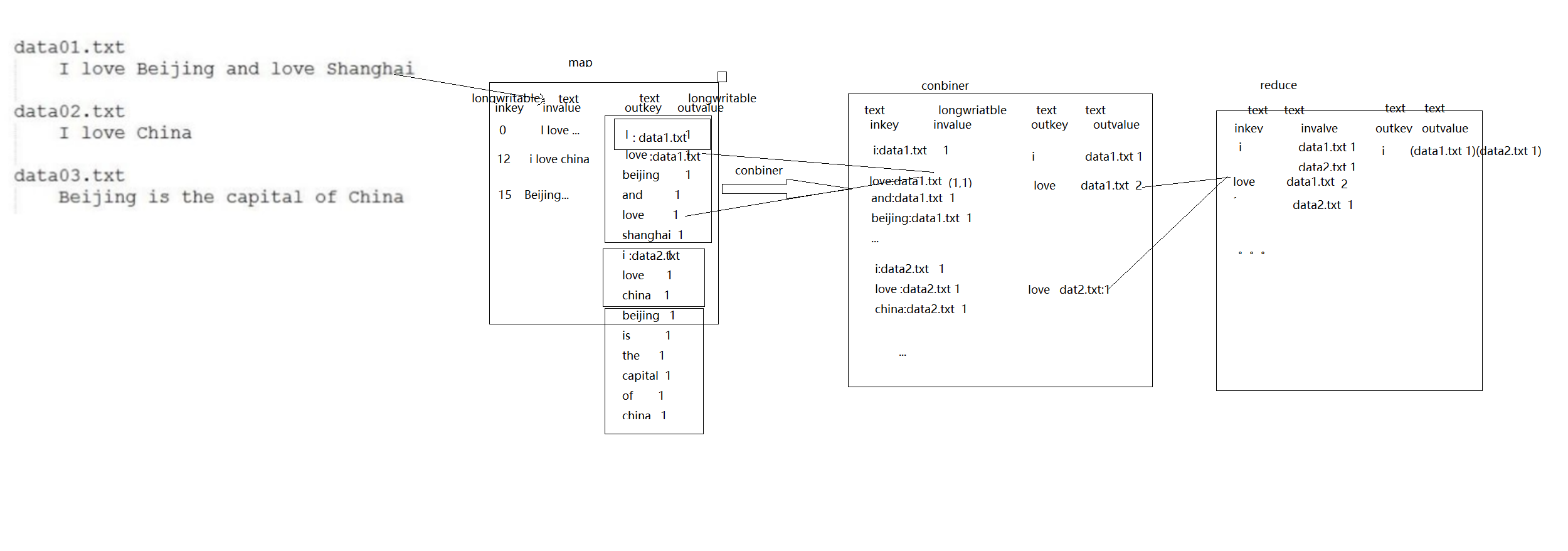
倒排索引流程图:(有三个文件,里边有三句话,分别统计每个单词在每个文件中出现的次数)
package com.young;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class App
{
public static class MyMap extends Mapper<LongWritable,Text,Text,IntWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();//按行读取文件
String[] fields = StringUtils.split(line," ");//按空格进行分片
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String fileName = fileSplit.getPath().getName();//获取文件名
for(String field:fields)
{
context.write(new Text(field+"-->" + fileName),new IntWritable(1));
}
}
}
public static class MyReduce extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable value:values)
{
sum+=value.get();//统计每个key值对应的value值
}
context.write(key,new IntWritable(sum));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.131.142:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(App.class);
job.setMapperClass(MyMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MyReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path("/idea/a.txt"));//读取HDFS上idea目录下的a.txt文件
FileInputFormat.addInputPath(job,new Path("/idea/b.txt"));
FileInputFormat.addInputPath(job,new Path("/idea/c.txt"));
FileOutputFormat.setOutputPath(job,new Path("/idea/out3"));//将结果保存在idea目录下的out3目录下
job.waitForCompletion(true);
}
}