Redis的过期策略和内存淘汰机制
过期策略:
我们set key的时候,都可以给一个expire time,就是过期时间,指定这个key比如说只能存活1个小时,我们自己可以指定缓存到期就失效。
如果假设你设置一个一批key只能存活1个小时,那么接下来1小时后,redis是怎么对这批key进行删除的?
答案是:定期删除+惰性删除
定期删除:指的是redis默认是每隔100ms就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。
注意,这里可不是每隔100ms就遍历所有的设置过期时间的key,那样就是一场性能上的灾难。
实际上redis是每隔100ms随机抽取一些key来检查和删除的。
但是,定期删除可能会导致很多过期key到了时间并没有被删除掉,所以就得靠惰性删除了。
惰性删除:这就是说,在你获取某个key的时候,redis会检查一下 ,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除,不会给你返回任何东西。并不是key到时间就被删除掉,而是你查询这个key的时候,redis再懒惰的检查一下
通过上述两种手段结合起来,保证过期的key一定会被干掉。
但是实际上这还是有问题的,如果定期删除漏掉了很多过期key,然后你也没及时去查,也就没走惰性删除,此时会怎么样?
如果大量过期key堆积在内存里,导致redis内存块耗尽了,怎么办?
答案是:走内存淘汰机制。
内存淘汰机制:
如果redis的内存占用过多的时候,此时会进行内存淘汰,有如下一些策略:
-
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错,这个一般没人用吧
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key,这个一般没人用吧
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key(这个一般不太合适)
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除
热点数据
热点的常见原因:
-
- 用户消费的数据远大于生产的数据(热卖商品、热点新闻、热点评论、明星直播)
在日常工作生活中一些突发的的事件,例如:热门商品的降价促销,会形成一个较大的需求量,这种情况下就会造成热点问题。同理,被大量刊发、浏览的热点新闻、热点评论、明星直播等,这些典型的读多写少的场景也会产生热点问题。
-
- 请求分片集中,超过单 Server 的性能极限
在服务端读数据进行访问时,往往会对数据进行分片切分。此过程中会在某一主机 Server 上对相应的 Key 进行访问,当访问超过 Server 极限时,就会导致热点 Key 问题的产生。
热点问题的影响:
-
- 流量集中,达到物理网络适配器的上限。
- 请求排队太多,导致缓存的分片服务崩溃。
- 数据库过载,导致服务雪崩。
怎么发现热key:
1.凭借业务经验,进行预估哪些是热key
其实这个方法还是挺有可行性的。比如某商品在做秒杀,那这个商品的key就可以判断出是热key。缺点很明显,并非所有业务都能预估出哪些key是热key。
2.在客户端进行收集
这个方式就是在操作redis之前,加入一行代码进行数据统计。那么这个数据统计的方式有很多种,也可以是给外部的通讯系统发送一个通知信息。缺点就是对客户端代码造成入侵。
3.在Proxy层做收集
有些集群架构是下面这样的,Proxy可以是Twemproxy,是统一的入口。可以在Proxy层做收集上报,但是缺点很明显,并非所有的redis集群架构都有proxy。
4.用redis自带命令
(1)monitor命令,该命令可以实时抓取出redis服务器接收到的命令,然后写代码统计出热key是啥。当然,也有现成的分析工具可以给你使用,比如redis-faina。但是该命令在高并发的条件下,有内存增暴增的隐患,还会降低redis的性能。
(2)hotkeys参数,redis 4.0.3提供了redis-cli的热点key发现功能,执行redis-cli时加上–hotkeys选项即可。但是该参数在执行的时候,如果key比较多,执行起来比较慢。
5.自己抓包评估
Redis客户端使用TCP协议与服务端进行交互,通信协议采用的是RESP。自己写程序监听端口,按照RESP协议规则解析数据,进行分析。缺点就是开发成本高,维护困难,有丢包可能性。
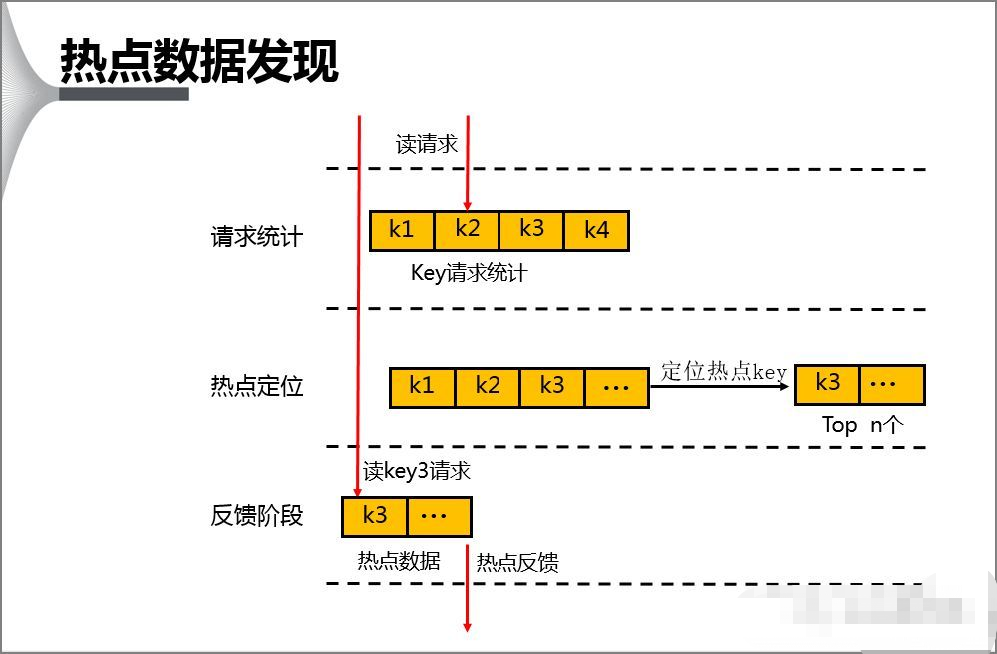
以上五种方案,各有优缺点。根据自己业务场景进行抉择即可。那么发现热key后,如何解决呢?
常见解决方案:
1.读写分离方案解决热读
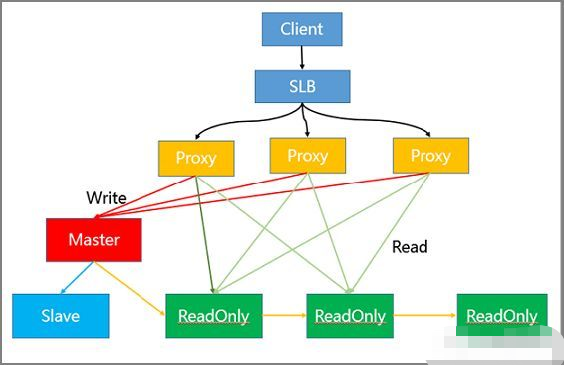
代理架构:
实际过程中 Client 将请求传到 SLB,SLB 又将其分发至多个 Proxy 内,通过 Proxy 对请求的识别,将其进行分类发送。
例如,将同为 Write 的请求发送到 Master 模块内,而将 Read 的请求发送至 ReadOnly 模块。
而模块中的只读节点可以进一步扩充,从而有效解决热点读的问题。
读写分离同时具有可以灵活扩容读热点能力、可以存储大量热点Key、对客户端友好等优点。
架构中各节点的作用如下:
-
- SLB 层做负载均衡
- Proxy 层做读写分离自动路由
- Master 负责写请求
- ReadOnly 节点负责读请求
- Slave 节点和 Master 节点做高可用
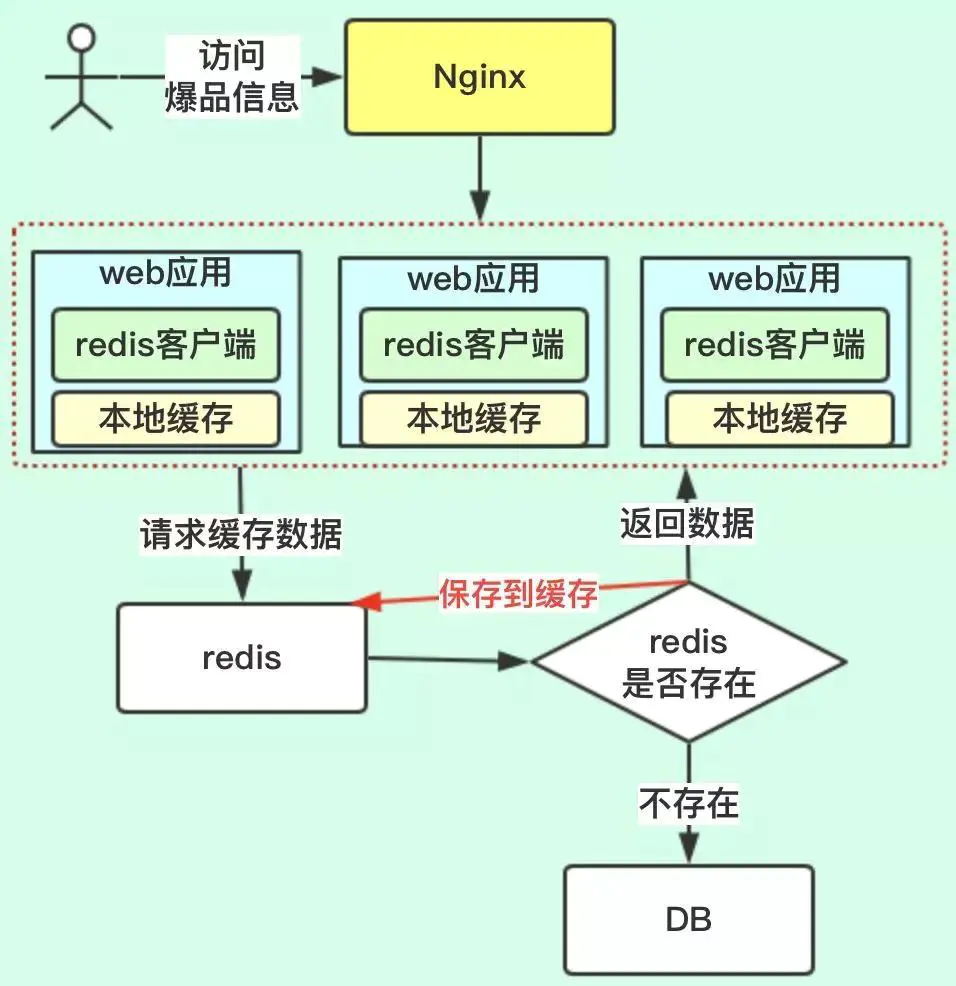
2.本地缓存:这个方案就是多级缓存的方案,把缓存前置:
代理架构:
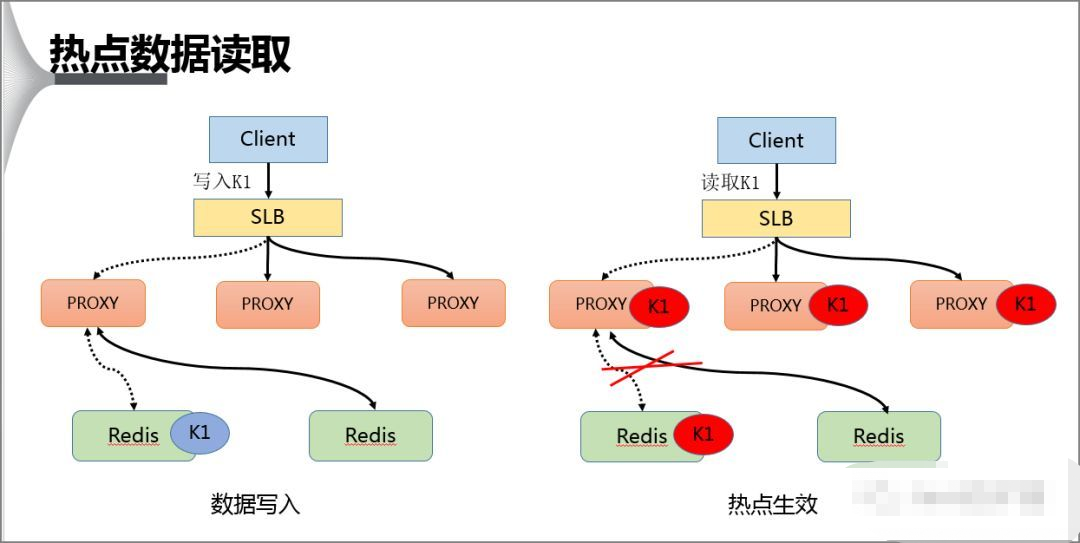
在热点 Key 的处理上主要分为写入跟读取两种形式,在数据写入过程当 SLB 收到数据 K1 并将其通过某一个 Proxy 写入一个 Redis,完成数据的写入。
具体来说就是在 Proxy 上增加本地缓存,本地缓存采用 LRU 算法来缓存热点数据,后端 db 节点增加热点数据计算模块来返回热点数据。
假若经过后端热点模块计算发现 K1 成为热点 key 后, Proxy 会将该热点进行缓存,当下次客户端再进行访问 K1 时,可以不经 Redis。
最后由于 proxy 是可以水平扩充的,因此可以任意增强热点数据的访问能力。