结对第二次—文献摘要热词统计及进阶需求
| 课程链接 | 软件工程1916|W(福州大学) |
| 作业要求 | 结对第二次—文献摘要热词统计及进阶需求 |
| 结对学号 | 221600207|221600205 |
| 作业目标 | 本次作业分为两部分: 一、基本需求:实现一个能够对文本文件中的单词的词频进行统计的控制台程序。 二、进阶需求:在基本需求实现的基础上,编码实现顶会热词统计器 |
| 作业正文 | 作业正文 |
| 基础需求 | WordCount |
| 进阶需求 | WordCountPro |
提交截图如下

一、写在前面
本此作业中进阶需求里的-m功能尚未完成,基本思路为将读取的String分割为单词,创建数组并依次记录单词出现的下标,非法单词记录下标为-1。即String="key,hello word"对应数组为a[0]=0;a[1]=-1;a[2]=4;a[3]=10;取m=2时则取出subString(a[2],a[3]+a[3].length);
二、团队分工
221600207黄权焕
- 完成基础需求src目录下的全部代码
- 完成进阶需求src目录下的全部代码
- 编写博客
- 软件测试
221600205陈红宝
- 完成进阶需求cvpr目录下全部代码
- 编写博客
- 软件测试
三、PSP 表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 900 | |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 120 | 600 |
| • Design Spec | • 生成设计文档 | 60 | 60 |
| • Design Review | • 设计复审 | 30 | 60 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| • Design | • 具体设计 | 120 | 200 |
| • Coding | • 具体编码 | 600 | 900 |
| • Code Review | • 代码复审 | ||
| • Test | • 测试(自我测试,修改代码,提交修改) | 30 | 120 |
| Reporting | 报告 | 60 | 150 |
| • Test Repor | • 测试报告 | 30 | 30 |
| • Size Measurement | • 计算工作量 | 30 | 30 |
| •Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 30 |
|合计 | 1110 |2210 |
四、解题思路
1.基础需求
获取行数
将文件打开后,用readLine()函数逐行读取文本内容并保存在fContent上,此时叠加行数。
获取字符数
将字符串fContent读取成功后,字符数+=fContent.length;
获取单词数
将fContent使用split("W+")分割成只有可写字符的单词组存入String [] ch中,单词数+=ch.length;
数据结构
使用HashMap保存单词和使用频率,不使用TreeMap的原因是,TreeMap没有自带按值排序后,相同值按字典序排序的特性。而HashMap可以使存储、查找的时间效率都在O(1)内完成,而不是TreeMap的log(N);
词频排序
值得注意的是,Map本身排序需要转化成List,排序成功后应将结果应重新转化为LinkedHashMap。
LinkedHashMap可以按插入顺序保存,方便后续使用。时间复杂度N*log(N);
2.进阶需求
自定义输入输出
在类中额外保存输入输出名即可。
自定义词频统计输出
在类中额外保存一个最大单词数用来控制LinkedHashMap长度即可。
权重分析
在HashMap插值时,额外判断是否来自Title,是的话记录数+10,否则+1即可。
词组词频统计功能
词组词频统计分析由于时间关系尚未实现,思路在写在前面已介绍过。将读取的String分割为单词,创建数组并依次记录单词出现的下标,非法单词记录下标为-1。即String="key,hello word"对应数组为a[0]=0;a[1]=-1;a[2]=4;a[3]=10;取m=2时则取出subString(a[2],a[3]+a[3].length);取m=1时则取出subString(a[2],a[2]+a[2].length)等。
多参数的混合使用
读取一行,依旧用split("-")函数分割成不同指令,分别调用函数即可。
3.爬虫(由我队友00205完成)
诸位还是到我队友文章查看,由于本人无法总结,且他文章字数太多,我不再赘述。221600205
五、代码组织与测试
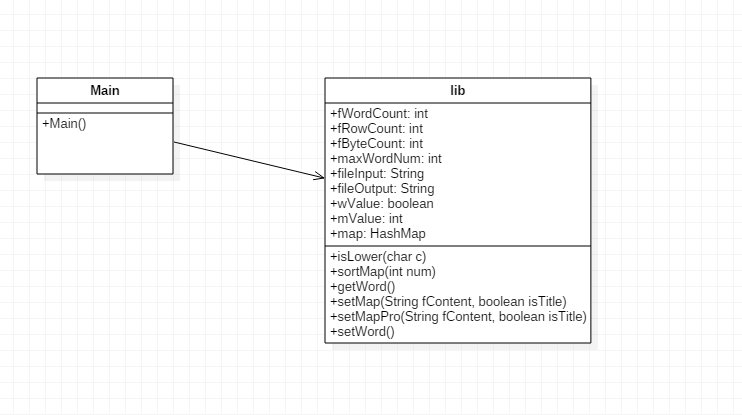
lin.java完成函数的封装。其中setWord接受文件名,调用setMap,调用isLow;getWord输出文件,调用sortMap。
Main.java进行调用和设置lib类的参数。
类图如下
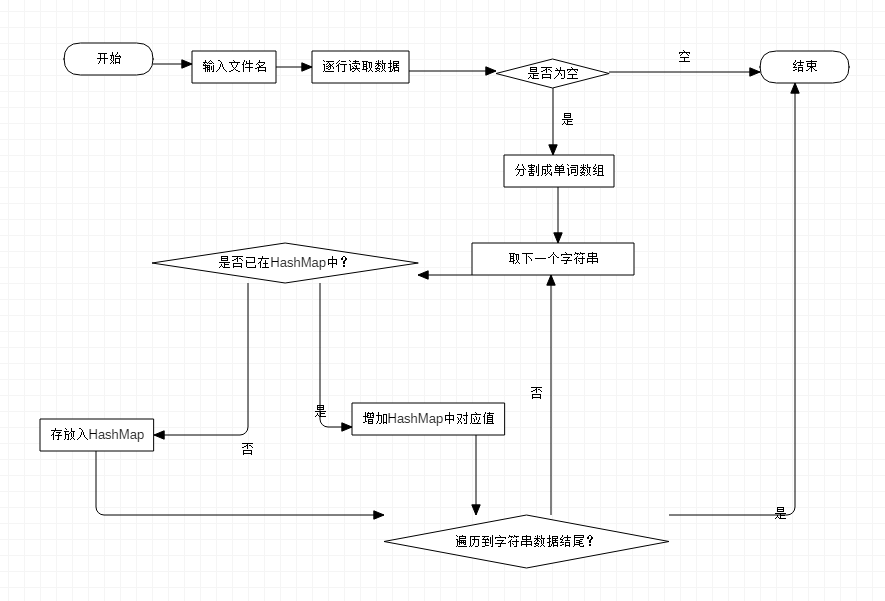
存放时的流程图如下
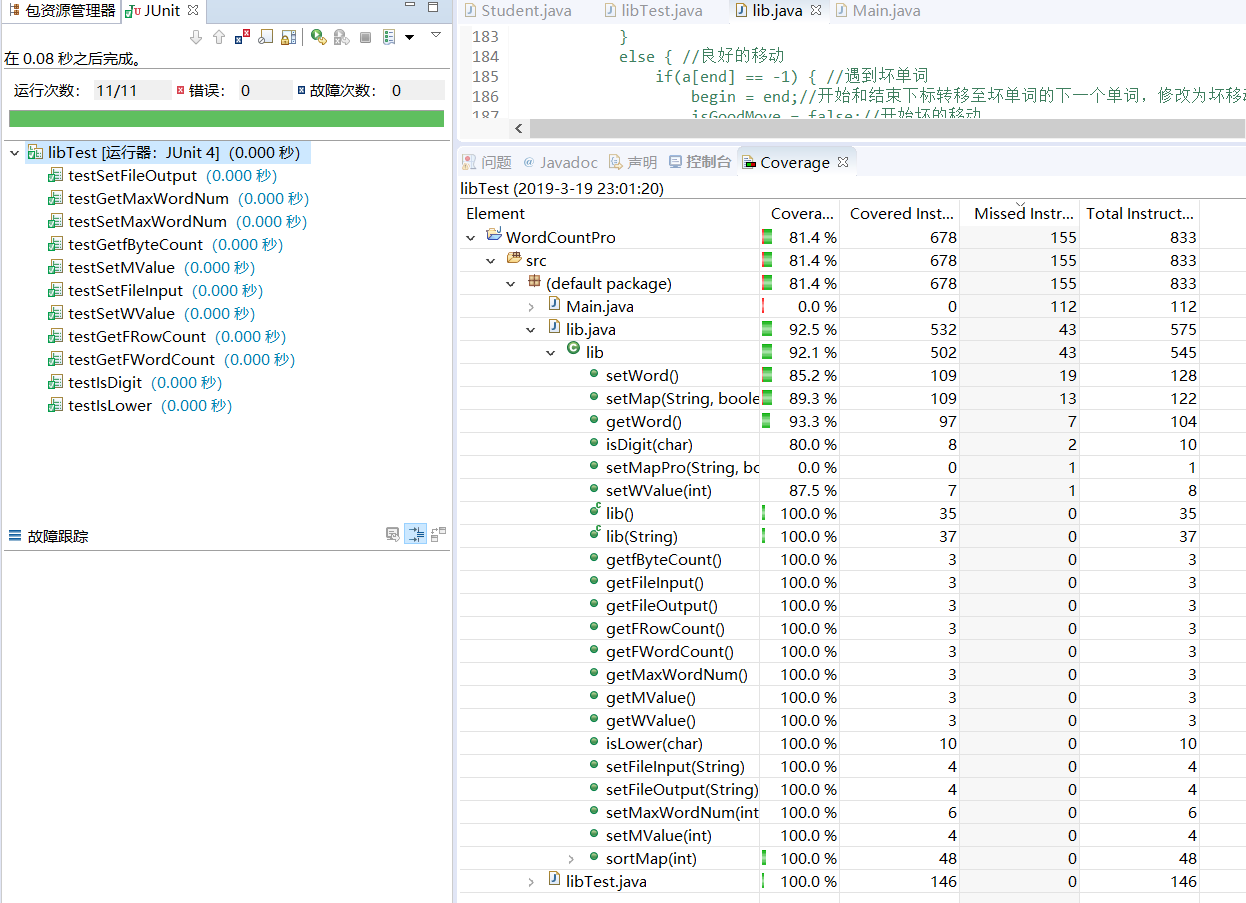
单元测试图
单元测试代码
import static org.junit.Assert.*;
import org.junit.Test;
public class libTest {
@Test
public void testSetFileInput() {
lib b = new lib();
b.setFileInput("input.txt");
assertEquals("input.txt",b.getFileInput());
}
@Test
public void testSetFileOutput() {
lib b = new lib();
b.setFileOutput("output.txt");
assertEquals("output.txt",b.getFileOutput());
}
@Test
public void testSetWValue() {
lib b = new lib();
b.setWValue(3);
assertEquals(true,b.getWValue());
}
@Test
public void testSetMValue() {
lib b = new lib();
b.setMValue(5);
assertEquals(5,b.getMValue());
}
@Test
public void testSetMaxWordNum() {
lib b = new lib();
b.setMaxWordNum(5);
assertEquals(5,b.getMaxWordNum());
}
@Test
public void testGetFWordCount() {
lib b = new lib("input.txt");
b.setWord();
assertEquals(9,b.getFWordCount());
}
@Test
public void testGetFRowCount() {
lib b = new lib("input.txt");
b.setWord();
assertEquals(2,b.getFRowCount());
}
@Test
public void testGetfByteCount() {
lib b = new lib("input.txt");
b.setWord();
b.getWord();
assertEquals(74,b.getfByteCount());
}
@Test
public void testGetMaxWordNum() {
lib b = new lib("input.txt");
b.setMaxWordNum(12);
assertEquals(12,b.getMaxWordNum());
}
@Test
public void testIsLower() {
lib b = new lib();
assertEquals(false,b.isLower('A'));
}
@Test
public void testIsDigit() {
lib b = new lib();
assertEquals(true,b.isDigit('0'));
}
}
六、关键代码实现
1.类的数据字段
public class lib {
private int fWordCount = 0;//字词数
private int fRowCount = 0;//行数
private int fByteCount = 0;//字节数
private int maxWordNum = 10;//词频输出数
private String fileInput= "cvpr/result.txt";
private String fileOutput= "src/output.txt";
private boolean wValue = false;//-w 值
private int mValue = 1;//-m 值
private HashMap<String,Integer> map = new HashMap<String,Integer>();//存放字词处
//……
}
2.读入文档并统计
public void setWord()
{
try {
String fContent = "";
FileInputStream fis = new FileInputStream(fileInput);
InputStreamReader isr = new InputStreamReader(fis);
BufferedReader br = new BufferedReader(isr);
fWordCount = fByteCount = fRowCount = 0;
while ((fContent = br.readLine()) != null) {
if(fContent.length() > 3)//排除空行和编号
{
fRowCount ++;
if(fContent.charAt(0) == 'T')
{
fContent = fContent.substring(7, fContent.length()-1 );//remove(Title:)
//换行+1
fByteCount += fContent.length()+1;
if(mValue >= 1 )
setMap(fContent,true);
else
setMapPro(fContent,true);
}
else if(fContent.charAt(0) == 'A')
{
fContent = fContent.substring(9, fContent.length()-1 );//remove(Abstract: )
//换行+1
fByteCount += fContent.length()+1;
if(mValue >= 1 )
setMap(fContent,false);
else
setMapPro(fContent,false);
}
}
}
fis.close();
} catch (FileNotFoundException e) {
System.out.print("文件不存在");
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
3、根据字符串分割成单词并保存
public void setMap(String fContent,boolean isTitle)
{
String [] ch = fContent.split("\W+");
for(int i = 0; i< ch.length ;i++)
{
if(ch[i].length()>=4)
{
ch[i] = ch[i].toLowerCase();
if (isLower(ch[i].charAt(0)) && isLower(ch[i].charAt(1)) && isLower(ch[i].charAt(2)) && isLower(ch[i].charAt(3)) )
{
//System.out.print(ch[i]);
//新增纪录或者�记录数+1
fWordCount ++;
if( map.containsKey(ch[i]) )
map.put(ch[i],(wValue & isTitle) ? map.get(ch[i])+10 : map.get(ch[i])+1);
else
map.put(ch[i], (wValue & isTitle) ? 10 : 1);
}
}
}
}
4.Map排序
public LinkedHashMap<String,Integer> sortMap(int num)
{
List<Map.Entry<String,Integer>> list = new ArrayList<Map.Entry<String,Integer>>(map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
return o2.getValue() != o1.getValue() ? (o2.getValue() - o1.getValue()) : (o1.getKey()).toString().compareTo(o2.getKey());
//return (o1.getKey()).toString().compareTo(o2.getKey());
}
});
LinkedHashMap<String,Integer> tmp = new LinkedHashMap<String,Integer>();
for (int i = 0; i < list.size() && i< num; i++) {
String id = list.get(i).toString();
Integer value = list.get(i).getValue();
tmp.put(id, value);
//System.out.println(id + (value));
}
return tmp;
}
5.文档输出(可自定义)
public void getWord()
{
LinkedHashMap<String,Integer> list = sortMap(maxWordNum);
try {
FileOutputStream fos = new FileOutputStream(fileOutput);
OutputStreamWriter osw = new OutputStreamWriter(fos);
BufferedWriter buff = new BufferedWriter(osw);
String content = "characters: " + fByteCount + "
";
content += "words: "+ getFWordCount() + "
";
content += "lines: "+ fRowCount + "
";
Iterator<String> iterator = list.keySet().iterator();
while (iterator.hasNext()) {
String key = iterator.next();
content += "<" + key.replace("=", ">: ") + "
";
//System.out.println(key.replace("=", ">: "));
}
//System.out.print(content);
buff.write(content);
buff.flush();
fos.close();
} catch (FileNotFoundException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
七、算法改进
在sortMap排序中,我使用的是java自带的sort函数,故时间效率为N*log(N).但是我们也可以改为维护一个最大堆MaxHeap,设定堆的容量为maxWordNum,以下简称M。则时间效率可以改进为N*log(M),在通常情况下,M很小,log(M)约等于1,可惜java没有现成的最大堆。
八、总结与队友评价
本次任务时间相对紧张,像性能测试和单元测试并没有做得很好。这次结对暴露出一些问题,我是想好的时间计划很容易被队友的编程速度打败。比如这次,我独立完成了基础需求和进阶需求的大部分代码,即便如此,我依旧是在作业发布的第五天才收到我队友的爬虫相关代码。
另外不可否认的是,项目进度拖延也有我的一部分责任,尽管我是近乎每天都有跟进与催促,但效果甚微,我却在完善和测试自己的代码,没有过多给与支持(可能我是不想一个人完成整个项目吧,摊手.jpg)
对于这次项目的要求,GitHub、单元测试与jProfiler的使用也花费了我不少时间,且由于最初测试时没有使用单元测试,函数也不够细致,导致后续的单元测试只能非常简单,性能分析也草草结束。(这三项几乎花了我一半的代码时间,不能小觑)。
关于队友,我还是认可他的学习态度的,他也因熬夜写代码而熬到了四点余。尽管我接触的爬虫是依据文档树查找叶节点实现的,而他是通过匹配正则而实现,但我并不清楚他这么做到底有多难,也就无从评价,还是请诸君移步至他的博客一观。
在文章末尾,我也想借此提出疑问:一个软件项目中,你无法准确评估队友的编程能力高低,那么是事前分工和计划被打破的情况下,如何重新组织分工与计划呢?