摘要
前面我们已经解释获取和更新metadata以及重要性,那么如何给topic 发送数据?
kafkaclient和broker通信,有很多种情况,核心的broker提供的接口有6个
元数据接口(Metadata API),生产消息接口(Produce API),获取消息接口(Fetch API)
偏移量接口(Offset API),偏移量提交接口(Offset Commit API),偏移量获取接口(Offset Fetch API)
如何发送数据,只要研究一下生产消息接口就有一个简单了解啦,贴一下,JSON版本的API,方便理解(根据源码改的,实际请求API非JSON这种序列化方式,而是自定义的序列化的方式)

1,从上面可以看出kafka-client,每次发送消息的时候,不是一条一条发,而是有一个集合这种概念,kafka-client 将同一个topic的partition下的请求,都放到一起,构成messageSet
2,然后按照topic分组,批量发送消息
结合着kafka 消息模型(V0 版本)或许大家理解起来上面的json api,更容易
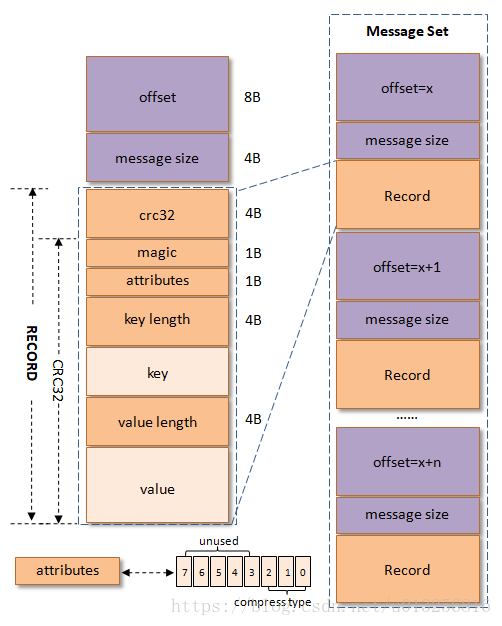
crc32(4B):crc32校验值。校验范围为magic至value之间。
magic(1B):消息格式版本号,此版本的magic值为0。
attributes(1B):消息的属性。总共占1个字节,低3位表示压缩类型:
key length(4B):表示消息的key的长度。如果为-1,则表示没有设置key,即key=null。
key:可选,如果没有key则无此字段。
value length(4B):实际消息体的长度。如果为-1,则表示消息为空。
value:消息体。可以为空,比如tomnstone消息。
具体实现
1,内存分配
kafka-client 不能无限制使用虚拟机内存,JVM还有其他线程需要内存,kafka-client可以使用的内存上限多少?,消息内存如何分配。
参考kafka-client 内存分配和管理 https://www.cnblogs.com/huxuhong/p/13651696.html
2,消息存储
kafka 支持海量数据发送,如果JVM内存存储这一块如果不够优秀,根本无法支持这么庞大的QPS。
参考 kafka-client 消息存储分析 https://www.cnblogs.com/huxuhong/p/13821491.html
3,消息序列化及发送