2018-12-06 16:25:08
首先我们先来看一下求解梯度的公式,以下面三层的网络为例:

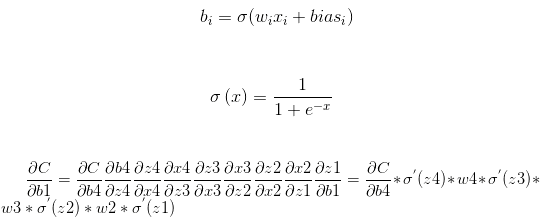
如果w初始化为大于1的数字,在深层神经网络计算梯度的时候就会出现梯度爆炸的现象;
如果w初始化为小于1的数字,在深层神经网络计算梯度的时候就会出现梯度消失的现象;
那么该如何初始化权重值呢?

z = w1 * x1 + w2 * x2 + ... + wn * xn
我们希望的是当n很大的时候,z的值不要过大。
其中一个方法就是通过修改方差的方法来完成这个操作,假设我们最初初始化的数值是N(0, 1)的标准正态分布,那么当n很大的时候我们希望w能更多的向0靠近,此时显然的我们需要方差进行减小,这里我们可以将方差设置为1 / n来完成相应的操作。具体的初始化公式如下:
w = np.random.randn(f_in, f_out) * np.sqrt(1 / n)
实验证明,当使用relu做为激活函数的时候,方差为2 / n效果更好,因此修正的Xavier初始化公式如下:
w = np.random.randn(f_in, f_out) * np.sqrt(2 / n)