哈希表
支持操作:O(1)insert / O(1)Find / O(1)Delete
Hash Table / Hash Map / Hash Set区别是什么
哈希函数的功能:对于任意的Key,得到一个固定且无规律的介于0~capacity-1的整数。
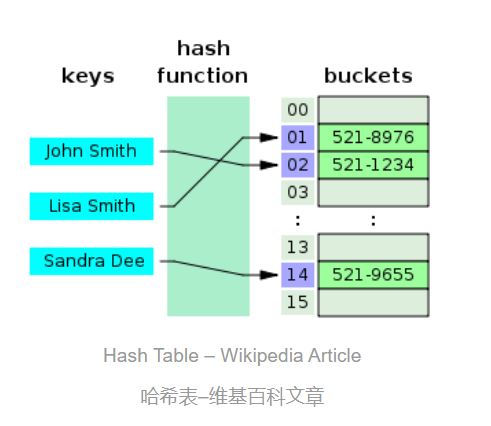
很显然可知,哈希表是一种关联数组,是一种将键映射到值的数据结构,其中映射关系使用哈希函数来计算键的索引。基于哈希表索引,我们可以将值存储在适当的位置。如果两个不同的键获得相同的索引,则需要使用其他数据结构(存储桶)来解决这些冲突。
(任何数据结构的最底层要么是离散型的数据结构(链表、二叉树等),要么是连续型的数据结构(数组))
由于有哈希函数的计算,所以哈希表的操作不是O(1)的时间复杂度
当哈希表存储空间不够大的时候呢
答案:也和arrylist一样,当数组空间存储满时,就新增一倍的内存空间
那么如何来判断哈希表中的内存空间是满的呢
我们知道,在arraylist中,当size = capacity时我们认为这个arraylist存储已满,那么在哈希表中可以这样吗?很显然,这样是不可以的,有哈希表饱和度的定义
饱和度 = 实际存储元素个数 / 总共开辟的空间大小 = size / capacity
一般来说,当饱和度超过1/10(经验值)的时候,说明需要进行rehash。就是10%空间被占的时候就要重新分配内存空间了,当超过10%之后,查询、删除和插入等操作的效率会由于冲突等原因而变得十分低下。
那么如何进行rehash
我们熟悉vector的扩容方法,是申请新的内存空间后将在旧的内存空间中的元素值直接拷贝到新的内存空间中,然后销毁旧内存空间。这样的方法在哈希表扩大内存空间的操作中肯定是不合适的。因为key是通过哈希函数映射到内存空间中的,也就是说key通过哈希函数与内存空间中的地址一一对应。而哈希函数是与内存空间的capacity有关的函数,一旦内存空间的capacity发生变化,那么哈希函数就会发生变化。那么对于同一个key,哈希函数变化前映射到内存空间中的地址与哈希函数变化后映射到内存空间中的地址是不相同的,所以在哈希表扩容的时候是不能够像vector一样只进行简单的拷贝即可,而是要将原来哈希表中的每一个key都经过变换后的哈希函数映射到新的内存空间中,与新的内存空间中的地址一一对应。
很显然,这个rehash过程是一个效率十分低下的过程,我们要尽可能避免这样的操作发生,所以我们在申请哈希表的内存空间的时候尽可能预估哈希表要占用的内存空间并申请相应大小或者保留一定余量的内存空间而达到避免rehash情况的出现。
LRC Cache
首先Cache是一个具有内存限制或者存储元素个数限制的哈希表。
LRC:Least Recently Used.当Cache中元素个数达到存储上限而继续向这个结构中存储存储数据元素时,最近没使用过的数据元素就会被抛弃而存储新插入的元素。
LFU:Least Frequently Used.当Cache中元素个数达到存储上限而继续向这个结构中存储存储数据元素时,使用频率较低的数据元素就会被抛而存储新插入的元素。
LRC是按照时间来做判别的,而LFU是按照使用的次数来做判别的。其中LRU是最常见的算法
LRU的核心思想是“如果数据最近被访问过,那么在未来被访问的概率也高”
前面知道,Cache是一个具有内存限制的表,它的内存大小是固定的。而LRU是Cache存满而继续向Cache中存储元素时,Cache就会就会抛弃最近没使用过的元素而存储新的数据元素。
假设我们有一个数据流流入LRU Cache时,Cache应该形成具有先后顺序的组织结构。
如下图:假设Cache的内存大小为3,并且下端存储着最新访问的数据元素,访问最久的数据元素。
在本例中数据流以ABCDBE的顺序流入Cache,具体过程如下图

很显然:Cache是一个连续的顺序表结构,那么我们该使用数组还是链表来构建这样的数据结构呢,肯定就是使用链表来构建这个Cache。
这是因为我们要完成的操作中有将链表尾部代表着最近没有被访问的数据删除掉,这个操作是通过数组和链表都可以完成。但是我们也有将Cache中存储在中间而再次进行访问的元素拿出来放在头部操作,这个操作对于数组来说就比较的费力,这个操作对于链表来完成更加合适。所以在构造LRU Cache时使用链表更为合适。
而当有一个要存储的数据元素时,我们首先要做的事是确定这个数据元素是否在Cache中,如果这个元素在Cache中,则将这个数据元素提到链表头部,如果不在,删除链表尾部的元素并将新插入的元素存储在链表的头部。那么查找这个数据元素是否在Cache中的最简单的数据结构就是哈希表。哈希表最常使用的功能就是确定一个数据元素是否存在于某个结构中。
由前面分析可知:一个Cache的存储是通过链表来实现,而查找是通过哈希表来实现。

那么在讲查找到的这个结点删除时操作应该如下图,通过图中的操作也保证了Cache的内存大小保持不变。
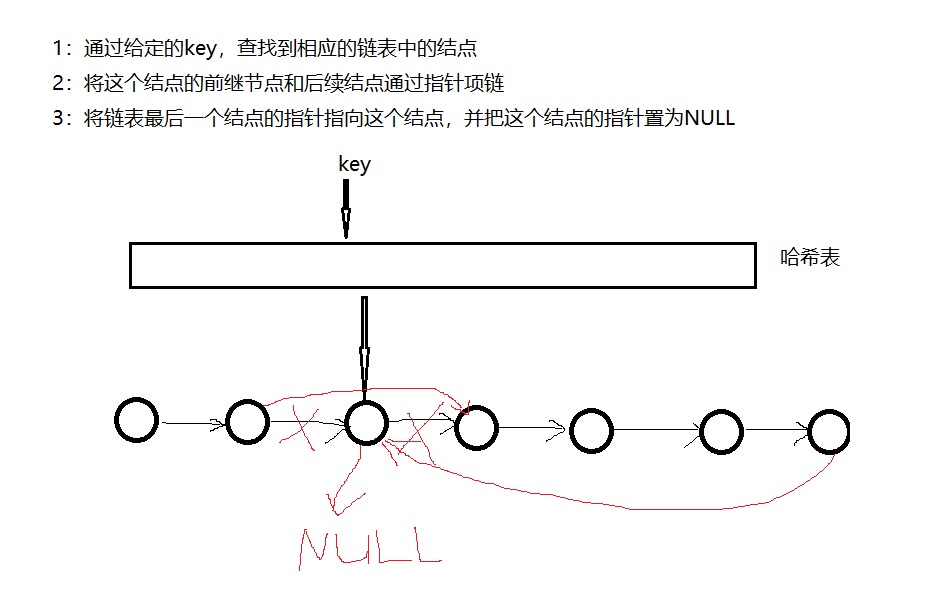
在上述操作中,我们需要知道相应结点的前继节点,这就需要双向链表来实现这个操作。
但是通过双向链表来实现这个操作未免太过复杂,因为要涉及的节点数太多。
那么使用单向链表是否可以呢?答案是可以的,不过需要一个小技巧:就是在Hash中存储的是单向链表中相应结点的前一个结点而不是直接对应的结点,这样既可以通过前继节点访问自己,也访问到了前继节点,如Linked List = dummy ->1 ->2 -> null时,hash[1] = dummy, hash[2] = node1
LinkedHashMap = DoublyLinkedList + HashMap
HashMap<key, DoublyListNode> DoublyListNode{
prev, next, key, value;
}
堆(Heap)
支持操作:O(logN) Add / O(logN) Remove / O(1) Min or Max
堆在定义的时候就必须明确定义是最大堆和最小堆。
丑数的求解
这样的算法要去记忆,一般情况下是自己构建不出来的。