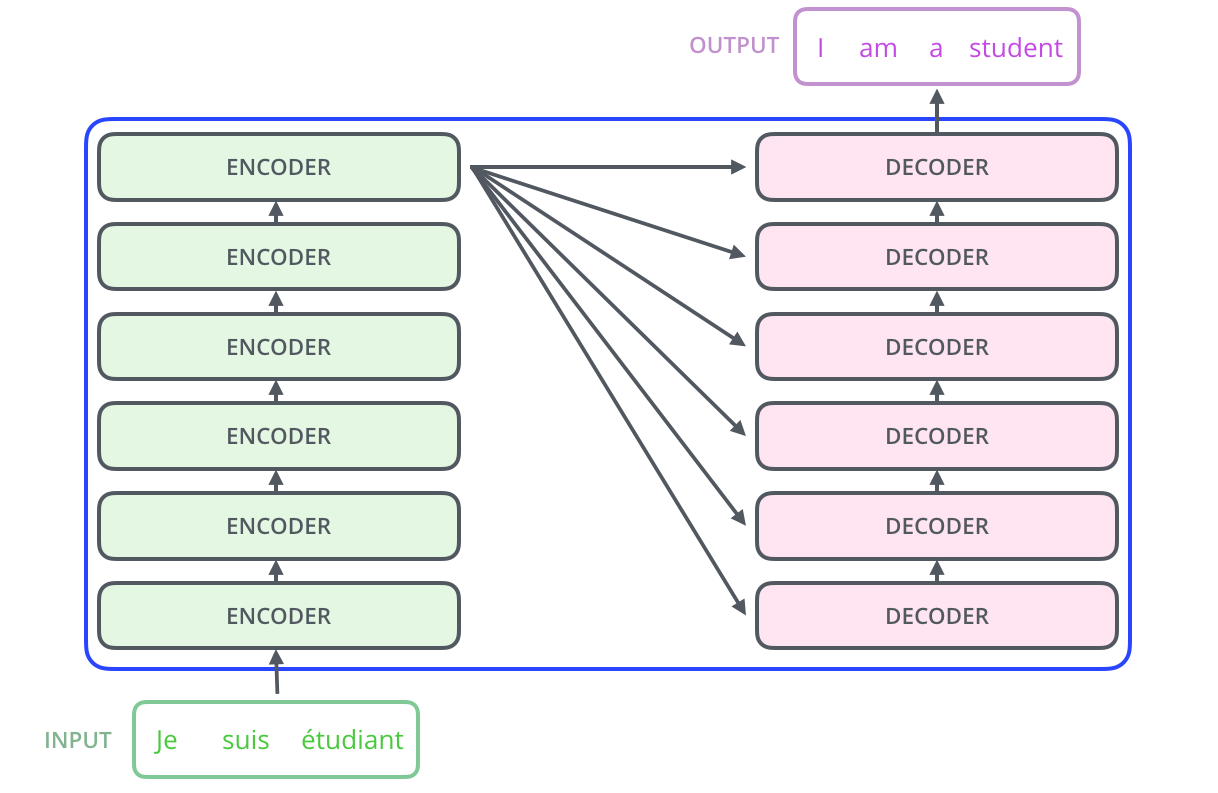
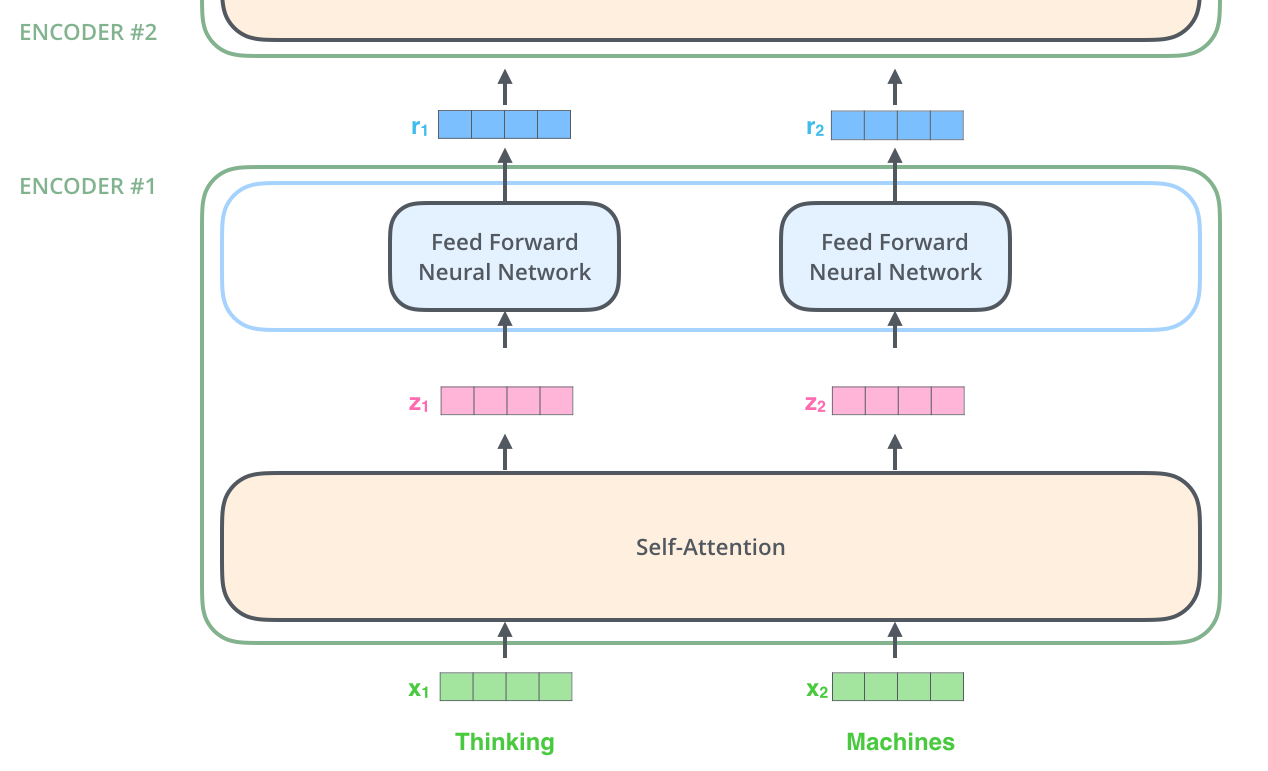
Encoder:encoder模块由6个完全一致的layer组成,每个layer又分成两个部分,一层是Self-Attension,后接一层前向传播网络。词的向量化仅仅发生在最底层的编码器的输入时,这样每个编码器的都会接收到一个list(每个元素都是512维的词向量),只不过其他编码器的输入是前个编码器的输出。list的尺寸是可以设置的超参,通常是训练集的最长句子的长度。
在对输入序列做词的向量化之后,它们流经编码器的如下两个子层。
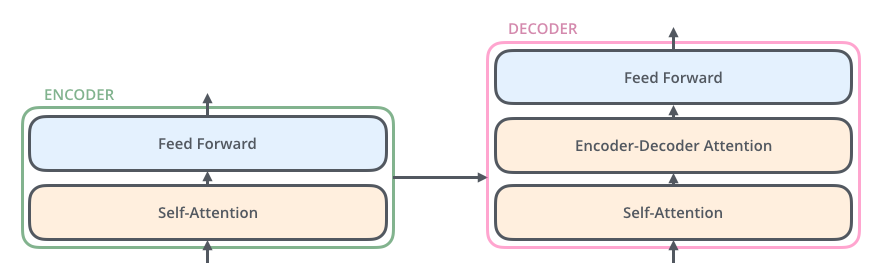
Decoder:decoder 模块由6个完全一致layer构成,每个layer相比encoder多了一个结构,就是encoder-decoder attension,这一层的作用是计算decoder中的embedding和encoder中的各个维度的embedding的关联度,另外在self-attension中也引入了一个机制,即mask机制,对于还未解码出来的位置在softmax的时候赋值-INF,我们知道如果是-INF,那么其attension或者说是权重的值几乎为0,也就不会对前面已经出现的数值产生影响。
【输出】对应i位置的输出词的概率分布。
【输入】encoder的输出 & 对应i-1位置decoder的输出(所以最开始的attention是self-attention(QKV全是decoder隐层);中间的attention不是self-attention,K,V来自encoder,Q来自上一位置decoder的输出)。
decoder层中的输入是上一个三个sublayer的作用。
【sublayer 1】self-attension:计算与已经解码出来的信息的关联度
【sublayer 2】encoder-decoder attension:计算和输入的序列的关联度
【sublayer 3】前向传播,同时可以将维度进行调整
- Self-Attension 机制
Attension本质上就是输入两个vector,输出它们的相似度/关联度。
在传统的attension机制中我们通常采用的是一个神经网络来计算相似度,在self-attension中我们计算相似度的方式可以说更为直观和简单,直接进行内积操作就可以得到两个输入的vector之间的相似度。
1. self-attension 建模
在self-attension中每一个输入的embedding会生成三个向量,分别是query,key,value。
q query:to match others qi = Wq ai
k key: to be matched ki = Wk ai
v value: information extract vi = Wv ai
self-attension采用了QKV模型,模型输入为q,Memory 中以(k, v)形式存储需要的上下文。
在这种建模方式下,分为三步:
- 在memory中找相似 (score function):
- 归一化 (alignment function):
- 读取内容 (context vector function):
2. Self-Attension 和 CNN 的神似性
self-attention和convolution 有点儿神似,它摒弃了CNN的局部假设,想要寻找长距离的关联依赖。看下图就可以理解 self-attention 的这几个特点:
- constant path length & variable-sized perceptive field :任意两个位置(特指远距离)的关联不再需要通过Hierarchical perceptive field的方式,它的perceptive field是整个句子,所以任意两个位置建立关联是常数时间内的。
- parallelize : 没有了递归的限制,就像CNN一样可以在每一层内实现并行。

3. multi-head attension
self-attention借鉴CNN中multi-kernel的思想,进一步进化成为multi-head attention。每一个不同的head使用不同的线性变换,学习不同的relationship。
4. Scaled Dot-Product Attention
self-attension中的点积操作并不是直接点乘,而是加入了缩放操作。
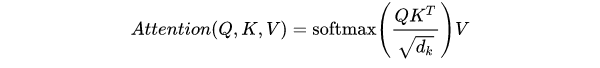
传统的Dot-Product Attention并没有scale factor,self-attension中之所以进行缩放是为了减少点积结果的方差(类似normalize)。
大方差会导致weight有的大有的小,softmax会导致大的更大,小的更小。
5. Transformer 中的三种 Attension
Transformer框架中self-attention本身是一个很大的创新,另一个有意思的是three ways of attention的设计。
- Encoder self-attention:Encoder 阶段捕获当前 word 和其他输入词的关联;
- Masked-Decoder self-attention :Decoder 阶段捕获当前 word 与已经看到的解码词之间的关联,从矩阵上直观来看就是一个带有 mask 的三角矩阵;
- Encoder-Decoder Attention:就是将 Decoder 和 Encoder 输入建立联系,和之前那些普通 Attention 一样;
6. self-attension 为何 work
从上面的建模,我们可以大致感受到 Attention 的思路简单,四个字“带权求和”就可以高度概括,大道至简。做个不太恰当的类比,人类学习一门新语言基本经历四个阶段:死记硬背(通过阅读背诵学习语法练习语感)->提纲挈领(简单对话靠听懂句子中的关键词汇准确理解核心意思)->融会贯通(复杂对话懂得上下文指代、语言背后的联系,具备了举一反三的学习能力)->登峰造极(沉浸地大量练习)。
这也如同attention的发展脉络,RNN时代是死记硬背的时期,attention的模型学会了提纲挈领,进化到transformer,融汇贯通,具备优秀的表达学习能力,再到GPT、BERT,通过多任务大规模学习积累实战经验,战斗力爆棚。
要回答为什么attention这么优秀?是因为它让模型开窍了,懂得了提纲挈领,学会了融会贯通。那又是如何开窍的?是因为它懂得了"context is everything"。
Attention背后本质的思想就是:在不同的 context 下,focusing 不同的信息。这本来就是一个普适的准则。所以 Attention 可以用到所有类似需求的地方,不仅仅是 NLP,图像,就看你对 context 如何定义。
- Positional Encoding 的理解
RNN是天然有序的,然而Transformer中引入了Self-Attension机制,达到了“天涯若比邻”的效果,原本文本之间的先后顺序信息消失了,Transformer中引入了Positional Encoding来向网络中加入位置信息。
关于如何在self-attension中加入位置信息其实有两种方案,一个是Facebook的Positional Embedding方案,就是使用神经网络去学习位置向量,这种方案的位置编码是有限维度的。
另一种就是Google采用的Positional Encoding方案,不用神经网络去学习,而是直接通过公式计算的到结果。
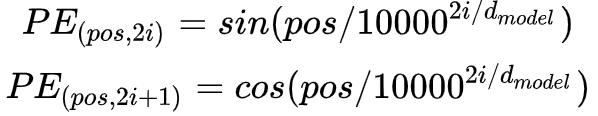
其中,pos即position,意为token在句中的位置,设句子长度为L ,则 pos = 1, 2, 3, ... , L;i 为向量的某一维度,例如dmodel = 512 时, i = 0, 1, 2, 3, ... , 255。
借助三角公式,我们可以得到,任意两个相距k的两个位置的位置向量,可以通过线性变化得到,这样的线性组合意味着位置向量中蕴含了相对位置信息。
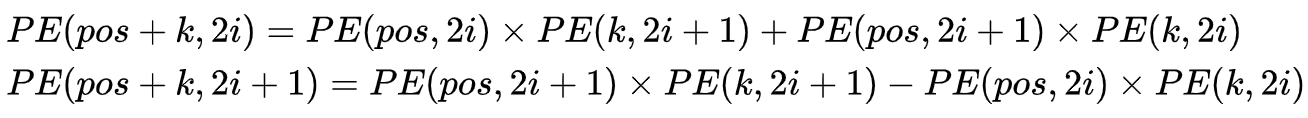
- Transforemr、LSTM、CNN 间的区别
从支持并行性的角度来看,LSTM网络依然是传统的RNN网络的扩展,其中间节点的状态依赖前一个网络的输出,因此无法支持并行性;
Transformer和CNN均支持并行性,但是在长距离特征捕获能力上,CNN明显偏弱,CNN需要通过分层叠加来达到长距离的特征捕获,而Transformer天然支持长距离的特征捕获。
由于加入了Multi-head机制,Transformer的特征提取能力非常强悍,完全不若于LSTM和CNN。