随堂作业
没空了该锁门了,明天再写
效果展示
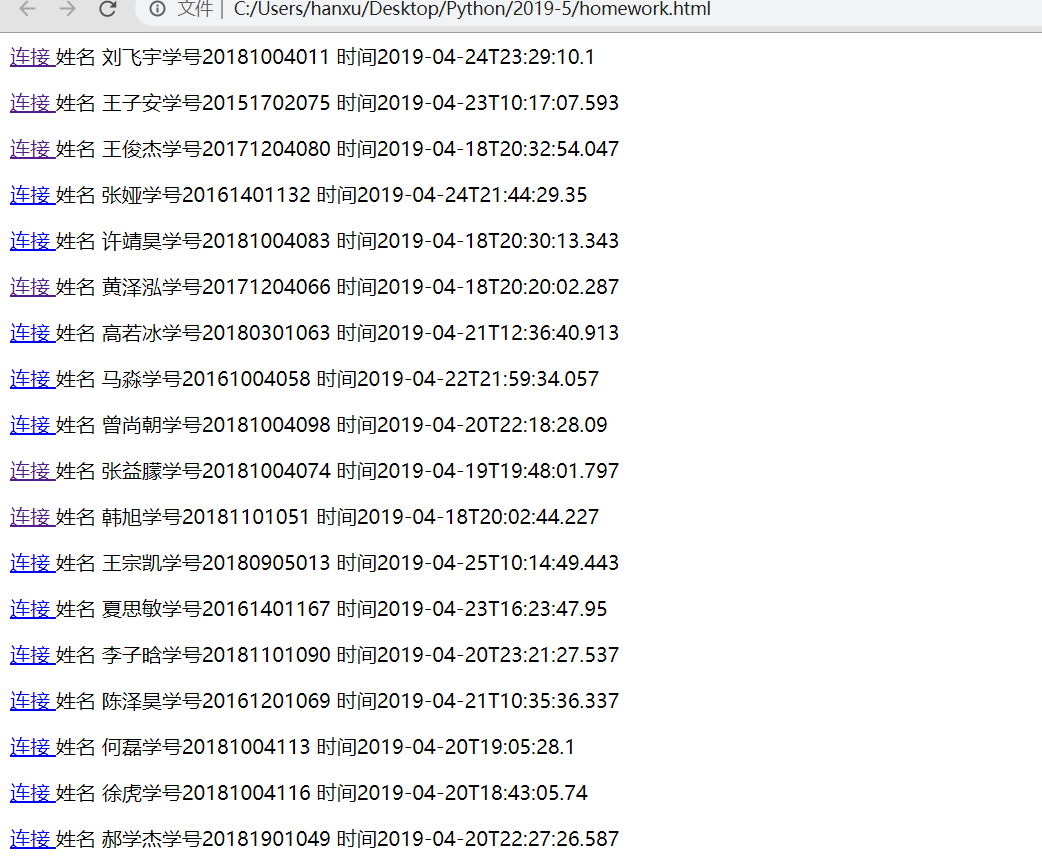
代码展示
1 import requests 2 import json 3 url = 'https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=3103&_=1557235742010' 4 try: 5 r = requests.get(url,timeout=20) 6 r.raise_for_status() 7 r.encoding = r.apparent_encoding 8 except: 9 print('网络异常或页面未找到,请重试') 10 f=open('homework.html','w') 11 l=json.loads(r.text) 12 header=''' 13 <html> 14 <head> 15 <title>爬虫作业</title></head> 16 <body> 17 ''' 18 footer=''' 19 20 </body> 21 </html> 22 ''' 23 body='' 24 for i in l["data"]: 25 body=body+("<p><a href="{}"target="_blank" >连接 </a>姓名 {}学号{} 时间{}</p>".format(i['Url'],i['RealName'],i['StudentNo'],i['DateAdded'])) 26 print ("<p>连接 {}姓名 {}学号{} 时间{}</p>".format(i['Url'],i['RealName'],i['StudentNo'],i['DateAdded'])) 27 s=header+body+footer 28 f.write(s) 29 f.close()