Apache POI 项目的使命是创造和维护 Java API 操纵各种格式的文件,其中包括基于 Office Open XML 标准(OOXML)和微软的 OLE 2 Compound Document 格式(OLE2)。
总之,你可以使用 Java 读写 MS Excel 文件。换句话说就是如果你希望要对 Microsoft Office 的一些文档用 Java 来处理,那么你需要使用 Apache POI 项目。
我们在这里只对 Excel 的读取进行一些小的代码。
HSSF 和 XSSF
HSSF 被用来处理早期版本,这个版本为:Excel '97(-2007)
XSSF 被用来处理近期的版本,Excel 2007 OOXML (.xlsx) 。
简单来说就是你的 Excel 版本为 07 年以后的版本,使用 XSSF 就可以了,换句话说目前使用 XSSF 比较多。
XSSF 读取数据
使用 XSSF 读取数据的方法比较简单。
使用下面几行代码就可以了。
try (InputStream inp = new FileInputStream("workbook.xls")) {
//InputStream inp = new FileInputStream("workbook.xlsx");
Workbook wb = WorkbookFactory.create(inp);
Sheet sheet = wb.getSheetAt(0);
Row row = sheet.getRow(2);
Cell cell = row.getCell(3);
}
简单来说就是首先将文件读取为 InputStream 。
使用 InputStream 来创建一个 Workbook 对象,这时候你需要使用 WorkbookFactory 来创建。

当你获得 WorkbookFactory 对象后,就等于已经将需要读取的 Excel 文件放到对象中了。
读取顺序是从 Workbook 对象中,通过 getSheetAt 方法来处理你希望处理的 sheet,因为在 Excel 表中可以有多个 sheet,这里如果你指定为 0 的话,表示根据物理和逻辑算法确定的第一个 sheet。
当你获得 sheet 对象后,你就可以从 sheet 中读取 row 对象了。
row 对象就等于表格中的一行,在一个 Excel 表中可以有很多行。当你获得这一行的对象后,你会有很多的列。
那么你需要使用 getCell 来获得指定的列。
当你获得指定的列以后,你就可以获得你需要的数据了。
整体来说,Workbook 的对象定义还是非常明确的。
遍历数据
官方的文档中,使用了 3 for 循环来遍历。
代码如下:
for (Sheet sheet : wb ) {
for (Row row : sheet) {
for (Cell cell : row) {
// Do something here
}
}
}
这个代码看起来还是挺丑的,按照官方的说法,还是可以使用迭代( Iterator)的
因为官方还提供了 workbook.sheetIterator() , sheet.rowIterator() , 和 row.cellIterator() 几个迭代器。
例如我们使用了下面这个方法:
public static List<String> getXLSXInputFileRowList(File inputFile) {
List<String> dataList = Lists.newArrayList();
try {
FileInputStream inputStream = FileUtils.openInputStream(inputFile);
Workbook wb = WorkbookFactory.create(inputStream);
Sheet sheet = wb.getSheetAt(0);
Iterator<Row> iterator = sheet.rowIterator();
// LOOP Get Cell
while (iterator.hasNext()) {
Row row = iterator.next();
Cell cell = row.getCell(0);
cell.getStringCellValue();
dataList.add(cell.getStringCellValue());
logger.debug("Cell Data - [{}]", cell.getStringCellValue());
}
logger.debug("The Size of XLSX file count: {}", dataList.size());
} catch (IOException ex) {
logger.error("XLSX File process error.", ex);
}
// CLEAN
CollectionUtils.filter(dataList, PredicateUtils.notNullPredicate());
return dataList;
}
在这个方法中我们就使用了 rowIterator 迭代器。
假设我们处理的 Excel 数据只有 1 列,我们希望读取出来。
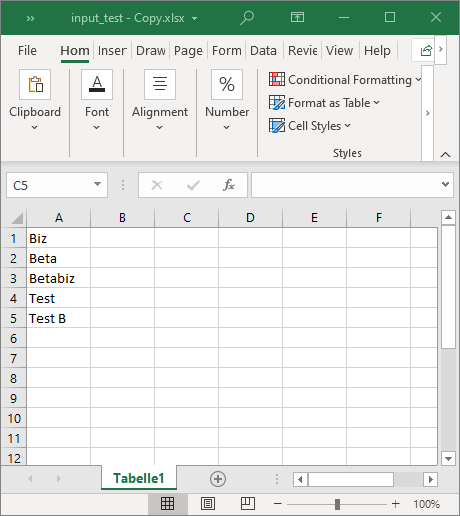
如果执行上面的代码,你的控制台会输出:
18:42:38.094 [main] DEBUG c.i.s.common.utilities.CSVFileUtils - Cell Data - [Biz]
18:42:38.097 [main] DEBUG c.i.s.common.utilities.CSVFileUtils - Cell Data - [Beta]
18:42:38.098 [main] DEBUG c.i.s.common.utilities.CSVFileUtils - Cell Data - [Betabiz]
18:42:38.098 [main] DEBUG c.i.s.common.utilities.CSVFileUtils - Cell Data - [Test]
18:42:38.098 [main] DEBUG c.i.s.common.utilities.CSVFileUtils - Cell Data - [Test B]
18:42:38.098 [main] DEBUG c.i.s.common.utilities.CSVFileUtils - The Size of XLSX file count: 5
18:42:38.101 [main] DEBUG c.i.s.c.test.utilities.FileUtilsTest - Vendor Name List - [5]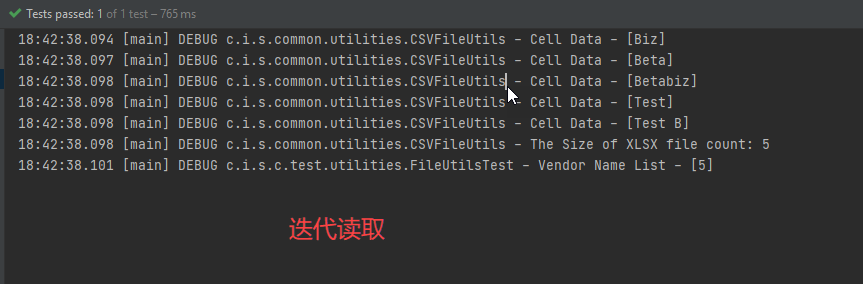
输出的内容就是使用迭代器读取的。
这个针对 3 个 for 循环来说要好一些。
https://www.ossez.com/t/apache-poi-microsoft-office-excel/751